本文还有配套的精品资源,点击获取 
简介:智能脸部识别系统是一种基于计算机视觉与深度学习的身份认证技术,广泛应用于电脑解锁、权限控制等安全场景。本系统通过摄像头采集人脸图像,提取面部特征并与模板进行比对,实现快速准确的身份识别。项目包含完整的安装文件、配置说明和使用指南,适用于Windows平台,并涉及相机权限管理、人脸识别算法实现及安全防护策略,帮助用户全面掌握人脸识别技术的应用与部署。
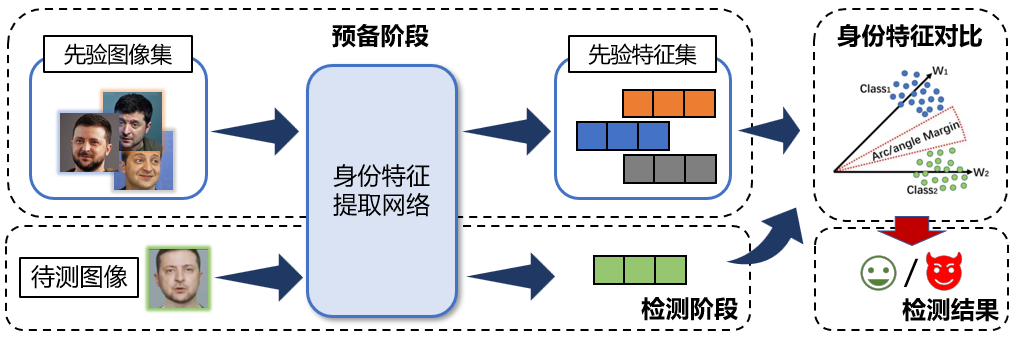
生物特征识别技术是基于个体固有的生理或行为特征进行身份鉴别的技术手段,广泛应用于安防、金融、智能设备等领域。常见的生物特征包括指纹、虹膜、语音和人脸等,它们具有唯一性、稳定性和可采集性等优点。其中,人脸识别因其非接触性、易用性和可扩展性,近年来成为研究与应用的热点。本章将系统介绍各类生物特征识别技术的基本原理、技术特点及其在身份验证中的优势与局限,重点阐述人脸识别技术的发展历程与典型应用场景,为后续章节的技术实现与系统部署打下坚实基础。
计算机视觉作为人工智能领域的重要分支,其在人脸识别中的应用已经从早期的图像处理发展为高度智能化的特征提取与识别流程。本章将围绕人脸识别中的核心环节展开,包括图像采集、预处理、人脸检测、定位、增强与质量评估等关键技术,重点探讨这些环节如何协同工作,确保识别系统的高效与准确。
人脸识别的第一步是获取人脸图像。图像质量直接影响后续处理的准确性,因此图像采集和预处理是整个流程的基础环节。
2.1.1 人脸图像获取设备与环境要求
目前,人脸图像的采集设备主要包括摄像头(如普通摄像头、红外摄像头、3D结构光摄像头等)、手机前置摄像头、监控摄像头等。不同设备在分辨率、光照敏感度、色彩还原等方面存在差异,因此在系统设计时应根据应用场景选择合适的硬件。
在环境方面,图像采集应避免过强或过弱的光照、反光、遮挡等不利因素。此外,背景复杂、多人重叠也会影响检测精度。
2.1.2 图像灰度化、直方图均衡化与归一化处理
图像预处理包括灰度化、直方图均衡化和归一化等操作,其目标是提升图像质量、减少噪声、增强对比度,从而提高识别准确率。
import cv2
import numpy as np
# 加载图像
img = cv2.imread('face.jpg')
# 灰度化
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 直方图均衡化(提升对比度)
equalized_img = cv2.equalizeHist(gray_img)
# 归一化(将像素值归一到[0,1]区间)
normalized_img = equalized_img / 255.0
# 显示图像
cv2.imshow('Normalized Image', normalized_img)
cv2.waitKey(0)
代码逐行分析:
-
cv2.imread('face.jpg'):读取原始彩色图像。 -
cv2.cvtColor(..., cv2.COLOR_BGR2GRAY):将图像从BGR格式转换为灰度图,减少数据维度。 -
cv2.equalizeHist(...):对灰度图像进行直方图均衡化,增强图像的对比度。 -
equalized_img / 255.0:将像素值标准化到0~1之间,便于后续神经网络处理。
流程图说明:
下图展示了图像采集与预处理的流程。
graph TD
A[原始彩色图像] --> B[灰度化]
B --> C[直方图均衡化]
C --> D[图像归一化]
D --> E[预处理完成图像]
人脸检测是识别系统中最为关键的一步,其目的是从图像中找出人脸区域并进行定位。常用方法包括传统方法如Viola-Jones算法和基于深度学习的模型如MTCNN。
2.2.1 Viola-Jones人脸检测算法
Viola-Jones算法是早期广泛应用于人脸检测的经典方法,其核心思想是使用Haar特征和Adaboost分类器进行快速检测。
算法流程如下:
- Haar特征提取 :通过不同窗口形状提取图像中的边缘、线段等特征。
- 积分图像计算 :用于快速计算Haar特征值。
- Adaboost分类器训练 :选出最具判别力的特征组合。
- 级联分类器 :通过多级分类器逐步过滤非人脸区域,提高检测效率。
# 使用OpenCV实现Viola-Jones人脸检测
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
img = cv2.imread('group.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w, y+h), (255,0,0), 2)
cv2.imshow('Face Detection', img)
cv2.waitKey(0)
代码说明:
-
detectMultiScale(...):用于检测多尺度人脸区域。 - 参数
1.3表示每次图像缩放比例,5表示检测框保留阈值。 - 返回的
(x,y,w,h)是检测到的人脸区域坐标和大小。
优点 :速度快,适合嵌入式设备。
缺点 :在复杂背景或部分遮挡情况下效果较差。
2.2.2 基于深度学习的人脸检测模型(如MTCNN)
MTCNN(Multi-task Cascaded Convolutional Networks)是一种基于CNN的多任务级联人脸检测模型,能够同时完成人脸检测与关键点定位。
MTCNN由三级网络组成:
- P-Net:初步检测候选区域。
- R-Net:筛选候选区域并进行粗略定位。
- O-Net:最终输出人脸边界框与关键点。
from mtcnn import MTCNN
import cv2
detector = MTCNN()
img = cv2.imread('face.jpg')
result = detector.detect_faces(img)
for face in result:
bounding_box = face['box']
keypoints = face['keypoints']
cv2.rectangle(img,
(bounding_box[0], bounding_box[1]),
(bounding_box[0]+bounding_box[2], bounding_box[1] + bounding_box[3]),
(0, 155, 255), 2)
# 绘制关键点
for key in keypoints.values():
cv2.circle(img, key, 2, (0, 255, 0), -1)
cv2.imshow('MTCNN Detection', img)
cv2.waitKey(0)
代码说明:
-
MTCNN():初始化MTCNN检测器。 -
detect_faces(...):返回人脸框和关键点。 - 绘制矩形框和关键点位置,便于可视化。
优点 :精度高、支持多角度检测与关键点定位。
缺点 :计算资源消耗较大,适合GPU加速环境。流程图展示:
