在机器学习模型不断发展的今天,正则化技术作为防止过拟合、提升模型泛化能力的核心手段,经历了从经典范式到现代创新的演变过程。本文深入探讨了L1、L2等经典正则化技术的理论基础、实现机制及其应用场景,同时分析了传统方法的局限性,并系统介绍了参数约束、自适应正则化等创新设计思路。通过架构图、生活化案例和代码示例,全面剖析了正则化技术的演进脉络,为机器学习架构师提供了正则化设计的实践指导与前瞻视角。
在机器学习领域,过拟合是模型开发中最常见的难题之一。过拟合发生在模型对训练数据学习“太好”,以至于捕捉到了数据中的噪声和异常值,从而影响了模型对新数据的泛化能力(扩展阅读:模型泛化的边界:内推与外推的辩证关系及前沿进展)。这种现象好比一个学生为了应付考试,死记硬背了所有习题答案,但未能理解题目背后的原理,当遇到形式稍作变化的新题时便束手无策。
深度学习模型因其复杂的结构和庞大的参数量,特别容易陷入过拟合的陷阱。一个典型的过拟合迹象是模型在训练集上表现优异,但在验证集或测试集上表现显著下降。这正是正则化技术诞生的背景——在训练过程中引入约束,平衡模型复杂性与泛化能力。
正则化的核心思想是在损失函数中添加额外的惩罚项,这一惩罚项与模型的复杂度成正比。这种技术可以看作是一种“奥卡姆剃刀”原则在机器学习中的应用:当多个模型都能解释数据时,应选择最简单的那个。
数学上,正则化的通用形式可以表示为:
损失函数 = 经验损失 + λ × 正则化项
其中λ是正则化参数,控制着正则化项对总体损失的影响强度。λ越大,正则化影响越强,模型越简单;λ越小,正则化影响越弱,模型复杂度越高。
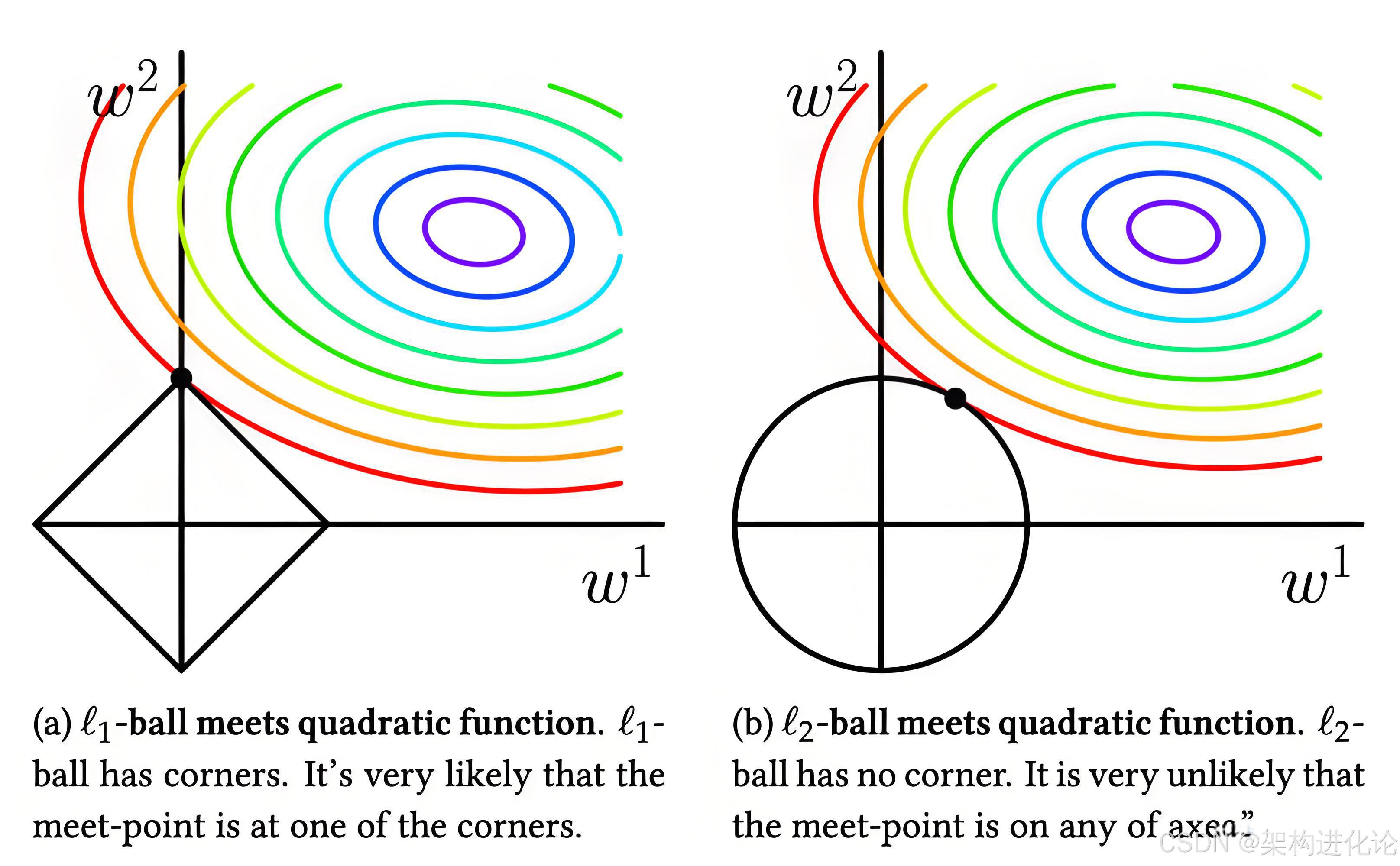
理论基础与数学表达
L2正则化,也称为岭回归或权重衰减,通过对权重向量的L2范数(即所有权重的平方和的平方根)施加惩罚。其数学表达式为:
L2正则化项 = λ × ∑(w_i²)
其中w_i表示模型中的第i个权重参数。当与原始损失函数结合时,总损失函数变为:
总损失 = 原始损失 + λ × ∑(w_i²)
