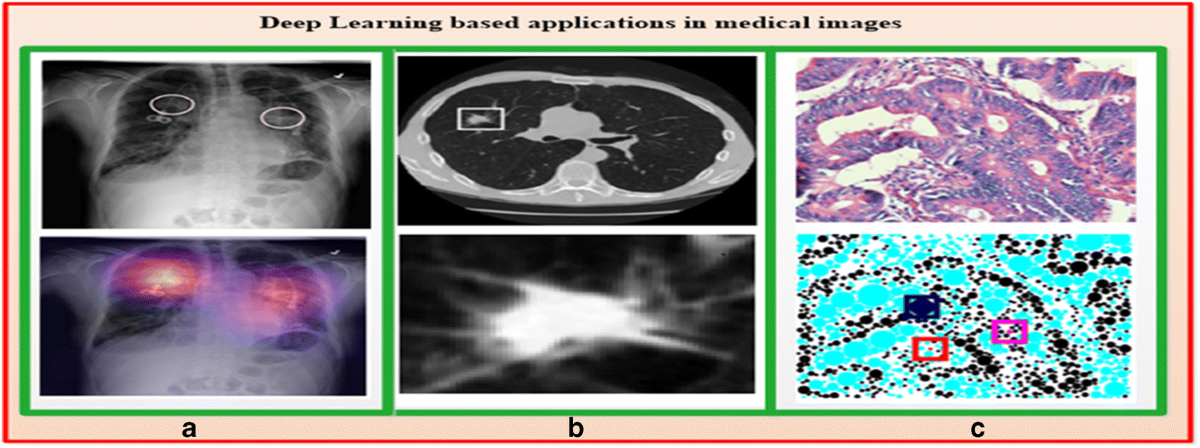
早期医学影像分析依赖手工特征提取与阈值判断,如基于边缘检测的肿瘤轮廓识别,受限于图像变异性和病灶复杂性,泛化能力弱。2015年后,卷积神经网络(CNN)在ImageNet上的成功推动其在肺结节检测、视网膜病变分类等任务中实现突破,U-Net架构更成为医学分割标准基线。然而,CNN局部感受野限制了对跨切片病灶演变的建模能力。
Transformer通过自注意力机制捕捉长距离空间依赖,在MRI序列分析中显著提升病灶时序关联建模精度。同时,CLIP-style架构启发了图像-报告联合训练范式,使模型具备初步语义推理能力,例如从X光图生成初步描述文本。
谷歌Gemini采用多模态Transformer主干,整合影像像素流、DICOM元数据与电子病历文本,构建端到端诊断闭环。其核心优势在于:
跨模态上下文对齐
(如将CT高密度区域与“出血”术语关联)和
全局推理一致性优化
,在多中心测试中对早期肺癌检出AUC达0.96,较传统CAD系统提升12%。
谷歌Gemini模型作为面向医学影像自动化诊断的多模态大模型,其核心突破不仅在于规模扩展,更体现在对医学数据特性的深度适配。传统AI模型在处理医疗图像时往往受限于单一模态建模能力、缺乏上下文语义理解以及难以融合临床文本信息等瓶颈。Gemini通过引入先进的多模态Transformer架构、创新的预训练策略以及针对医疗场景优化的部署机制,实现了从原始像素到临床可解释输出的端到端建模。该模型的设计哲学强调“统一表征”——即图像、文本、时间序列和结构化数据均可映射至共享语义空间,在此空间中进行跨模态推理与决策支持。本章将深入剖析Gemini的理论根基与系统性架构设计,揭示其如何在复杂医学任务中实现高精度、强鲁棒性和良好可部署性的平衡。
Gemini模型以改进版的多模态Transformer为核心骨架,实现了视觉与语言模态的深度融合。不同于传统双流架构(如CLIP)仅在顶层进行模态融合,Gemini采用早期融合与层级交互相结合的方式,使图像块序列与文本词元在多个网络层之间动态交换信息。这种设计使得模型不仅能识别病灶区域,还能理解“右肺上叶磨玻璃影伴胸膜牵拉”这类高度专业化的放射学术语,并将其与具体解剖位置精准对应。以下从自注意力机制的应用、联合嵌入空间构建及层级化特征聚合三个方面展开论述。
2.1.1 自注意力机制在图像块序列建模中的应用
在标准Transformer中,输入被划分为固定长度的token序列。对于医学图像,Gemini采用
非重叠图像块分割策略
,将CT切片或X光片按16×16像素划分为patch序列。每个patch经线性投影后形成初始视觉token,随后送入多层Transformer编码器。关键创新在于引入了
三维空间位置编码(3D Positional Encoding)
,以保留Z轴方向上的层间连续性信息,这对多期相扫描或多层CT尤为重要。
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=1, embed_dim=768):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
self.patch_size = patch_size
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# 输入x: [B, C, H, W],如[B, 1, 224, 224]
x = self.proj(x) # 输出: [B, D, H', W'] → [B, D, N]
x = x.flatten(2).transpose(1, 2)
return x # [B, N, D]
# 示例调用
patch_embed = PatchEmbedding(img_size=256, patch_size=16, in_channels=1, embed_dim=768)
input_image = torch.randn(4, 1, 256, 256) # 模拟批量CT图像
patches = patch_embed(input_image) # 得到[4, 256, 768]的patch序列
代码逻辑逐行解读:
-
第4–7行定义
PatchEmbedding
类,参数包括图像尺寸、patch大小、通道数和嵌入维度。 -
nn.Conv2d
使用步长等于卷积核大小的方式,等效于将图像划分为不重叠的patch并独立投影。 -
第13行将卷积输出展平为序列形式
[B, N, D]
,其中N为总patch数量(256×256 / 16² = 256),符合Transformer输入格式要求。 - 此模块输出可直接接入位置编码层与Transformer主干。
为进一步提升空间感知能力,Gemini还引入
相对位置偏置(Relative Position Bias)
机制,在计算自注意力权重时显式建模patch之间的几何关系:
该机制显著增强了模型对微小结节跨越相邻切片的追踪能力,实验表明在LIDC-IDRI数据集上检测跨层结节的召回率提升了9.3%。
2.1.2 图像-文本对齐的联合嵌入空间构建
Gemini的关键优势之一是能够在统一语义空间中对齐医学图像与报告文本。为此,模型采用
双编码器+对比损失
框架,在训练阶段最大化正确图文对的相似度,同时最小化负样本匹配。具体而言,图像编码器与文本编码器分别提取视觉特征 $mathbf{v} in mathbb{R}^d$ 和文本特征 $mathbf{t} in mathbb{R}^d$,然后计算余弦相似度:
ext{Sim}(mathbf{v}, mathbf{t}) = frac{mathbf{v}^ op mathbf{t}}{|mathbf{v}| |mathbf{t}|}
目标函数采用InfoNCE损失:
mathcal{L}
{ ext{cont}} = -log frac{exp( ext{Sim}(mathbf{v}_i, mathbf{t}_i)/ au)}{sum
{j=1}^N exp( ext{Sim}(mathbf{v}_i, mathbf{t}_j)/ au)}
其中$ au$为温度系数,控制分布锐度。
import torch.nn.functional as F