graph LR
A[输入图像] --> B[P-Net初步检测]
B --> C[R-Net筛选与粗定位]
C --> D[O-Net最终检测与关键点输出]
在实际应用中,由于光照、角度、遮挡等因素,图像质量可能较差,影响识别效果。因此,图像增强与质量评估技术成为提升系统鲁棒性的关键环节。
2.3.1 光照变化对识别效果的影响
光照不均匀会导致图像中人脸区域的亮度差异过大,影响特征提取。常见的增强方法包括Gamma校正、CLAHE(限制对比度自适应直方图均衡)等。
# 使用CLAHE增强图像
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
cl1 = clahe.apply(gray_img)
参数说明:
-
clipLimit=2.0:控制对比度增强的上限,防止噪声放大。 -
tileGridSize=(8,8):图像被分割成8×8的小块进行局部增强。
2.3.2 图像清晰度与角度校正策略
图像模糊或倾斜会影响关键点检测精度。可采用图像锐化、仿射变换等方法进行校正。
# 图像锐化
kernel_sharpen = np.array([[-1,-1,-1],
[-1, 9,-1],
[-1,-1,-1]])
sharpened = cv2.filter2D(cl1, -1, kernel_sharpen)
# 仿射变换校正
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1, pts2)
corrected = cv2.warpAffine(sharpened, M, (300,300))
参数说明:
-
kernel_sharpen:锐化核,增强图像边缘。 -
cv2.getAffineTransform(...):根据三点计算仿射变换矩阵。 -
cv2.warpAffine(...):执行仿射变换,进行角度校正。
2.3.3 图像质量评分模型的设计与实现
为了自动评估图像质量,可以构建一个简单的评分模型,结合清晰度、亮度、对比度等指标。
def image_quality_score(img):
# 清晰度评分(拉普拉斯算子方差)
clarity = cv2.Laplacian(img, cv2.CV_64F).var()
# 亮度评分(平均像素值)
brightness = np.mean(img)
# 对比度评分(标准差)
contrast = np.std(img)
# 综合评分(加权)
score = 0.4 * clarity + 0.3 * brightness + 0.3 * contrast
return score
score = image_quality_score(corrected)
print(f"图像质量评分: {score:.2f}")
参数说明:
-
cv2.Laplacian(...).var():拉普拉斯算子用于检测边缘,方差越大表示图像越清晰。 -
np.mean(...):反映图像整体亮度。 -
np.std(...):衡量图像对比度。 - 最终评分由三个指标加权得出,权重可根据实际需求调整。
评分模型流程图:
graph LR
A[输入图像] --> B[清晰度评分]
A --> C[亮度评分]
A --> D[对比度评分]
B & C & D --> E[综合评分]
本章深入探讨了计算机视觉在人脸识别中的关键环节,从图像采集与预处理、人脸检测与定位,到图像增强与质量评估,详细展示了每个步骤的技术实现与优化策略。这些技术构成了人脸识别系统的基础,为后续的特征提取与模型训练提供了高质量的输入数据。
深度学习模型,尤其是卷积神经网络(CNN),在人脸识别中的特征提取任务中展现了革命性的能力。与传统方法相比,CNN能够自动从原始像素中提取层次化特征,避免了手动设计特征的繁琐性。本章将深入探讨CNN的基础架构、人脸特征嵌入与编码技术,以及模型训练和优化的策略,帮助读者理解深度学习如何在人脸识别中实现高效、准确的特征表达。
卷积神经网络(Convolutional Neural Network, CNN)是一种专门处理具有网格结构数据(如图像)的深度学习模型。其核心在于卷积层的设计,使得模型能够有效捕捉图像的局部特征,同时通过参数共享和局部连接策略减少模型复杂度。
3.1.1 卷积层、池化层与全连接层的作用
CNN 的基本结构包括卷积层、池化层和全连接层,每一层在特征提取中扮演不同的角色。
卷积层(Convolutional Layer)
卷积层通过滤波器(也称为卷积核)在图像上滑动,提取局部特征。每个滤波器可以检测一种特定的图像特征,如边缘、角点或纹理。多个滤波器堆叠在一起可以提取出更丰富的特征。
示例代码:定义一个简单的卷积层
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
return x
# 创建模型实例
model = SimpleCNN()
print(model)
代码逻辑分析:
-
nn.Conv2d:定义卷积层,输入通道为3(RGB图像),输出通道为16,表示提取16种特征图。 -
kernel_size=3:使用3×3的卷积核。 -
padding=1:保持输出特征图尺寸与输入一致。 -
ReLU:非线性激活函数,引入非线性特征表达。
池化层(Pooling Layer)
池化层用于降低特征图的空间维度,减少计算量,同时增强模型对平移的鲁棒性。常见的是最大池化(Max Pooling)和平均池化(Average Pooling)。
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
全连接层(Fully Connected Layer)
全连接层将卷积和池化后的高维特征向量拉平后,进行最终的分类或特征嵌入。通常位于网络的最后几层。
self.fc1 = nn.Linear(16 * 64 * 64, 10) # 假设输出10个类别
CNN 架构流程图(mermaid)
graph TD
A[Input Image] --> B[Convolutional Layer]
B --> C[Activation (ReLU)]
C --> D[Pooling Layer]
D --> E[Convolutional Layer]
E --> F[Activation (ReLU)]
F --> G[Pooling Layer]
G --> H[Flatten]
H --> I[Fully Connected Layer]
I --> J[Output]
3.1.2 常用CNN模型(如ResNet、VGG、FaceNet)概述
在人脸识别任务中,常用的CNN模型包括:
FaceNet 模型简析
FaceNet 是 Google 提出的一种用于人脸识别的深度模型,其核心在于将人脸图像映射到欧几里得空间中的特征向量,并通过三元组损失函数优化特征向量之间的距离。
import facenet_python as InceptionResNetV1