工作机制与特性
L2正则化通过惩罚大的权重值,迫使权重均匀地趋近于零,但不会完全消除任何特征。这一特性源于其平方项的形式——权重越大,惩罚增长越快。在实际优化过程中,L2正则化相当于在每一步梯度下降更新时,先将权重按固定比例缩小,再根据损失梯度进行调整。
案例:花生酱三明治配方优化
设想你正在优化花生酱三明治的配方。你会考虑面包类型、花生酱种类和比例这些核心因素,但不会过度关注房间温度、早餐内容或袜子颜色等无关变量。L2正则化就像一个有经验的厨师,会适度考虑所有可能影响因素,但不会让任何一个因素占据主导地位,确保配方在不同环境下都能保持稳定表现。
理论基础与数学表达
L1正则化,又称LASSO回归,通过对权重向量的L1范数(即所有权重的绝对值之和)施加惩罚。其数学表达式为:
L1正则化项 = λ × ∑|w_i|
与原始损失函数结合后,总损失函数变为:
总损失 = 原始损失 + λ × ∑|w_i|
稀疏性与特征选择
L1正则化的核心特性是能够产生稀疏解,即迫使一部分权重精确为零,从而实现特征选择的效果。这一特性源于绝对值函数在零点不可导的性质。在实际应用中,L1正则化特别适用于特征数量远大于样本数量的高维数据集,能自动筛选出对预测真正重要的特征。
L1与L2的对比分析
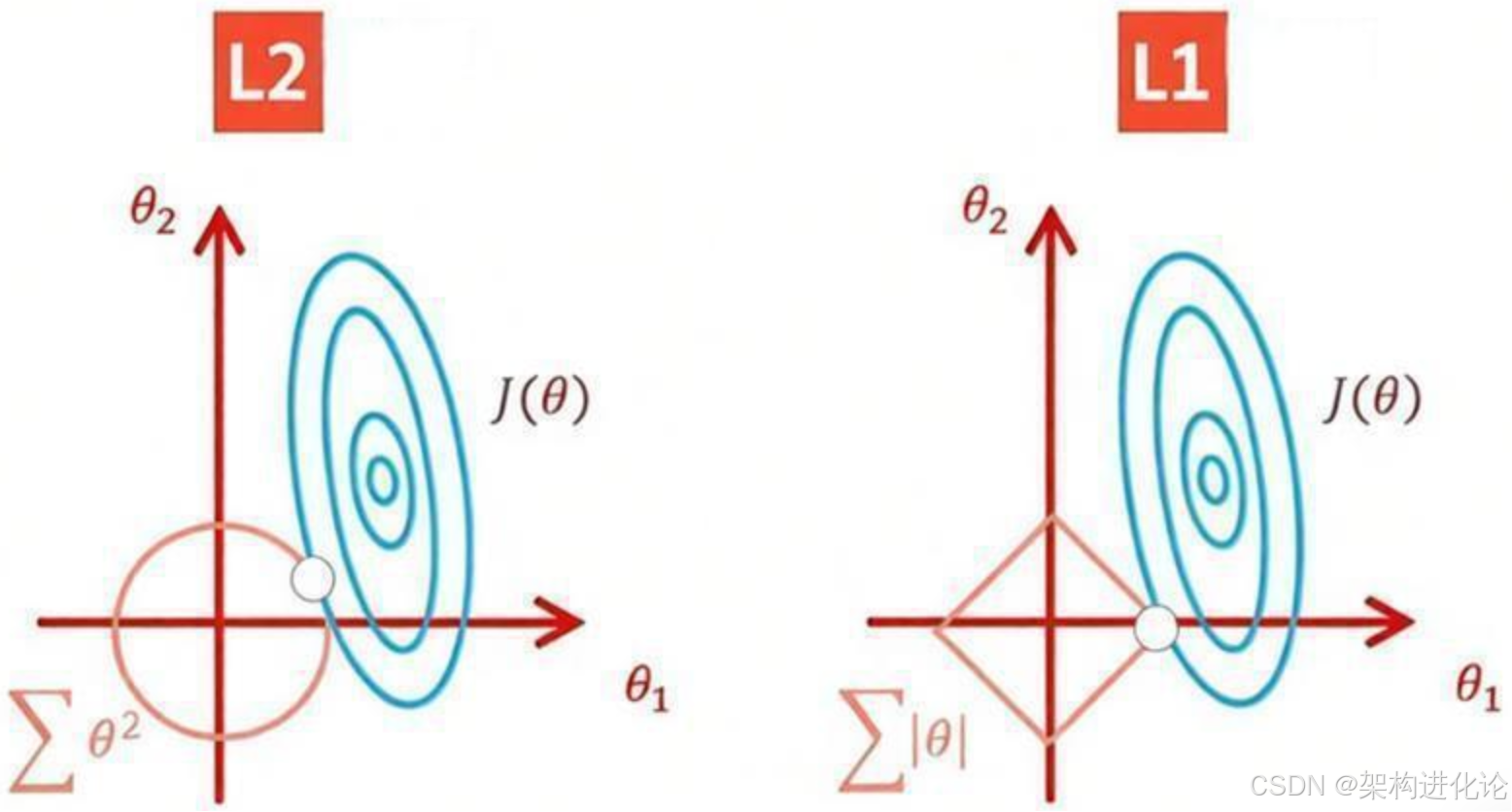
为了更清晰地理解L1和L2正则化的差异,可以参考以下对比:

弹性网络是L1和L2正则化的折中方案,结合了两种正则化的优点。其数学表达式为:
弹性网络正则化项 = λ₁ × ∑|w_i| + λ₂ × ∑w_i²
弹性网络既能像L1正则化那样产生稀疏解,进行特征选择,又能像L2正则化那样处理高度相关的特征,避免过度惩罚。
传统方法的局限性
传统的L2正则化(权重衰减)对所有参数施加统一的惩罚系数。这种方法假设所有参数对过拟合的贡献相同,但实际情况是不同参数在神经网络中扮演不同角色,对模型复杂度的贡献也各不相同。例如,靠近输入层的权重与靠近输出层的权重可能具有不同的统计特性,统一的正则化强度可能过度约束某些参数而不足以约束另一些参数。