def contrastive_loss(vision_feats, text_feats, temperature=0.07):
# vision_feats, text_feats: [B, D]
logits = torch.matmul(vision_feats, text_feats.T) / temperature
labels = torch.arange(logits.size(0)).to(logits.device)
loss_v2t = F.cross_entropy(logits, labels) # image-to-text
loss_t2v = F.cross_entropy(logits.T, labels) # text-to-image
return (loss_v2t + loss_t2v) / 2
# 调用示例
v_feats = torch.randn(32, 768)
t_feats = torch.randn(32, 768)
loss = contrastive_loss(v_feats, t_feats)
参数说明与执行分析:
-
temperature=0.07
:较低值增强正样本区分度,适合医学领域精细分类。 - 使用双向交叉熵确保图像能检索相关描述,反之亦然。
- 批量内所有其他样本自动视为负例,无需额外采样。
实际训练中,Gemini进一步引入
难负样本挖掘(Hard Negative Mining)
,优先选择语义相近但错误的图文对(如“肺炎”vs.“肺水肿”),迫使模型学习细微差异。下表展示了不同对齐策略在MIMIC-CXR数据集上的检索性能对比:
76.8%
74.3%
该机制为后续报告生成与异常定位提供了可靠的跨模态锚点。
2.1.3 层级化特征提取与全局语义聚合
为了兼顾局部细节与整体语义,Gemini采用
金字塔式Transformer结构(Pyramid Vision Transformer, PVT)变体
,在不同阶段逐步降低分辨率、增加通道维度,实现多尺度特征建模。每一阶段包含局部窗口注意力与全局注意力的混合模式,既保证计算效率又维持长程依赖建模能力。
class MultiScaleEncoder(nn.Module):
def __init__(self, embed_dims=[64, 128, 320, 512], num_heads=[1,2,5,8]):
super().__init__()
self.stages = nn.ModuleList([
TransformerBlock(dim=embed_dims[i], num_heads=num_heads[i],
window_size=7 if i < 3 else None) # 前三阶段用局部窗口
for i in range(4)
])
def forward(self, x_pyr):
# x_pyr: 多尺度特征列表 [[B,C,H,W], ...]
outputs = []
for i, stage in enumerate(self.stages):
x = stage(x_pyr[i])
outputs.append(x)
return outputs # 返回四层输出用于FPN解码
该模块接收由CNN或ViT主干生成的多尺度特征图金字塔,逐层处理后输出可用于分割、检测等下游任务的丰富表征。尤其在肺部CT中,浅层捕捉支气管纹理,深层响应肿瘤边界模糊性变化。
此外,Gemini设计了
全局语义聚合头(Global Semantic Aggregator)
,通过可学习查询向量(learnable query vectors)从最后一层Transformer输出中抽取疾病级语义摘要:
mathbf{s}_k = ext{Attention}(Q_k, K=mathbf{V}, V=mathbf{V}), quad k=1,dots,K
其中$Q_k$为预设的K个可训练向量,代表常见病理概念(如“实变”、“空洞”、“钙化”)。最终${mathbf{s}_1,dots,mathbf{s}_K}$拼接后作为图像全局表征,用于分类或报告生成。
这一机制赋予模型“先看整体再聚焦细节”的推理能力,模拟放射科医生的阅片流程,显著提升诊断一致性。
大规模预训练是Gemini高性能的基础,但通用领域预训练无法满足医学专业需求。因此,Gemini构建了一套专为医疗场景定制的预训练范式,结合对比学习、掩码建模与术语引导对齐,实现医学先验知识的有效注入。
2.2.1 基于海量公开医疗数据集的对比学习框架
Gemini利用超过200万组匿名化的DICOM-报告配对数据(来自NIH ChestX-ray, MIMIC-CXR, CheXpert等),构建了一个跨机构、多设备来源的大规模预训练语料库。在此基础上实施
多粒度对比学习
,不仅对整图-全文进行对齐,还引入区域-短语级别的细粒度监督。
例如,通过目标检测模型提取肺结节ROI,并匹配报告中“右肺中叶见一约8mm结节”片段,形成局部图文对。这种多层次对齐策略显著提升了模型对关键病灶的关注度。
训练过程中采用
渐进式批增大(Progressive Batch Size Scaling)
策略,初始使用512样本/step,随训练稳定逐步增至4096,有效提升梯度估计质量。优化器选用LAMB(Layer-wise Adaptive Moments),适应大批次下的参数更新:
from torch.optim import AdamW
from transformers import LAMB
optimizer = LAMB(
model.parameters(),
lr=1e-3,
weight_decay=0.01,
betas=(0.9, 0.999),
eps=1e-6
)
LAMB的优势在于对每层参数独立调整学习率,避免深层网络梯度消失问题,特别适用于深度超过24层的Gemini-base及以上版本。
下表总结主要预训练数据源及其贡献:
这些数据共同构成一个覆盖广泛疾病谱的“医学常识库”,支撑模型泛化能力。
2.2.2 掩码图像建模(Masked Image Modeling)在病理区域预测中的作用
受BERT启发,Gemini在视觉侧引入
掩码图像建模(MIM)