# 加载预训练的FaceNet模型
model = InceptionResNetV1(pretrained='vggface2').eval()
参数说明:
-
pretrained='vggface2':表示使用 VGGFace2 数据集预训练的模型。 -
eval():设置模型为评估模式,关闭 dropout 和 batch normalization 的训练状态。
FaceNet 的输出是一个 512 维的特征向量,可用于人脸匹配和检索。
在人脸识别系统中,特征嵌入(Feature Embedding)是将人脸图像转换为一个固定维度的向量,以便进行后续的相似度比较和分类。
3.2.1 特征向量的生成与存储方式
特征向量通常是通过深度神经网络最后一层全连接层之前提取的高维向量。以 FaceNet 为例,输出是一个 512 维的浮点向量。
示例:提取人脸特征向量
from facenet_python import InceptionResNetV1
from PIL import Image
import torchvision.transforms as transforms
# 加载预训练模型
model = InceptionResNetV1(pretrained='vggface2').eval()
# 图像预处理
img = Image.open('face.jpg')
transform = transforms.Compose([
transforms.Resize((160, 160)),
transforms.ToTensor()
])
img_tensor = transform(img).unsqueeze(0) # 增加 batch 维度
# 提取特征向量
with torch.no_grad():
embedding = model(img_tensor).numpy()
print("Feature Vector Shape:", embedding.shape) # 输出:(1, 512)
代码逻辑分析:
-
transforms.Resize((160, 160)):FaceNet 输入要求为 160×160 的图像。 -
unsqueeze(0):增加 batch 维度以适配模型输入。 -
model(img_tensor):输出一个 512 维的特征向量。 -
numpy():将 PyTorch 张量转换为 NumPy 数组便于后续处理。
特征向量存储方式:
- 数据库存储 :可使用 MySQL、MongoDB 等数据库,将每个人脸的特征向量存储为 blob 或 float 数组。
- 文件存储 :使用
.npy文件格式保存 NumPy 数组,便于快速读取。
3.2.2 高维空间中的人脸特征匹配策略
在高维空间中,人脸特征匹配主要依赖于向量之间的相似度计算,常见方法包括:
示例:使用余弦相似度比较两个特征向量
from sklearn.metrics.pairwise import cosine_similarity
vec1 = embedding1.reshape(1, -1)
vec2 = embedding2.reshape(1, -1)
similarity = cosine_similarity(vec1, vec2)
print("Cosine Similarity:", similarity[0][0])
结果分析:
- 若
similarity > 0.7,通常认为是同一个人。 - 若
similarity < 0.5,则可能不是同一个人。
深度学习模型的性能不仅依赖于网络结构,还取决于训练策略和优化手段。本节将介绍数据集构建、迁移学习与微调策略,以及推理效率与精度的平衡优化。
3.3.1 数据集构建与增强方法
一个高质量的人脸数据集是训练模型的基础。构建数据集时应考虑以下因素:
- 多样性 :包含不同年龄、性别、种族、光照、角度的人脸。
- 标注质量 :每张图像需标注对应身份标签。
- 数据清洗 :去除模糊、遮挡、低质量图像。
数据增强方法:
示例:使用 PyTorch 进行数据增强
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor(),
])
3.3.2 模型迁移学习与微调策略
迁移学习是一种高效的训练策略,即使用在大规模数据集上预训练的模型,并在其基础上微调以适应特定任务。
微调步骤:
- 加载预训练模型(如 ResNet50)。
- 替换最后的全连接层,适配当前任务类别数。
- 冻结部分层(如前面的卷积层),仅训练最后几层。
- 解冻所有层,进行微调。
示例代码:微调 ResNet50
import torchvision.models as models
# 加载预训练模型
model = models.resnet50(pretrained=True)
# 替换最后的全连接层
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 100) # 假设当前任务有100个人
# 冻结前面的层
for param in model.parameters():
param.requires_grad = False
# 仅训练最后一层
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)
3.3.3 模型推理效率与精度的平衡优化
在实际部署中,模型推理速度和精度之间往往需要权衡。以下是常见的优化策略:
示例:使用 PyTorch 进行模型量化
import torch.quantization
# 设置模型为量化模式
model.eval()
model_quantized = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
量化优势:
- 模型体积减少 4 倍。
- 推理速度提升 2~3 倍。
- 在移动设备或嵌入式设备上更易部署。
本章系统性地介绍了深度学习模型在人脸识别特征提取中的应用,从 CNN 的基本结构到特征嵌入、再到模型训练与优化,涵盖了理论基础与实践技巧。下一章将进入系统部署阶段,介绍人脸识别系统的软硬件搭建与集成测试流程。
在人脸识别技术日益成熟并广泛应用于安防、金融、教育、医疗等领域的背景下,系统的安装与部署环节显得尤为重要。一个高效、稳定、可扩展的人脸识别系统不仅依赖于算法模型的性能,更依赖于整体系统架构的设计与部署流程的合理性。本章将从系统架构设计、软件环境搭建到系统集成测试,全面解析人脸识别系统的安装与部署流程,涵盖硬件选型、软件配置、环境优化及实际场景下的部署策略。
人脸识别系统的架构设计直接影响其性能、扩展性与维护成本。在部署前,必须根据实际业务需求,合理选择硬件平台与软件组件,确保系统具备高并发、低延迟、高准确率的识别能力。
4.1.1 硬件平台与操作系统要求
人脸识别系统通常部署在以下几种硬件平台上:
操作系统方面,Linux 系统因其开源性、稳定性及对 GPU 支持良好,成为主流选择。常见的有:
- Ubuntu :广泛使用,社区活跃,适合部署深度学习框架。
- CentOS :稳定性强,适合企业级服务器。
- Jetson Linux :专为 NVIDIA Jetson 设计,适合边缘计算场景。
4.1.2 开源框架(如OpenCV、Dlib、DeepFace)对比与选型
目前主流的人脸识别开源框架有 OpenCV、Dlib、DeepFace、FaceNet、MTCNN 等。它们在功能、性能和适用性上各有侧重。
在选型过程中,需结合项目需求与硬件资源进行权衡。例如,若需部署于边缘设备,建议选择轻量级模型如 MTCNN + OpenCV;如需高精度识别,建议使用 FaceNet + GPU 服务器。
graph TD
A[系统需求分析] --> B[硬件平台选型]
A --> C[软件框架选型]
B --> D[边缘设备]
B --> E[服务器集群]
C --> F[OpenCV]
C --> G[Dlib]
C --> H[FaceNet]
C --> I[MTCNN]
C --> J[DeepFace]
D --> K[OpenCV + MTCNN]
E --> L[FaceNet + TensorFlow]
F --> M[人脸检测]
G --> N[人脸对齐]
H --> O[高精度识别]
I --> P[实时检测]
J --> Q[多模型融合]
构建人脸识别系统的关键环节之一是搭建稳定的软件运行环境,包括编程语言、深度学习框架、图像处理库等。本节将介绍基于 Python 的部署环境搭建流程。
4.2.1 Python环境与相关库的安装
Python 是当前最广泛用于深度学习开发的语言之一,其丰富的第三方库支持使人脸识别系统的开发效率大大提高。以下为基本的库安装命令:
# 创建虚拟环境
python3 -m venv face_env
source face_env/bin/activate
# 安装常用库
pip install numpy opencv-python dlib face_recognition tensorflow deepface
各库功能简要说明如下:
- numpy :提供高效的多维数组操作,支持图像矩阵运算。
- opencv-python :提供图像处理接口,支持人脸检测与显示。
- dlib :提供人脸关键点检测与特征提取功能。
- face_recognition :基于 dlib 的封装,简化人脸识别流程。
- tensorflow / pytorch :深度学习框架,用于加载和运行模型。
- deepface :支持多模型(VGG-Face、Facenet、OpenFace 等)的集成库。
4.2.2 GPU加速支持与部署优化
在服务器或高性能设备上,启用 GPU 加速可显著提升模型推理速度。以 TensorFlow 为例,配置 GPU 支持的步骤如下:
-
安装 CUDA Toolkit 和 cuDNN:
– CUDA 版本需与 TensorFlow 版本兼容(如 TF 2.10 支持 CUDA 11.2)。
– 下载 cuDNN 并解压至/usr/local/cuda目录。 -
安装 GPU 版本的 TensorFlow:
pip install tensorflow-gpu
- 验证 GPU 是否可用:
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
若输出大于 0,则表示 GPU 环境配置成功。
此外,还可以通过以下方式优化部署性能:
- 模型量化 :将浮点模型转换为整型模型,减小模型体积。
- 模型剪枝 :移除冗余神经元,提升推理速度。
- 使用 ONNX Runtime :支持多平台加速推理。
- 多线程处理 :利用多核 CPU 并行处理多个图像。
完成软硬件环境配置后,进入系统集成与测试阶段。此阶段的目标是确保各模块功能正常,接口调用稳定,系统在实际场景中表现良好。
4.3.1 模块功能测试与接口联调
系统通常由多个模块组成,包括:
- 图像采集模块 :负责视频流或图像的读取。
- 人脸检测模块 :使用 MTCNN 或 OpenCV 进行人脸定位。
- 特征提取模块 :使用 FaceNet 或 Dlib 提取人脸特征。
- 特征比对模块 :将提取特征与数据库中特征进行匹配。
- 用户界面模块 :提供图形化界面或 API 接口。
各模块需进行单元测试,确保功能独立可用。例如,测试人脸检测模块的代码如下:
import cv2
import face_recognition
# 加载图像
image = face_recognition.load_image_file("test.jpg")
# 检测人脸
face_locations = face_recognition.face_locations(image)
# 显示检测结果
for top, right, bottom, left in face_locations:
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.imshow("Detected Faces", image)
cv2.waitKey(0)
代码分析 :
-
face_recognition.load_image_file:加载图像文件为 NumPy 数组。 -
face_recognition.face_locations:返回人脸在图像中的位置坐标。 -
cv2.rectangle:在图像上绘制矩形框标记人脸区域。 -
cv2.imshow:显示处理后的图像。
4.3.2 实际场景下的性能验证与调优
部署前需在真实环境中测试系统性能,重点关注以下指标:
time 模块记录执行时间 htop 、 nvidia-smi 等工具监控 例如,测试响应时间的代码如下:
import time
start_time = time.time()
face_locations = face_recognition.face_locations(image)
end_time = time.time()
print(f"Detection time: {end_time - start_time:.4f} seconds")
4.3.3 系统部署文档与用户操作手册编写
系统部署完成后,必须编写详细的部署文档与用户操作手册,确保后续维护和升级的便利性。文档内容应包括:
- 系统架构图 :展示模块组成与数据流向。
- 安装步骤 :包括依赖安装、模型加载、服务启动等。
- 配置参数说明 :如阈值设置、识别模式切换等。
- 常见问题与解决方法 :如识别失败、性能下降等问题的排查。
- 日志与错误码说明 :便于运维人员快速定位问题。
以下为部署文档的示例结构:
# 人脸识别系统部署手册
## 1. 系统要求
- 操作系统:Ubuntu 20.04 LTS
- Python 版本:3.8+
- GPU:NVIDIA Tesla T4 或以上
## 2. 环境搭建
```bash
git clone https://github.com/example/face-recognition.git