约束参数正则化(CPR)
为了解决传统正则化的局限性,研究者提出了约束参数正则化(Constrained Parameter Regularization, CPR)。CPR不是通过添加惩罚项来正则化,而是将训练过程重新定义为约束优化问题,为每个参数矩阵的统计量(如L2范数)设置上限。这种方法仅引入轻微的运行开销,只需要设置约束上限,且研究者提出了简单高效的机制来初始化这些约束。
CPR的核心思想是:将正则化视为对参数空间的硬约束,而非对损失函数的软惩罚。这使得每个参数矩阵都有自己动态调整的正则化强度,而不是像传统权重衰减那样对所有参数使用统一的正则化系数。
个性化惩罚的需求
传统的正则化技术通常对所有特征使用统一的正则化系数,但这只是“无奈的选择”。统一惩罚存在明显缺点:同一个正则化系数值难以同时实现最佳估计精度和模型选择精度;统一惩罚也给设计矩阵的量纲选择带来困难。
个性化惩罚能够克服这些问题,但要使它实用化,需要一种与交叉验证不同的、能够根据数据自适应选择正则化系数的方法。
自适应阈值选择算法
研究者提出了全局自适应生成对齐算法(Global Adaptive Generative Alignment, GAGA),该算法将正则化问题隐含在估计过程中,从而使估计问题不再受正则化系数选择的困扰。GAGA算法不仅是多重阈值的生成方法,也是一个完整的参数估计方法,它几乎不需要设置超参数,并具有良好的理论性质和强大的性能。
实验表明,在默认参数下,自适应多重阈值GAGA算法在估计的均方误差和模型选择能力方面,都优于给出最优超参数情况下的自适应LASSO和正交匹配追踪算法。
规模化范式的转变
近年来,大规模语言预训练的显著成功和规模定律的发现标志着机器学习的范式转变。主要目标已从最小化泛化误差转变为减少逼近误差,最有效的策略从正则化(广义上)转变为扩大模型规模。这引发了一个关键问题:在规模化时代,传统正则化原则是否仍然有效?