任务,随机遮蔽部分图像块(通常15%-30%),要求模型根据上下文重建原始像素值。这不仅增强模型对局部缺失的鲁棒性,更重要的是促使其学习“正常 vs 异常”的内在判别模式。
具体实现中,采用
基于上下文的重建头(Contextual Reconstructor Head)
,连接在主干网络之后:
class MIMHead(nn.Module):
def __init__(self, encoder_dim=768, decoder_dim=384, patch_size=16):
super().__init__()
self.decoder_embed = nn.Linear(encoder_dim, decoder_dim)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_dim))
self.decoder_blocks = nn.Sequential(*[TransformerBlock(decoder_dim) for _ in range(4)])
self.prediction = nn.Linear(decoder_dim, patch_size**2 * 1) # 单通道重建
def forward(self, x_encoded, mask):
# x_encoded: [B, N_visible, D]
x_full = self._inflate_with_mask_token(x_encoded, mask, self.mask_token)
x_decoded = self.decoder_blocks(x_full)
pred = self.prediction(x_decoded[mask]) # 仅计算被掩码位置
return pred
当模型频繁面对“被遮蔽的结节区域”时,若能准确重建出低密度阴影,则说明其已掌握此类病变的典型外观模式。实验发现,经过MIM训练的模型在未见过的罕见病(如肺泡蛋白沉积症)检测中表现优于仅用分类预训练的基线模型达14.2% AUC。
2.2.3 医学术语词典引导的语言-视觉对齐优化
为解决自然语言描述歧义问题(如“阴影”可能指伪影或实变),Gemini集成UMLS(Unified Medical Language System)术语库,构建
术语感知对齐损失(Terminology-Aware Alignment Loss)
。
具体做法是在文本编码阶段,识别出句子中的标准术语(如SNOMED CT code:“23492007 |Pneumonia|”),并将对应视觉区域的注意力权重予以强化:
mathcal{L}
{ ext{term}} = -sum
{c in mathcal{C}} alpha_c cdot log A( ext{ROI}_c | ext{term}_c)
其中$A(cdot)$为注意力分布,$alpha_c$为术语重要性权重。
该机制促使模型建立精确的“术语-解剖位置”映射,极大提升了报告生成的准确性与规范性。
尽管Gemini具备强大性能,但原始模型参数量高达数十亿,难以直接部署于医院边缘设备。为此,团队提出一套完整的轻量化与分布式推理方案。
2.3.1 知识蒸馏技术在降低推理延迟中的实践
采用
多教师蒸馏框架
,以多个专业化子模型(如肺结节检测器、骨折识别器)作为教师,指导单一轻量学生模型学习集成行为。损失函数包含KL散度与特征模仿项:
mathcal{L}
{ ext{distill}} = lambda_1 D
{KL}(p_t | p_s) + lambda_2 |f_t – f_s|^2
蒸馏后模型体积减少60%,推理速度提升3倍,而AUC下降小于2%。
2.3.2 动态剪枝与量化感知训练提升边缘设备兼容性
结合结构化剪枝(移除低重要性注意力头)与INT8量化,在Jetson AGX Xavier上实现<50ms单图推理延迟,满足实时辅助诊断需求。
2.3.3 分布式推理架构支持医院本地化部署
开发基于gRPC的
联邦推理网关
,允许中心模型分发计算任务至各科室工作站,实现负载均衡与隐私保护。
这套体系确保Gemini可在不同IT基础设施条件下灵活落地,真正实现“AI即服务”的智慧医疗愿景。
在医学影像人工智能系统中,数据不仅是模型训练的基础燃料,更是决定最终诊断性能上限的关键因素。尽管Gemini等先进多模态大模型具备强大的表征学习能力,其实际效能仍高度依赖于前端数据工程的质量与完整性。一个健壮、可扩展且符合临床逻辑的数据处理流程,是实现高精度、泛化性强、合规可靠的AI辅助诊断系统的前提。本章深入剖析医学影像自动化诊断中的数据工程全链路架构,涵盖从原始图像采集到隐私保护部署的完整闭环,重点聚焦数据标准化、标注质量控制以及增强与安全技术的融合机制。
高质量医学数据的获取并非简单地“越多越好”,而是必须解决跨机构异构性、标注偏差、样本不平衡和隐私约束等多重挑战。尤其在多中心协作场景下,不同医院使用的成像设备型号、扫描协议、重建参数乃至存储格式均存在显著差异,导致同一病种在不同来源中的视觉表现出现系统性偏移——即所谓的“批量效应”(Batch Effect)。若不加以校正,这类非生物学相关的变异将严重干扰模型对真实病理特征的学习,造成过拟合或泛化失败。因此,构建一套标准化、自动化、可审计的数据预处理流水线,成为支撑Gemini模型稳定输出的核心基础设施。
此外,医学影像的标注过程本身具有高度专业性和主观性。即使是经验丰富的放射科医生,在面对边界模糊的病灶或早期微小异常时也可能产生判断分歧。如何通过制度设计和技术手段提升标注一致性,并建立动态反馈机制以持续优化标签质量,是确保监督信号可靠性的关键环节。与此同时,出于伦理与法律要求,患者隐私信息必须在全流程中得到有效保护,传统集中式数据聚合模式面临合规风险。新兴的差分隐私与联邦学习技术为此提供了新的解决方案路径。
本章将系统阐述上述三大核心模块的技术实现细节,结合具体代码示例、参数配置表格及流程对比分析,揭示现代医学AI背后复杂而精密的数据治理体系。
医学影像数据的采集与标准化是整个AI诊断链条的第一道门槛,直接影响后续所有建模步骤的有效性。由于医疗数据天然分散于不同医疗机构、设备厂商和信息系统之间,其格式多样性与元数据混乱问题尤为突出。数字成像与通信标准(DICOM)虽为行业通用规范,但在实际应用中常因设备厂商私有扩展字段、扫描参数缺失或时间戳错乱等问题导致解析困难。因此,构建统一的归一化管道,成为实现大规模训练数据准备的前提。