cd face-recognition
pip install -r requirements.txt
- 模型文件路径:
models/face_model.pb - 配置文件路径:
config/face_config.json
python app.py --host 0.0.0.0 --port 5000
- POST /recognize
- 参数:
image_url(图片地址) - 返回:
{"name": "John", "confidence": 0.96}
通过以上步骤,可完成一个完整的人脸识别系统的安装与部署。下一章将深入探讨系统在权限管理与数据采集方面的实现策略,进一步提升系统的安全性与合规性。
# 5. 人脸识别系统的权限管理与数据采集
在现代人脸识别系统中,权限管理与数据采集是保障系统安全与合规性的核心环节。随着人脸识别技术在金融、安防、政务等领域的广泛应用,如何确保用户身份数据的安全性、访问控制的严谨性,以及数据采集过程的合法性,成为系统设计中不可忽视的问题。本章将从用户身份生命周期管理、权限控制机制、数据采集流程设计,以及隐私保护合规性四个方面,系统性地分析人脸识别系统在权限与数据管理中的关键实现方式与技术细节。
## 5.1 用户身份的注册、更新与注销流程
在人脸识别系统中,用户身份的注册、更新与注销构成了完整的身份生命周期管理流程。这一流程不仅决定了系统的可用性,也直接影响用户数据的安全性和系统权限控制的严谨性。
### 5.1.1 用户注册流程设计
用户注册是系统中首次采集用户生物特征信息(如人脸图像)并建立身份档案的过程。该流程通常包括以下几个步骤:
1. **用户身份验证**:通过身份证、手机号或其他认证方式验证用户真实身份。
2. **人脸图像采集**:使用摄像头或专用设备采集用户正面人脸图像。
3. **图像预处理**:对采集到的图像进行灰度化、直方图均衡化等处理,以提高识别准确率。
4. **特征提取与存储**:利用深度学习模型(如FaceNet)提取人脸特征向量,并将特征值加密后存储至数据库。
以下是一个简单的用户注册代码示例,使用Python与OpenCV库实现基本的人脸图像采集与特征提取:
```python
import cv2
import face_recognition
def register_user(user_id):
video_capture = cv2.VideoCapture(0)
print("请正视摄像头进行注册...")
while True:
ret, frame = video_capture.read()
rgb_frame = frame[:, :, ::-1] # 转换为RGB格式
face_locations = face_recognition.face_locations(rgb_frame)
if len(face_locations) == 1:
face_encoding = face_recognition.face_encodings(rgb_frame, face_locations)[0]
# 保存特征向量至数据库(示例:本地存储)
import numpy as np
np.save(f"faces/{user_id}.npy", face_encoding)
print("注册成功!")
break
elif len(face_locations) > 1:
print("检测到多人,请保持画面中仅一人。")
else:
print("未检测到人脸,请靠近摄像头。")
video_capture.release()
# 调用注册函数
register_user("user_001")
代码逻辑分析:
-
cv2.VideoCapture(0):调用默认摄像头设备。 -
face_recognition.face_locations():检测图像中人脸位置。 -
face_recognition.face_encodings():提取人脸特征向量。 -
np.save():将特征向量保存为本地文件,模拟数据库存储。
参数说明:
user_id是用户唯一标识符,用于关联数据库中用户信息。
5.1.2 用户信息更新与注销机制
用户信息更新通常包括重新采集人脸图像、更新特征向量或修改用户权限等级。而用户注销则涉及从系统中删除所有相关生物特征数据,确保数据不可恢复。
- 更新流程 :
- 用户通过身份验证后进入更新界面。
- 重新采集人脸图像并提取特征。
-
替换旧有特征向量或新增特征模板。
-
注销流程 :
- 系统根据用户ID删除其特征向量文件。
- 同步删除用户在数据库中的所有身份记录。
- 日志记录操作人与操作时间,确保可审计。
为了防止未经授权的访问与数据泄露,构建安全的用户数据库并实现多级权限控制至关重要。
5.2.1 数据库结构设计
一个典型的人脸识别系统数据库结构如下表所示:
说明:
face_encoding字段使用加密方式存储,避免原始特征泄露。
5.2.2 多级权限控制实现
多级权限控制可通过角色-权限模型(RBAC)实现,常见角色包括管理员、操作员、访客等。每种角色拥有不同的访问权限。
- 管理员(Admin) :可注册/注销用户、修改权限、查看日志。
- 操作员(Operator) :可进行识别操作,但不能修改系统配置。
- 访客(Guest) :仅可查看部分信息,无操作权限。
以下是一个基于Flask框架实现权限控制的示例代码:
from flask import Flask, request
from functools import wraps
app = Flask(__name__)
# 模拟用户数据库
users_db = {
"admin": {"password": "secure123", "role": "admin"},
"user": {"password": "123456", "role": "user"}
}
# 权限装饰器
def require_role(role):
def wrapper(func):
@wraps(func)
def decorated(*args, **kwargs):
username = request.form.get("username")
password = request.form.get("password")
user = users_db.get(username)
if user and user["password"] == password and user["role"] == role:
return func(*args, **kwargs)
return "权限不足或身份验证失败", 403
return decorated
return wrapper
@app.route("/register", methods=["POST"])
@require_role("admin")
def register():
return "注册新用户成功!"