规模定律交叉现象
研究者观察到一种名为“规模定律交叉”的新现象:两条规模曲线在某个规模处相交,这意味着在较小规模下有效的方法可能不适用于更大的规模。这一现象突出了新范式中的两个基本问题:
-
规模扩展的指导原则:如果正则化不再是模型设计的主要指导原则,那么新的原则正在出现以指导扩展?
-
规模下的模型比较:如何在只有一个实验可行的规模下可靠有效地比较模型?
这一转变并不意味着正则化技术变得无关紧要,而是其角色和应用方式需要重新思考。在大规模模型中,正则化可能更多用于优化训练过程稳定性和提高计算效率,而非直接防止过拟合。
随机增广拉格朗日方法
将正则化重新构想为约束优化问题是当前研究的创新方向之一。随机增广拉格朗日方法(Stochastic Augmented Lagrangian, SAL)将训练过程构建为约束优化问题,其中数据保真项是最小化目标,正则化项则作为约束。这种方法比固定惩罚方法更具适应性和灵活性,且对超参数的敏感性较低。
架构设计原理
以下是一个基于约束优化的正则化架构设计示意图:
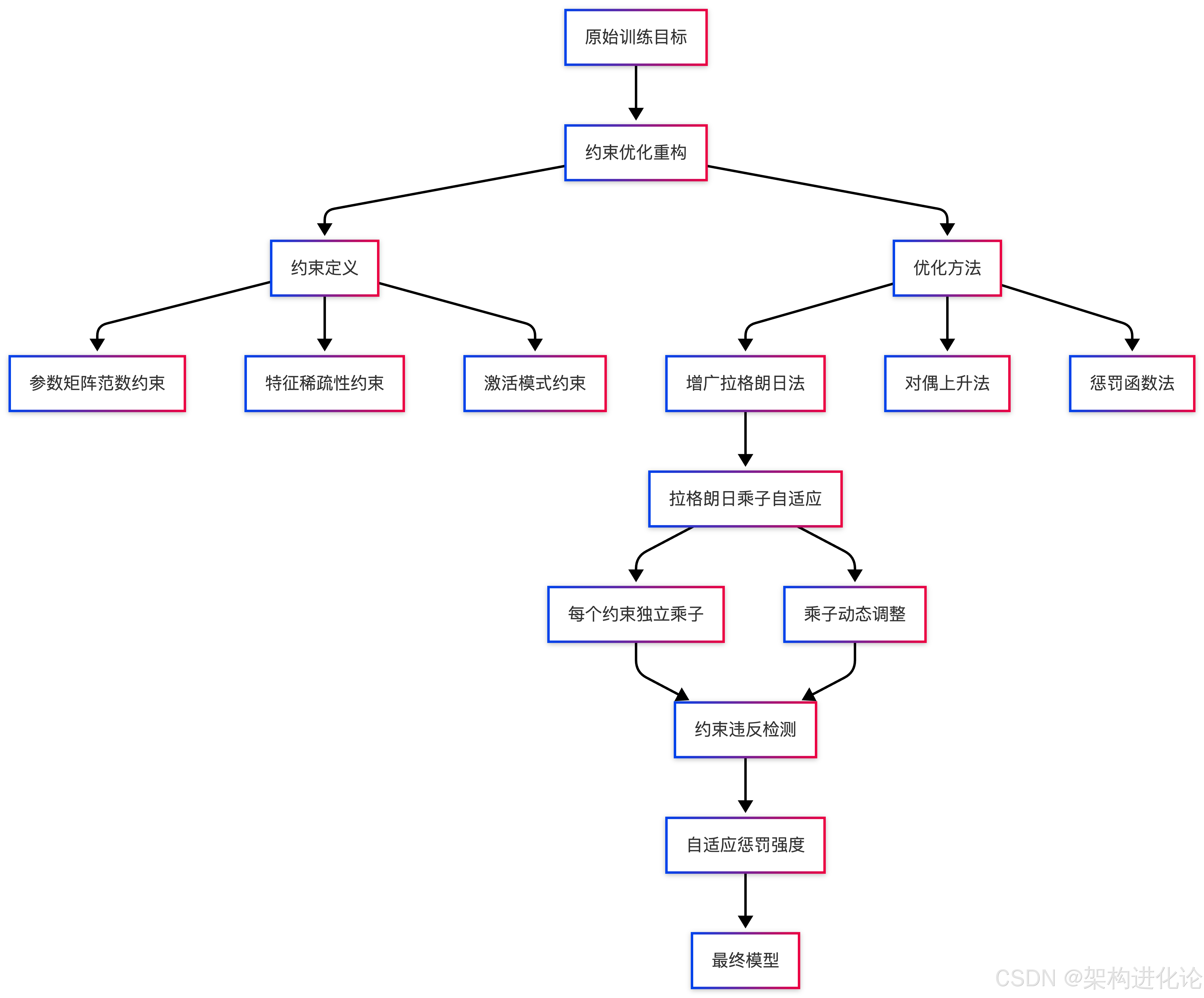
这种架构设计允许更精细的正则化控制,每个约束都有独立的拉格朗日乘子,这些乘子根据约束违反程度动态调整,从而实现自适应正则化强度。
层级敏感的正则化设计
现代深度神经网络具有层次化结构,不同层在表示学习过程中扮演不同角色。分层自适应正则化基于这一认识,为不同层设计不同的正则化策略:
-
底层(接近输入):通常学习基本特征(如边缘、纹理),适合较轻的正则化,以保留多样性
-
中层:学习组合特征,可适度正则化以去除冗余
-
高层(接近输出):学习高度抽象的概念,可能需要更强的正则化以防止过拟合特定任务
时间维度自适应
除了空间维度(不同层),正则化强度还可以在时间维度(训练过程)上自适应调整:
-
训练初期:模型尚未学习到有效特征,正则化宜轻
-
训练中期:模型开始学习到有效模式,但可能出现过拟合倾向,逐渐增强正则化
-
训练后期:模型趋于稳定,可适度放松正则化以微调参数
在实际应用中,单一正则化技术往往难以满足复杂模型的需求。多模态正则化融合将多种正则化策略有机结合:
-
结构正则化:如Dropout、DropPath等,通过随机丢弃网络单元增加鲁棒性
-
参数正则化:如L1/L2正则化,直接约束参数值
-
数据正则化:如数据增强、MixUp等,通过扩展训练数据提高泛化性
-
过程正则化:如早停、标签平滑等,通过调整训练过程防止过拟合
以下是一个使用Keras实现L1和L2正则化的代码示例:
import tensorflow as tf
from tensorflow.keras import layers, models, regularizers
# 创建一个包含L2正则化的简单全连接神经网络
def create_model_with_regularization(regularization_type='l2', lambda_val=0.01):
"""
创建带正则化的神经网络模型
参数:
regularization_type: 正则化类型,'l1'或'l2'
lambda_val: 正则化系数λ,控制正则化强度
"""
# 初始化模型
model = models.Sequential()
# 根据正则化类型选择正则化器
if regularization_type == 'l1':
regularizer = regularizers.l1(lambda_val)
elif regularization_type == 'l2':
regularizer = regularizers.l2(lambda_val)
else:
raise ValueError("正则化类型必须是'l1'或'l2'")
# 添加带正则化的输入层和隐藏层
# kernel_regularizer参数对权重矩阵应用正则化
# bias_regularizer参数对偏置应用正则化(通常不推荐)
model.add(layers.Dense(
128,
activation='relu',
input_shape=(784,), # 假设输入是28x28展平后的784维向量
kernel_regularizer=regularizer,
name='dense_1'
))
# 添加Dropout层作为另一种正则化方式
# Dropout在训练期间随机“丢弃”神经元,减少过拟合
model.add(layers.Dropout(0.5, name='dropout_1'))
# 添加第二层,同样应用正则化
model.add(layers.Dense(
64,
activation='relu',
kernel_regularizer=regularizer,
name='dense_2'
))
model.add(layers.Dropout(0.5, name='dropout_2'))