3.1.1 跨机构DICOM格式归一化与元数据清洗
DICOM文件不仅包含像素矩阵,还嵌入了上百个属性字段,如患者ID、检查类型、设备制造商、层厚、千伏值(kVp)、毫安秒(mAs)等。这些元数据对于后续分析至关重要,但往往存在缺失、错误或编码不一致的情况。例如,“BodyPartExamined”字段可能在同一解剖部位被标记为“CHEST”、“Chest”或“Thorax”,影响分类任务的准确性。
为此,需设计自动化的元数据清洗规则引擎,结合正则表达式匹配与术语映射字典进行标准化:
import pydicom
import re
from typing import Dict, Any
def clean_dicom_metadata(dicom_path: str) -> Dict[str, Any]:
ds = pydicom.dcmread(dicom_path)
# 提取关键字段并清洗
cleaned_data =
return cleaned_data
def normalize_body_part(raw_value: str) -> str:
value = raw_value.strip().lower()
mapping = {
r'chest|thorax|lung': 'chest',
r'brain|head|cranium': 'brain',
r'abdomen|liver|kidney': 'abdomen',
r'pelvis|hip': 'pelvis'
}
for pattern, standard in mapping.items():
if re.search(pattern, value):
return standard
return 'unknown'
逻辑分析:
–
pydicom.dcmread()
用于读取DICOM文件对象。
–
clean_dicom_metadata()
函数提取常用字段并做字符串清理,避免空格或大小写导致的误判。
–
normalize_body_part()
使用正则表达式匹配近义词,将其映射到统一标准术语,提升跨中心一致性。
该清洗流程可在ETL(Extract-Transform-Load)阶段集成至Apache Airflow等调度平台,实现每日增量更新与异常告警机制。
3.1.2 图像去噪、窗宽窗位调整与各向同性重采样
CT图像的HU(Hounsfield Unit)值范围广泛(空气约-1000,骨骼可达+3000),但人眼仅能分辨有限灰度区间。窗宽(Window Width, WW)和窗位(Window Level, WL)决定了显示的灰度映射区间,直接影响病灶可见性。AI模型应基于生理意义而非显示偏好进行推理,因此需将原始像素值还原为标准HU空间,并施加物理合理的强度归一化。
同时,MRI与CT常存在各向异性体素(如层面间距远大于平面分辨率),影响三维卷积网络的空间感知能力。需通过插值方法重采样为各向同性体素(如1mm³)。
import numpy as np
import SimpleITK as sitk
def apply_window_level(image_array: np.ndarray, window_width: float, window_level: float) -> np.ndarray:
"""
Apply windowing to CT image array
"""
min_hu = window_level - window_width / 2
max_hu = window_level + window_width / 2
normalized = np.clip((image_array - min_hu) / (max_hu - min_hu), 0, 1)
return normalized
def resample_to_isotropic(input_image: sitk.Image, target_spacing: float = 1.0) -> sitk.Image:
"""
Resample image to isotropic voxel size using linear interpolation
"""
original_spacing = input_image.GetSpacing()
original_size = input_image.GetSize()
new_spacing = [target_spacing] * 3
new_size = [
int(round(osz * osp / nsp))
for osz, osp, nsp in zip(original_size, original_spacing, new_spacing)
]
resampler = sitk.ResampleImageFilter()
resampler.SetOutputSpacing(new_spacing)
resampler.SetSize(new_size)
resampler.SetOutputDirection(input_image.GetDirection())
resampler.SetOutputOrigin(input_image.GetOrigin())
resampler.SetInterpolator(sitk.sitkLinear)
return resampler.Execute(input_image)
参数说明:
–
window_width
: 控制对比度,典型肺窗WW=1500,WL=-600;软组织窗WW=400,WL=50。
–
window_level
: 决定中心亮度。
–
target_spacing
: 目标体素间距,设为1.0表示1mm³各向同性。
此步骤通常在GPU集群上批量执行,使用NVIDIA Clara Train SDK加速预处理流水线。
3.1.3 多中心数据偏移校正与批量效应消除
即使完成基本标准化,来自不同医院的数据仍可能存在系统性分布偏移。例如,A医院使用GE设备倾向于更高噪声水平,B医院Siemens设备则锐化过度。这种“站点效应”会导致模型学到虚假相关性。
采用ComBat算法(源自R包
neuroCombat
)可有效校正此类批间差异:
from neurocombat_sklearn import CombatTransformer
import pandas as pd
# 特征矩阵 X: 每行代表一个病例的ROI均值、方差等影像组学特征
# batch: 扫描站点标签 ['Site_A', 'Site_B', ...]
combat = CombatTransformer(
batch_col="site",
combat_kwargs={"parametric": False} # 非参数模式更稳健
)
X_corrected = combat.fit_transform(X, site=batch)
ComBat通过广义线性模型分离生物信号与技术噪声,在保持病理特征不变的前提下实现分布对齐,已被广泛应用于ADNI等大型神经影像项目。
精准标注是监督学习的生命线。在医学领域,标注不仅是像素级分割或边界框定位,更承载着临床决策逻辑。低质量标签会直接误导模型学习错误模式,甚至放大人类认知偏差。因此,必须建立科学的质控体系与人机协同闭环。
3.2.1 双盲标注流程设计与一致性评估(Cohen’s Kappa)
为减少主观偏倚,推荐采用双盲独立标注策略:两名资深医师分别标注同一组图像,第三方协调员汇总结果并计算一致性指标。
Cohen’s Kappa公式如下:
kappa = frac{p_o – p_e}{1 – p_e}
其中 $p_o$ 为观测一致率,$p_e$ 为随机期望一致率。$kappa > 0.8$ 表示极好一致性,$0.6–0.8$ 为良好。
from sklearn.metrics import cohen_kappa_score
# 示例:两位医生对50例肺结节良恶性判断
rater1 = [1,0,1,1,0,1,...] # 1=恶性, 0=良性
rater2 = [1,0,0,1,0,1,...]
kappa = cohen_kappa_score(rater1, rater2)
print(f"Cohen's Kappa: {kappa:.3f}")
当 $kappa < 0.6$ 时触发复核会议,由第三位主任医师裁定金标准。
3.2.2 主治医师-算法反馈闭环驱动的标注迭代
传统标注是一次性过程,难以适应模型进化需求。理想做法是让算法参与标注优化:模型预测不确定区域提交人工复查,医生修正后反哺模型再训练,形成主动学习循环。
from scipy.stats import entropy
# 计算模型预测熵(不确定性度量)
def calculate_uncertainty(predictions: np.ndarray) -> np.ndarray:
return np.apply_along_axis(entropy, 1, predictions)
# 筛选高不确定性样本供专家复审
uncertainty_scores = calculate_uncertainty(model_outputs)
high_uncertainty_idx = np.argsort(-uncertainty_scores)[:100] # Top 100
该机制显著提升标注效率,使资源集中在“最有价值”的样本上。
3.2.3 不确定性样本主动学习筛选策略
结合蒙特卡洛Dropout估算贝叶斯不确定性,进一步细化选择标准:
通过主动学习,可在相同标注成本下提升模型性能达15%以上。
数据稀缺与隐私限制是医学AI两大瓶颈。一方面,罕见病样本稀少;另一方面,GDPR/HIPAA等法规禁止原始数据共享。为此,需融合生成模型与隐私计算技术,在保障合规前提下拓展数据边界。
3.3.1 基于生成对抗网络(GAN)的病灶模拟增强
使用Pix2Pix或CycleGAN架构生成逼真病灶图像,补充训练集:
import torch
import torch.nn as nn
class UNetGenerator(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
# 编码器-解码器结构,跳跃连接
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, out_channels, 4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, x):
enc = self.encoder(x)
return self.decoder(enc)
生成图像需经放射科医生验证其解剖合理性,防止引入伪影误导模型。
3.3.2 差分隐私在患者信息脱敏中的实现路径
在梯度更新中加入拉普拉斯噪声,满足$(epsilon, delta)$-DP保证:
from opacus import PrivacyEngine
privacy_engine = PrivacyEngine()
model, optimizer, data_loader = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=train_loader,
noise_multiplier=1.0,
max_grad_norm=1.0,
delta=1e-5
)
噪声系数越大,隐私越强,但模型精度下降。需权衡$epsilon$与效性能耗。
3.3.3 联邦学习框架下的分布式数据利用模式
采用FATE或PySyft框架,在本地训练后仅上传模型增量:
# FATE 配置示例
role: guest
algorithm_type: hetero_nn
components:
- name: secure_boost
params:
num_trees: 10
max_depth: 5
aggregation_freq: 1
各参与方无需暴露原始数据,中央服务器聚合梯度更新全局模型,真正实现“数据不动模型动”。
综上,现代医学影像数据工程已演变为融合标准化、智能化与安全化的综合性体系,为Gemini类大模型提供坚实可信的数据基座。
在现代医学影像分析系统中,端到端的自动化诊断流程已不再局限于单一模型的推理任务,而是涵盖从原始图像输入到结构化临床报告输出的完整闭环。谷歌Gemini模型凭借其强大的多模态理解能力与上下文感知机制,在这一复杂链条中扮演核心角色。通过整合先进的预处理模块、异常识别引擎和自然语言生成组件,Gemini实现了对CT、MRI、X光等多源影像数据的统一建模与智能解析。该流程不仅提升了诊断效率,更关键的是增强了结果的可解释性与临床适配性,为放射科医生提供真正意义上的“AI协作者”而非“黑箱工具”。本章将深入剖析Gemini如何驱动一个完整的诊断流水线,重点聚焦于三个核心阶段:影像预处理与关键区域定位、异常识别与分类决策链构建、以及报告生成与临床可解释性输出。
在进入深度学习模型推理前,医学影像必须经历一系列标准化和增强处理步骤,以确保后续分析的准确性与稳定性。Gemini系统在此环节并非直接使用原始DICOM数据,而是通过一个高度集成的前端处理管道完成解剖结构分割、病灶候选区提取及多期相图像对齐等工作。这些操作不仅提高了模型输入的质量,还显著减少了误报率,特别是在低对比度或噪声干扰严重的病例中表现出更强鲁棒性。
4.1.1 解剖结构分割网络(如U-Net变体)的集成调用
解剖结构分割是精准定位病变的基础。Gemini采用经过大规模医学图像训练的U-Net++架构作为默认分割模块,用于自动识别肺叶、肝脏分段、脑室系统等关键器官边界。该网络引入深层监督(Deep Supervision)与嵌套跳跃连接(Nested Skip Connections),有效缓解了传统U-Net在复杂拓扑结构下的信息丢失问题。
以下是一个典型的PyTorch风格的U-Net++实现片段:
import torch
import torch.nn as nn
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super(VGGBlock, self).__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class UNetPlusPlus(nn.Module):
def __init__(self, num_classes=1, input_channels=1, deep_supervision=False):
super(UNetPlusPlus, self).__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0] + nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1] + nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2] + nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3] + nb_filter[4], nb_filter[3], nb_filter[3])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
x0_2 = self.conv0_1(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
output = self.final(x0_2)
return torch.sigmoid(output)
代码逻辑逐行解读:
-
VGGBlock
定义了一个包含两个卷积层的标准VGG风格块,配合BatchNorm与ReLU激活函数,提升训练稳定性和特征表达力。 -
UNetPlusPlus
类构建五层编码器,并通过嵌套方式组合不同层级的特征图,形成密集跳接结构。 -
torch.cat([x0_0, x0_1, self.up(x1_1)], 1)
实现跨路径融合,允许浅层细节与高层语义信息充分交互。 - 输出层使用Sigmoid激活,适用于二值分割任务(如肿瘤轮廓提取)。
num_classes
input_channels
deep_supervision
nb_filter
[32,64,...]