@app.route("/recognize", methods=["POST"])
@require_role("user")
def recognize():
return "人脸识别进行中..."
if __name__ == "__main__":
app.run(debug=True)
代码逻辑分析:
- 使用Flask框架搭建简单的Web接口。
-
require_role装饰器用于验证用户角色权限。 -
/register路由仅允许管理员访问,/recognize允许普通用户访问。
参数说明:
username与password用于身份验证,role字段决定用户权限等级。
5.2.3 安全性与审计机制
- 加密存储 :使用AES等加密算法对人脸特征向量进行加密存储。
- 访问日志 :记录每次用户登录、识别、注册、注销操作的时间、IP地址等信息。
- 审计接口 :提供权限管理操作的审计接口,供管理员审查。
在数据采集过程中,必须严格遵守相关法律法规,尤其是《通用数据保护条例(GDPR)》和《加州消费者隐私法案(CCPA)》等,以确保用户隐私不被侵犯。
5.3.1 合规性要求概述
- 知情同意 :采集用户生物特征数据前,必须明确告知用户数据用途,并获取其书面或电子同意。
- 最小化原则 :仅采集完成识别功能所必需的数据,不收集无关信息。
- 数据保留期限 :设定合理的数据保留周期,到期后自动删除或匿名化处理。
5.3.2 数据采集流程设计
一个合规的数据采集流程应包括以下步骤:
- 用户授权界面 :展示数据使用说明并请求用户授权。
- 数据采集与处理 :采集人脸图像并提取特征。
- 数据加密与存储 :将特征向量加密后存入数据库。
- 数据使用记录 :记录数据使用情况,供审计使用。
5.3.3 用户数据匿名化与加密技术
- 匿名化处理 :在非必要场景中,使用特征向量替代原始人脸图像,避免直接识别。
- 加密技术 :采用AES、RSA等加密算法保护特征数据在传输与存储过程中的安全。
以下是使用Python进行AES加密的示例代码:
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
import base64
def encrypt_data(key, data):
cipher = AES.new(key, AES.MODE_EAX)
ciphertext, tag = cipher.encrypt_and_digest(data.encode())
return base64.b64encode(cipher.nonce + tag + ciphertext).decode()
def decrypt_data(key, encrypted_data):
data = base64.b64decode(encrypted_data)
nonce, tag, ciphertext = data[:16], data[16:32], data[32:]
cipher = AES.new(key, AES.MODE_EAX, nonce=nonce)
return cipher.decrypt_and_verify(ciphertext, tag).decode()
key = get_random_bytes(16) # 128位密钥
encrypted = encrypt_data(key, "face_encoding_data_123456")
print("加密数据:", encrypted)
decrypted = decrypt_data(key, encrypted)
print("解密数据:", decrypted)
代码逻辑分析:
- 使用
AES.new()创建加密对象。 -
encrypt_and_digest()方法实现加密与完整性校验。 -
decrypt_and_verify()用于安全解密。
参数说明:
key为128位加密密钥,data为待加密的原始数据(如特征向量)。
以下使用Mermaid流程图展示人脸识别系统的权限管理与数据采集流程:
graph TD
A[用户注册] --> B[身份验证]
B --> C[采集人脸图像]
C --> D[特征提取]
D --> E[加密存储至数据库]
F[用户登录] --> G[权限验证]
G --> H{权限等级}
H -->|管理员| I[允许注册/注销]
H -->|普通用户| J[仅允许识别]
K[数据采集] --> L[用户授权]
L --> M[最小化采集]
M --> N[数据加密]
N --> O[记录审计日志]
说明:流程图展示了用户从注册到数据采集再到权限控制的全过程,强调了安全与合规性。
通过上述章节内容,我们系统性地分析了人脸识别系统在权限管理与数据采集方面的关键实现机制。从用户生命周期管理、数据库结构设计,到权限控制、数据加密与合规性要求,每个环节都对系统的安全性与可用性产生深远影响。在下一章中,我们将进一步探讨面部特征提取与模板匹配技术,为系统的识别精度与效率提供理论与实践支持。
面部特征提取与模板匹配技术是人脸识别系统中的核心环节。它决定了识别的准确性和系统的响应速度。本章将深入探讨面部关键点定位、模板匹配策略以及实时识别中的性能优化方法,帮助读者理解如何在复杂场景下实现高精度、低延迟的人脸识别。
面部关键点定位(Facial Landmark Detection)是人脸特征提取的前提,它通过识别面部的特定位置点(如眼睛、鼻子、嘴巴等),为后续的姿态校正、特征提取和模板匹配提供几何支撑。
6.1.1 关键点检测算法(如68点人脸对齐)
目前主流的关键点检测算法包括传统的ASM(Active Shape Model)、AAM(Active Appearance Model)以及基于深度学习的68点人脸对齐模型,例如Dlib中使用的基于回归树的模型。
import dlib
from skimage import io
# 加载预训练的68点人脸关键点检测模型
predictor_path = 'shape_predictor_68_face_landmarks.dat'
face_detector = dlib.get_frontal_face_detector()
landmark_predictor = dlib.shape_predictor(predictor_path)