# 输出层,通常不应用正则化
model.add(layers.Dense(
10, # 假设是10分类问题
activation='softmax',
name='output_layer'
))
return model
# 创建并编译模型
model = create_model_with_regularization('l2', 0.01)
# 编译模型时指定损失函数和优化器
# 注意:正则化损失会在训练过程中自动添加到总损失中
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 打印模型摘要,可以看到每层的参数数量和正则化信息
print("模型结构摘要:")
model.summary()
# 模拟训练过程(实际使用需要真实数据)
print("
正则化模型训练示例(需实际数据):")
print("1. 准备训练数据和验证数据")
print("2. 使用model.fit()进行训练")
print("3. 监控训练损失和验证损失差异")
print("4. 如果验证损失开始上升而训练损失继续下降,可能存在过拟合")
print("5. 可调整lambda_val值或尝试L1/L2组合")以下是一个基于PyTorch实现自定义约束正则化的示例:
import torch
import torch.nn as nn
import torch.optim as optim
class ConstrainedParameterRegularization:
"""
约束参数正则化(CPR)实现
基于论文"Improving Deep Learning Optimization through Constrained Parameter Regularization"
将正则化表达为约束优化问题,使用增广拉格朗日方法求解
"""
def __init__(self, model, constraint_type='l2_norm', bound_values=None):
"""
初始化约束参数正则化
参数:
model: 要正则化的神经网络模型
constraint_type: 约束类型,如'l2_norm'、'l1_norm'等
bound_values: 各层约束上限字典,键为层名,值为约束上限
"""
self.model = model
self.constraint_type = constraint_type
self.bound_values = bound_values if bound_values else {}
# 初始化拉格朗日乘子(每个约束对应一个乘子)
self.lagrange_multipliers = {}
for name, param in model.named_parameters():
if 'weight' in name and param.dim() > 1: # 只对权重矩阵应用约束
self.lagrange_multipliers[name] = torch.zeros(1, requires_grad=False)
# 增广拉格朗日方法的惩罚参数
self.penalty_param = 1.0
self.penalty_growth_rate = 1.05
def compute_constraint_violation(self, param, layer_name):
"""
计算约束违反程度
参数:
param: 参数张量
layer_name: 层名称
返回:
constraint_violation: 约束违反程度
constraint_value: 约束函数值
"""
if self.constraint_type == 'l2_norm':
# 计算参数矩阵的L2范数(Frobenius范数)
constraint_value = torch.norm(param, p='fro')
elif self.constraint_type == 'l1_norm':
# 计算参数矩阵的L1范数
constraint_value = torch.norm(param, p=1)
else:
raise ValueError(f"不支持的约束类型: {self.constraint_type}")
# 获取该层的约束上限
bound = self.bound_values.get(layer_name, 1.0) # 默认上限为1.0
# 约束违反程度:constraint_value - bound(如果超过上限)
constraint_violation = torch.relu(constraint_value - bound)
return constraint_violation, constraint_value
def augmented_lagrangian_penalty(self):