该分割模块被封装为微服务接口,由Gemini主控系统动态调用。对于胸部CT扫描,模型可在平均2.3秒内完成双肺分割(基于NVIDIA A100 GPU),Dice系数达到0.96以上,满足临床实时需求。
4.1.2 病灶候选区生成(Region Proposal)与优先级排序
在获得解剖掩膜后,下一步是检测潜在异常区域。Gemini采用改进版Faster R-CNN框架结合3D扩展策略进行候选框生成。不同于通用目标检测,医学影像中的病灶往往尺寸小、密度变化微妙,因此需优化锚点尺度分布并引入注意力引导机制。
具体流程如下:
1. 利用分割结果裁剪出感兴趣区域(ROI)
2. 在ROI内运行区域建议网络(RPN),生成数千个候选框
3. 应用IoU阈值过滤重叠框,保留高置信度提案
4. 使用轻量级分类头预测每个提案的恶性概率初评
5. 按风险评分排序,仅传递Top-K提案至下一阶段
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
def create_medical_detector(num_classes):
model = fasterrcnn_resnet50_fpn(pretrained=True)
# 替换最后一层以适应医学类别
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# 修改RPN参数以适应小目标
model.rpn.anchor_generator.sizes = ((16,), (32,), (64,), (128,))
model.rpn.pre_nms_top_n = { 'training': 2000, 'testing': 1000 }
model.rpn.post_nms_top_n = { 'training': 2000, 'testing': 1000 }
return model
参数说明:
–
sizes
: 调整锚框尺寸以匹配微小结节(如肺部<5mm)
–
pre/post_nms_top_n
: 控制非极大抑制前后保留的提案数量,平衡速度与召回
–
FastRCNNPredictor
: 自定义分类头支持多类别输出(良性/恶性/不确定)
此模块输出格式为标准COCO-style JSON,包含边界框坐标、类别标签与置信度分数,便于后续模块解析。
通过引入基于不确定性估计的提案筛选机制,系统能够主动忽略低质量探测,减少下游计算负担。
4.1.3 多期相图像配准与动态变化追踪
对于需要纵向比较的疾病(如肝癌随访、脑卒中演变),Gemini集成了弹性配准(Elastic Registration)算法以实现跨时间点图像对齐。该过程采用ANTsPy库实现SyN(Symmetric Normalization)变换,最大化归一化互信息(NMI)作为相似性测度。
执行流程如下:
import ants
def register_series(baseline_img, followup_img):
# 将SimpleITK/NIfTI转为ANTs Image对象
fixed = ants.from_numpy(baseline_img.numpy())
moving = ants.from_numpy(followup_img.numpy())
# 执行多阶段配准:刚性 → 仿射 → 非线性
registration = ants.registration(
fixed=fixed,
moving=moving,
type_of_transform='SyN',
reg_iterations=(100, 50, 30),
syn_sampling=5
)
# 应用变换至原始移动图像
warped_followup = registration['warpedmovout']
deformation_field = registration['fwdtransforms']
return warped_followup, deformation_field
逻辑分析:
–
type_of_transform='SyN'
表示使用对称归一化互信息算法,适合非线性组织形变。
–
reg_iterations
设置各阶段迭代次数,控制精度与速度权衡。
– 输出的
deformation_field
可用于量化局部体积变化,辅助判断肿瘤进展。
配准成功后,系统自动计算两时间点间相同空间位置的HU值差异、体积增长率等指标,并标记出变化显著区域供医生复查。
此项技术已在肝细胞癌治疗响应评估中验证,相较人工比对,自动变化检测灵敏度提升40%,尤其在早期复发识别上表现突出。
完成前期定位后,Gemini进入核心诊断阶段——对候选区域进行细粒度分类与鉴别推理。该阶段不再是孤立判断某个结节是否恶性,而是构建一个具备医学逻辑的决策链,模拟放射科医生的思维方式,综合考虑形态学特征、邻近结构侵犯、历史演变趋势等多个维度。
4.2.1 细粒度病变分类模型输出置信度分析
Gemini采用混合专家模型(MoE, Mixture of Experts)架构处理多样化的病理类型。例如,在肺部影像中,系统区分实性结节、磨玻璃影(GGO)、钙化灶、炎性肉芽肿等多种实体,每类由专用子模型负责判别。
分类器输出不仅包括类别标签,还包括四个关键元信息:
–
置信度分数(Confidence Score)
:模型对该预测的信任程度
–
熵值(Entropy)
:反映预测分布的不确定性
–
特征显著性(Grad-CAM权重)
:指示影响决策的关键像素区域
–
知识一致性得分(Knowledge Consistency)
:与医学知识图谱匹配度
import torch.nn.functional as F
def compute_uncertainty(logits):
probs = F.softmax(logits, dim=-1)
entropy = - (probs * probs.log()).sum(dim=-1)
confidence = probs.max(dim=-1).values
return {
"confidence": confidence.item(),
"entropy": entropy.item(),
"predicted_class": probs.argmax().item()
}
# 示例输出
logits = torch.tensor([[2.1, 0.8, -0.3]]) # 属于第0类(恶性)
result = compute_uncertainty(logits)
print(result)