# 读取图像
img = io.imread('face.jpg')
# 检测人脸
faces = face_detector(img, 1)
# 遍历每个人脸并提取关键点
for face in faces:
shape = landmark_predictor(img, face)
for i in range(68):
x = shape.part(i).x
y = shape.part(i).y
print(f"关键点 {i}: ({x}, {y})")
代码逻辑分析:
-
dlib.get_frontal_face_detector():使用HOG特征和线性分类器检测正面人脸。 -
dlib.shape_predictor():加载预训练的68点关键点检测模型。 -
shape.part(i).x/y:获取第i个关键点的坐标。 - 输出结果为68个面部关键点的坐标信息。
参数说明:
-
predictor_path:指向训练好的关键点检测模型文件。 -
img:输入图像,通常为RGB格式。 -
face_detector(img, 1):第二个参数1表示最多检测1张人脸。
6.1.2 关键点在特征提取中的作用
面部关键点在人脸识别中主要有以下作用:
Mermaid 流程图:关键点在特征提取中的流程
graph TD
A[输入图像] --> B{人脸检测}
B --> C[提取关键点]
C --> D[姿态校正]
D --> E[局部特征提取]
E --> F[全局特征拼接]
F --> G[特征向量输出]
关键点为系统提供几何结构信息,使得特征提取更稳定、更具有可比性。
在完成特征提取后,下一步是进行模板匹配,即计算输入图像与已知模板之间的相似度。这一过程决定了识别系统的匹配精度和响应速度。
6.2.1 欧氏距离与余弦相似度对比
在实际应用中,最常用的相似度计算方法包括欧氏距离(Euclidean Distance)和余弦相似度(Cosine Similarity)。
示例代码:使用余弦相似度进行匹配
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 假设有两个特征向量
feature1 = np.random.rand(128)
feature2 = np.random.rand(128)
similarity = cosine_similarity([feature1], [feature2])
print(f"余弦相似度: {similarity[0][0]:.4f}")
代码分析:
-
np.random.rand(128):生成两个128维的随机特征向量。 -
cosine_similarity:计算两个向量之间的余弦相似度。 - 输出值范围为[-1, 1],值越接近1表示越相似。
6.2.2 多模板匹配与结果融合策略
在实际应用中,一个用户可能拥有多个注册模板(如不同光照、角度下采集的图像)。此时需要采用多模板匹配与结果融合策略。
多模板匹配流程:
graph LR
A[输入图像] --> B[提取特征]
B --> C[匹配多个模板]
C --> D1[模板1]
C --> D2[模板2]
C --> D3[模板3]
D1 --> E[计算相似度1]
D2 --> E[计算相似度2]
D3 --> E[计算相似度3]
E --> F[结果融合]
F --> G[最终匹配结果]
结果融合策略:
- 平均法 :对多个相似度结果取平均。
- 加权平均法 :根据模板质量或采集时间赋予不同权重。
- 最大最小法 :取最大值作为最终匹配得分。
在工业级应用中,实时性是人脸识别系统的关键指标之一。面对海量并发请求和低延迟需求,系统需要在识别精度和响应速度之间找到平衡。
6.3.1 实时检测中的性能瓶颈分析
常见性能瓶颈包括:
6.3.2 缓存机制与快速检索策略设计
为提高实时识别效率,可采用以下策略:
1. 缓存机制
- 将最近匹配结果缓存,避免重复计算。
- 使用LRU(Least Recently Used)策略管理缓存空间。
2. 快速检索策略
- 使用Faiss库构建高效的特征向量索引。
- 支持近似最近邻(ANN)搜索,大幅提高检索速度。
import faiss
import numpy as np
# 构建特征数据库
dimension = 128
num_samples = 1000
db_features = np.random.random((num_samples, dimension)).astype('float32')
# 构建索引
index = faiss.IndexFlatL2(dimension)
index.add(db_features)
# 查询特征
query_feature = np.random.random((1, dimension)).astype('float32')
# 检索最近邻
k = 5
distances, indices = index.search(query_feature, k)
print(f"最近邻索引: {indices}")
print(f"对应距离: {distances}")
代码分析:
-
faiss.IndexFlatL2:使用L2距离构建索引。 -
index.add():将特征数据库添加到索引中。 -
index.search():执行最近邻搜索,返回前k个结果。 -
distances:与匹配特征的距离值。 -
indices:匹配特征在数据库中的索引位置。
3. 系统优化建议
本章深入探讨了人脸识别系统中面部特征提取与模板匹配的核心技术,从关键点定位、相似度计算到实时性能优化,逐步递进地构建了一个完整的识别逻辑框架。下一章将继续探讨人脸识别系统的安全性与防护措施,进一步完善整个技术体系。
人脸识别系统虽然在身份验证领域具备高效性和便捷性,但其安全性问题也不容忽视。随着技术的普及,攻击者也不断探索新的攻击方式,试图绕过系统验证机制。以下是当前主流的几种安全威胁和攻击类型:
7.1.1 照片欺骗、视频回放攻击与3D面具攻击
这些攻击方式统称为 活体伪造攻击(Presentation Attack) ,其核心目标是欺骗系统,使其误认为攻击者是合法用户。