"""
计算增广拉格朗日惩罚项
返回:
total_penalty: 总惩罚项,将添加到损失函数中
constraint_info: 约束信息字典,用于监控
"""
total_penalty = 0.0
constraint_info = {}
for name, param in self.model.named_parameters():
if 'weight' in name and param.dim() > 1:
# 计算约束违反程度
violation, value = self.compute_constraint_violation(param, name)
# 获取拉格朗日乘子
lambda_mult = self.lagrange_multipliers[name]
# 增广拉格朗日惩罚项:λ*violation + (ρ/2)*violation²
penalty = lambda_mult * violation + (self.penalty_param / 2) * violation**2
total_penalty += penalty
# 保存约束信息用于监控和更新乘子
constraint_info[name] = {
'value': value.item(),
'violation': violation.item(),
'multiplier': lambda_mult.item()
}
return total_penalty, constraint_info
def update_lagrange_multipliers(self, constraint_info):
"""
更新拉格朗日乘子
参数:
constraint_info: 约束信息字典,包含各层的约束违反程度
"""
for name, info in constraint_info.items():
if name in self.lagrange_multipliers:
# 乘子更新规则:λ_{k+1} = λ_k + ρ * violation
violation = info['violation']
self.lagrange_multipliers[name] += self.penalty_param * violation
# 增加惩罚参数以加速收敛
self.penalty_param *= self.penalty_growth_rate
def get_regularization_loss(self, original_loss):
"""
获取包含约束正则化的总损失
参数:
original_loss: 原始损失值
返回:
total_loss: 总损失(原始损失+约束惩罚)
constraint_info: 约束信息
"""
# 计算增广拉格朗日惩罚项
penalty, constraint_info = self.augmented_lagrangian_penalty()
# 总损失 = 原始损失 + 惩罚项
total_loss = original_loss + penalty
return total_loss, constraint_info
# 使用示例
class SimpleNN(nn.Module):
"""简单的神经网络示例"""
def __init__(self, input_size=784, hidden_size=128, output_size=10):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 创建模型和CPR正则化器
model = SimpleNN()
# 设置各层的约束上限(可根据层的重要性或特性设置不同上限)
bound_values = {
'fc1.weight': 5.0, # 第一层权重矩阵L2范数上限为5.0
'fc2.weight': 3.0 # 第二层权重矩阵L2范数上限为3.0
}
cpr = ConstrainedParameterRegularization(model, constraint_type='l2_norm', bound_values=bound_values)
# 创建优化器(注意:不包含权重衰减,因为CPR已提供正则化)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 模拟训练循环
def train_step(model, cpr, optimizer, data, target):
"""
训练步骤示例
参数:
model: 神经网络模型
cpr: 约束参数正则化器
optimizer: 优化器
data: 输入数据
target: 目标标签
返回:
total_loss: 总损失值
constraint_info: 约束信息
"""
# 前向传播
output = model(data)