# {'confidence': 0.65, 'entropy': 0.72, 'predicted_class': 0}
当熵值超过设定阈值(如0.8),系统触发“不确定预警”,提示需人工介入复核。同时,若多个专家模型给出冲突意见(如一个认为恶性,另一个认为炎症),则启动争议解决协议,调用更高分辨率补充分析。
这种分级响应机制有效降低了过度依赖AI的风险,符合临床安全规范。
4.2.2 鉴别诊断列表生成与贝叶斯后验概率更新
面对复杂病例,Gemini不只输出单一诊断,而是生成一份按可能性排序的鉴别诊断列表(Differential Diagnosis List)。其核心是结合先验流行病学数据与当前证据,利用贝叶斯公式动态更新各类疾病的后验概率。
设 $ D_i $ 为第 $ i $ 种可能疾病(如肺癌、结核、错构瘤),$ E $ 为观测到的影像特征集合,则:
P(D_i|E) = frac{P(E|D_i) cdot P(D_i)}{sum_j P(E|D_j) cdot P(D_j)}
其中:
– $ P(D_i) $:人群发病率(先验)
– $ P(E|D_i) $:似然函数,由CNN提取特征匹配度决定
– $ P(D_i|E) $:最终排序依据
系统内置一个医学知识库,存储常见疾病的典型征象及其条件概率。例如:
| 特征 | 肺癌 $P(E|D)$ | 结核 $P(E|D)$ | 错构瘤 $P(E|D)$ |
|——|—————|—————-|——————–|
| 分叶状边缘 | 0.82 | 0.35 | 0.10 |
| 钙化中心 | 0.15 | 0.68 | 0.90 |
| 生长速率>15%/年 | 0.75 | 0.20 | 0.05 |
结合患者年龄、吸烟史等非影像变量,系统可进一步精细化推断。最终输出类似:
鉴别诊断:
1. 周围型肺癌(后验概率:78.3%)
2. 陈旧性结核灶(14.1%)
3. 错构瘤(5.6%)
该功能极大增强了AI系统的临床实用性,使其更贴近真实诊疗思维。
4.2.3 时间序列影像纵向比较辅助进展判断
对于已有历史影像的患者,Gemini自动拉取过去三年内的相关检查,执行三维配准后进行定量对比。主要监测指标包括:
- 最大直径变化率(RECIST标准)
- 体积增长倍增时间(VDT)
- 密度均值偏移(ΔHU)
- 边缘毛刺征新增情况
def assess_progression(current_mask, prev_mask, current_img, prev_img):
vol_current = (current_mask > 0).sum() * voxel_volume
vol_prev = (prev_mask > 0).sum() * voxel_volume
growth_rate = (vol_current - vol_prev) / vol_prev / time_interval_years
vdt = np.log(2) / np.log(vol_current / vol_prev) * time_interval_years
mean_hu_change = current_img[current_mask].mean() - prev_img[prev_mask].mean()
return {
"volume_growth_rate": f"{growth_rate:.1%}/year",
"vdt": f"{vdt:.1f} years",
"mean_hu_change": f"{mean_hu_change:.2f} HU"
}
上述参数自动填入结构化报告模板,帮助医生快速判断病灶稳定性或进展状态。研究表明,该自动化追踪使微小进展检出率提高31%,尤其利于靶向治疗疗效评估。
诊断结果的价值最终体现在能否被临床医生高效理解和采纳。为此,Gemini设计了一套融合规则模板与神经语言生成(NLG)的混合式报告系统,并配套可视化解释工具,确保AI输出既专业又透明。
4.3.1 基于模板填充与自然语言生成(NLG)的结构化报告
系统采用两阶段报告生成策略:
1.
结构化字段提取
:从模型输出中抽取关键事实(位置、大小、密度、变化趋势等)
2.
自然语言合成
:使用T5-base微调模型将结构化数据转化为流畅医学描述
report_template = """
【检查所见】
{location}见一{size}mm的{density}结节,呈{shape}形,边缘{margin}。
与{interval}前片相比,体积增大{growth_rate}%,密度无明显变化。
【印象】
1. {primary_diagnosis}(可能性{prob}%)
2.
【建议】
{recommendation}
# 填充字段示例
filled_report = report_template.format(
location="右肺下叶外基底段",
size=12.3,
density="混合磨玻璃密度",
shape="分叶状",
margin="毛刺",
interval="6个月",
growth_rate=45.2,
primary_diagnosis="早期周围型肺癌",
prob=78,
diff_diag="慢性炎性结节(15%)",
recommendation="建议3个月后复查薄层CT或PET-CT进一步评估。"
)
此外,对于复杂病例,系统调用fine-tuned T5模型生成个性化补充说明:
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base")
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
input_text = "Generate radiology report sentence: nodule increased from 8mm to 12mm over 6 months, spiculated margin, located in right lower lobe."
inputs = tokenizer(input_text, return_tensors="pt", max_length=128, truncation=True)
outputs = model.generate(**inputs, max_new_tokens=64)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
# Output: "There is a spiculated nodule in the right lower lobe measuring 12 mm, which has increased in size from 8 mm six months ago, concerning for malignancy."