- 照片欺骗 :使用用户的照片替代真实人脸进行识别。尽管现代系统已具备一定的检测能力,但在低分辨率或特定光照条件下仍可能被攻破。
- 视频回放攻击 :播放目标用户的视频,模拟动态人脸行为。攻击者可通过眨眼、点头等动作增强欺骗效果。
- 3D面具攻击 :使用高精度3D打印技术制作人脸模型,配合动作模拟设备进行攻击。此类攻击在高端人脸识别系统中尤其具有威胁性。
7.1.2 模型泄露与反向工程风险
- 模型泄露 :深度学习模型一旦被攻击者获取,可能被用于生成对抗样本或破解特征提取逻辑。
- 反向工程 :攻击者通过输入大量人脸图像并观察输出结果,尝试反向推导出模型的决策逻辑,从而构造对抗样本进行攻击。
- 模型窃取攻击(Model Extraction) :攻击者通过多次调用API接口,逐步还原出模型结构和参数,进而构建克隆模型实施攻击。
为了有效应对上述攻击手段,人脸识别系统必须引入多层次的安全防护机制。
7.2.1 活体检测(Liveness Detection)技术
活体检测是防范活体伪造攻击的核心技术。其主要目标是判断输入图像中的人脸是否来自真实的活体对象,而非照片、视频或面具。
常见活体检测方法包括:
示例代码:基于OpenCV实现简单的眨眼检测(动作指令方式)
import cv2
from scipy.spatial import distance
# 计算眼睛的EAR(Eye Aspect Ratio)
def eye_aspect_ratio(eye):
A = distance.euclidean(eye[1], eye[5])
B = distance.euclidean(eye[2], eye[4])
C = distance.euclidean(eye[0], eye[3])
ear = (A + B) / (2.0 * C)
return ear
# 设置眨眼阈值与连续帧数
EAR_THRESH = 0.25
EAR_CONSEC_FRAMES = 3
# 初始化计数器
COUNTER = 0
TOTAL = 0
# 使用dlib进行人脸关键点检测
detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
landmark_predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
shape = landmark_predictor(gray, dlib.rectangle(x, y, x + w, y + h))
shape = face_utils.shape_to_np(shape)
left_eye = shape[42:48]
right_eye = shape[36:42]
left_ear = eye_aspect_ratio(left_eye)
right_ear = eye_aspect_ratio(right_eye)
ear = (left_ear + right_ear) / 2.0
# 判断是否眨眼
if ear < EAR_THRESH:
COUNTER += 1
else:
if COUNTER >= EAR_CONSEC_FRAMES:
TOTAL += 1
COUNTER = 0
# 在图像上绘制结果
cv2.putText(frame, f"Blinks: {TOTAL}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Blink Detection", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
代码说明:
– 使用dlib进行人脸关键点定位,获取眼睛坐标;
– 计算眼睛的EAR值,判断是否眨眼;
– 通过连续帧数判断是否为真实活体。
7.2.2 加密存储与传输中的安全协议
为了防止模型泄露和数据被窃取,系统应采用以下安全措施:
- 数据加密存储 :对人脸特征模板使用AES或HSM(硬件安全模块)进行加密存储;
- 传输加密 :使用TLS 1.3或更高版本协议进行数据传输,防止中间人攻击;
- 访问控制 :采用OAuth2.0、JWT等机制实现安全的身份认证与访问控制;
- 模型混淆与模糊化 :在部署模型时使用模型混淆工具(如TensorFlow Privacy)或模型加密技术,增加反向工程难度。
7.3.1 GDPR、CCPA等法规对人脸识别的约束
人脸识别系统涉及大量个人生物信息,必须严格遵守数据保护法规,如:
- GDPR(欧盟通用数据保护条例) :要求明确用户知情权、同意权、数据最小化原则;
- CCPA(加州消费者隐私法案) :赋予用户数据访问、删除和拒绝销售的权利;
- 中国的《个人信息保护法》 :规定人脸信息属于敏感个人信息,需获得单独同意,并采取严格保护措施。
7.3.2 用户数据最小化与匿名化处理策略
- 数据最小化 :仅采集必要的生物特征信息,避免存储原始图像;
- 匿名化处理 :将人脸特征向量与用户身份信息分离存储,通过哈希或令牌化技术进行映射;
- 数据生命周期管理 :设置数据保留期限,到期自动删除;
- 去标识化技术 :采用差分隐私(Differential Privacy)或k-匿名化等技术,防止数据被重新识别。
graph TD
A[人脸识别系统] --> B[数据采集]
B --> C{是否为最小化数据?}
C -->|是| D[特征向量加密存储]
C -->|否| E[拒绝采集]
D --> F[使用匿名化标识]
F --> G[数据访问控制]
G --> H[TLS加密传输]
H --> I[审计日志记录]
流程图说明:
– 系统在采集数据前判断是否符合最小化原则;
– 符合的数据经过加密与匿名化后进入存储;
– 所有访问均需通过访问控制机制,并使用加密传输;
– 所有操作记录进入审计日志,确保合规可追溯。
本文还有配套的精品资源,点击获取
简介:智能脸部识别系统是一种基于计算机视觉与深度学习的身份认证技术,广泛应用于电脑解锁、权限控制等安全场景。本系统通过摄像头采集人脸图像,提取面部特征并与模板进行比对,实现快速准确的身份识别。项目包含完整的安装文件、配置说明和使用指南,适用于Windows平台,并涉及相机权限管理、人脸识别算法实现及安全防护策略,帮助用户全面掌握人脸识别技术的应用与部署。
本文还有配套的精品资源,点击获取