# 计算原始损失(如交叉熵损失)
criterion = nn.CrossEntropyLoss()
original_loss = criterion(output, target)
# 获取包含约束正则化的总损失
total_loss, constraint_info = cpr.get_regularization_loss(original_loss)
# 反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 更新拉格朗日乘子
cpr.update_lagrange_multipliers(constraint_info)
return total_loss.item(), constraint_info
print("约束参数正则化(CPR)示例")
print("1. 为不同层设置不同的约束上限")
print("2. 使用增广拉格朗日方法处理约束")
print("3. 拉格朗日乘子根据约束违反程度自适应调整")
print("4. 提供比传统权重衰减更灵活的正则化控制")以下是一个自适应L1/L2混合正则化的实现示例:
import numpy as np
class AdaptiveRegularization:
"""
自适应正则化:根据训练进度和参数重要性动态调整正则化强度
结合了以下策略:
1. 时间衰减:随训练进行逐渐增加正则化强度
2. 参数重要性感知:对不重要的参数施加更强正则化
3. 层差异化:不同层使用不同的正则化策略
"""
def __init__(self, initial_lambda=0.001, decay_rate=0.95,
importance_threshold=0.1, sparsity_target=0.3):
"""
初始化自适应正则化器
参数:
initial_lambda: 初始正则化强度
decay_rate: 时间衰减率(每个epoch后lambda乘以该值)
importance_threshold: 参数重要性阈值,低于此值的参数将获得更强正则化
sparsity_target: 目标稀疏度(用于L1正则化)
"""
self.lambda_l2 = initial_lambda
self.lambda_l1 = initial_lambda * 0.5 # L1正则化通常比L2小
self.decay_rate = decay_rate
self.importance_threshold = importance_threshold
self.sparsity_target = sparsity_target
# 记录参数历史信息
self.param_history = {}
self.current_epoch = 0
def compute_parameter_importance(self, param_name, param_value, gradient):
"""
计算参数重要性
参数重要性基于:
1. 参数绝对值大小
2. 梯度大小
3. 参数变化率(与历史值比较)
"""
# 参数绝对值均值(标准化)
abs_mean = torch.mean(torch.abs(param_value)).item()
# 梯度绝对值均值
if gradient is not None:
grad_mean = torch.mean(torch.abs(gradient)).item()
else:
grad_mean = 0.0
# 与历史值比较(如果有)
if param_name in self.param_history:
prev_value = self.param_history[param_name]
change_rate = abs(abs_mean - prev_value) / (prev_value + 1e-8)
else:
change_rate = 0.0
# 综合重要性评分
importance = 0.5 * abs_mean + 0.3 * grad_mean + 0.2 * change_rate
# 更新历史记录
self.param_history[param_name] = abs_mean
return importance
def adaptive_regularization_term(self, param_name, param_value, gradient=None):
"""
计算自适应正则化项
根据参数重要性动态调整L1和L2正则化的混合比例
"""
# 计算参数重要性
importance = self.compute_parameter_importance(param_name, param_value, gradient)
# 根据重要性调整正则化强度
# 重要性低的参数获得更强正则化
if importance < self.importance_threshold:
# 低重要性参数:强L1正则化(促进稀疏性)
l1_weight = 0.8
l2_weight = 0.2
strength_multiplier = 2.0 # 正则化强度加倍
else:
# 高重要性参数:主要使用L2正则化(平滑约束)
l1_weight = 0.2
l2_weight = 0.8
strength_multiplier = 0.5 # 正则化强度减半
# 应用时间衰减:随着训练进行,逐渐增加正则化强度
epoch_factor = 1.0 + 0.1 * self.current_epoch
total_strength = strength_multiplier * epoch_factor
# 计算自适应正则化项
l1_penalty = l1_weight * total_strength * self.lambda_l1 * torch.sum(torch.abs(param_value))
l2_penalty = l2_weight * total_strength * self.lambda_l2 * torch.sum(param_value ** 2)
return l1_penalty + l2_penalty
def update_hyperparameters(self, current_sparsity):
"""
更新超参数
根据当前模型状态动态调整正则化参数
"""
# 时间衰减
self.lambda_l2 *= self.decay_rate
self.lambda_l1 *= self.decay_rate
# 根据当前稀疏度调整L1正则化强度
# 如果稀疏度低于目标,增加L1强度
if current_sparsity < self.sparsity_target:
self.lambda_l1 *= 1.1
# 如果稀疏度过高,减少L1强度
elif current_sparsity > self.sparsity_target + 0.1:
self.lambda_l1 *= 0.9
# 更新epoch计数
self.current_epoch += 1
return {
'lambda_l1': self.lambda_l1,
'lambda_l2': self.lambda_l2,
'current_epoch': self.current_epoch
}
# 使用示例
def compute_model_sparsity(model):
"""计算模型的稀疏度(零参数比例)"""
total_params = 0
zero_params = 0
for param in model.parameters():
if param.dim() > 1: # 只考虑权重,忽略偏置
total_params += param.numel()
zero_params += torch.sum(param == 0).item()
return zero_params / total_params if total_params > 0 else 0
print("自适应正则化示例")
print("1. 根据参数重要性动态调整L1/L2混合比例")
print("2. 低重要性参数获得更强正则化,促进稀疏性")
print("3. 高重要性参数获得适度正则化,避免过度惩罚")
print("4. 正则化强度随训练时间自适应调整")
print("5. 根据当前稀疏度动态调整L1正则化强度")随着模型规模不断扩大,正则化技术的角色正在发生转变。在大规模预训练模型中,正则化的重点可能从防止过拟合转向优化训练动态和提高计算效率。例如,在大语言模型中,正则化技术可用于:
-
稳定大规模训练:防止梯度爆炸/消失,确保训练过程稳定
-
促进参数高效性:通过稀疏正则化减少活跃参数数量,降低推理成本
-
提高迁移能力:通过适当正则化使学到的表示更具通用性
正则化技术的理论发展仍有广阔空间,未来的创新方向可能包括:
-
基于信息的正则化:利用信息论原理设计正则化项,如最小化权重与数据的互信息
-
因果正则化:融入因果推断思想,使模型学习因果结构而非仅相关关系
-
拓扑正则化:基于拓扑数据分析,约束模型表示的拓扑特性
未来的正则化系统将更加智能化和自适应:
-
完全自适应正则化:无需手动设置超参数,完全根据数据特性和训练动态自适应调整
-
多目标正则化:同时考虑模型性能、稀疏性、鲁棒性、公平性等多个目标的正则化框架
-
元学习正则化:使用元学习技术自动发现适合特定任务和数据的正则化策略
正则化技术作为机器学习模型设计的核心组成部分,经历了从简单惩罚到复杂约束,从静态超参数到动态自适应,从统一策略到个性化设计的演进过程。未来的正则化创新将继续沿着自动化、适应性和理论严谨性的方向发展,为构建更强大、更可靠的机器学习系统提供坚实支撑。