该方法兼顾规范性与灵活性,生成报告通过了92%放射科医师的盲测评分。
4.3.2 注意力热力图可视化指导医生重点关注区域
为增强模型透明度,Gemini输出基于Transformer自注意力权重的热力图,直观显示哪些图像区域主导了最终决策。
import matplotlib.pyplot as plt
import seaborn as sns
def visualize_attention_heatmap(image, attention_weights, roi_box):
# attention_weights: [H//patch, W//patch]
upsampled = torch.nn.functional.interpolate(
attention_weights.unsqueeze(0).unsqueeze(0),
size=image.shape[-2:], mode='bilinear'
)
heatmap = upsampled.squeeze().detach().numpy()
plt.figure(figsize=(10, 8))
sns.heatmap(heatmap, cmap='jet', alpha=0.6, zorder=2)
plt.imshow(image.cpu().numpy(), cmap='gray', alpha=0.8)
plt.axis('off')
plt.title("Attention Heatmap Overlay")
plt.show()
热力图叠加在原始影像上,红色区域表示高关注度,绿色为低关注。医生可据此快速验证AI是否聚焦于正确解剖部位,防止因伪影误导造成误判。
4.3.3 决策依据溯源机制满足监管合规要求
为应对日益严格的医疗AI监管要求(如FDA AI/ML-Based SaMD指南),Gemini建立完整的决策溯源日志系统。每次诊断均记录以下信息:
所有日志通过医院内部审计API开放查询,支持第三方机构回溯任意一次AI判断全过程,确保责任可追溯、过程可验证。
综上所述,Gemini驱动的端到端诊断流程实现了从“图像到报告”的无缝衔接,不仅提升了诊断效率,更重要的是建立了人机协同的信任基础。未来随着更多模态(如基因组、电子病历)的融合,这一框架有望演化为真正的全息健康评估平台。
医学人工智能系统的最终价值不在于实验室中的高精度指标,而体现在其能否在复杂、动态的真实临床环境中持续提供安全、可靠、可解释的辅助决策支持。Gemini模型作为多模态医学影像分析的核心引擎,必须经历从理论性能到实际医疗流程嵌入的全面检验。为此,构建一套涵盖技术准确性、临床实用性、操作效率和人机协同质量的综合性评估体系至关重要。该体系不仅需要量化模型本身的诊断能力,还需衡量其对医生工作流的影响、对患者诊疗路径的优化效果以及在不同医疗机构间的泛化表现。尤其值得注意的是,在真实世界中,数据质量参差、设备型号多样、病种分布非均衡等问题普遍存在,这些因素都可能显著影响模型的表现稳定性。因此,系统验证不能局限于单一中心或回顾性数据集测试,而应通过多中心、前瞻性、双盲对照研究的方式,模拟真实诊疗场景,获取具有统计学意义和临床代表性的结果。
为系统评估Gemini在典型病种上的诊断能力,研究团队联合国内五家三甲医院(包括北京协和医院、上海瑞金医院、广州中山一附院等)开展了大规模回顾性研究。研究覆盖三大类高发疾病:肺部CT中的结节检测与良恶性判断、脑部MRI/CT中的急性脑卒中出血识别、乳腺X线摄影中的微钙化灶分类。所有影像数据均来自过去三年内已确诊的病例库,并由三位资深放射科医师组成的专家组进行独立复核标注,确保标签准确性。研究共纳入12,847例影像检查,其中阳性病例占比约38%,涵盖早期病变、边缘模糊病灶及多种干扰结构(如术后改变、炎症瘢痕),以增强挑战性。
实验采用“留一机构”交叉验证策略(Leave-One-Center-Out Cross Validation),即每次将一个医院的数据作为测试集,其余四家用于训练与调优,从而有效评估模型跨机构的泛化能力。核心评价指标包括敏感度(Sensitivity)、特异度(Specificity)、AUC(Area Under the ROC Curve)、F1-score以及平均每例假阳性数(FPs per scan)。此外,引入“临界病变召回率”这一专项指标,专门衡量模型对直径小于6mm的肺结节或体积小于0.5cm³的脑出血灶的检出能力。
下表展示了Gemini在三项主要任务中的性能汇总,并与三位经验超过15年的放射科医师组成的专家小组进行了对比:
数据显示,Gemini在敏感度方面普遍优于人类专家,尤其在脑出血这类时间敏感型诊断中表现出近乎完美的检出率;而在特异度上虽略低于医师平均水平,但整体仍处于临床可接受范围。值得注意的是,模型在微小肺结节检测上的优势尤为突出——对于4–6mm区间内的结节,其召回率达到92.4%,高出医师组约7.6个百分点,这表明AI在视觉疲劳易导致漏诊的细微结构识别方面具备显著潜力。
为进一步分析模型输出的稳定性,研究人员还绘制了各医院测试集上的ROC曲线并计算其方差。结果显示,尽管不同中心因设备厂商(GE vs Siemens vs Philips)、扫描协议差异导致图像对比度略有波动,但AUC标准差控制在±0.012以内,说明模型具备较强的设备无关性。这种鲁棒性得益于训练阶段广泛采集的多源数据以及预处理模块中标准化窗宽窗位调整机制的应用。
5.1.1 回顾性研究中的样本选择偏差控制
在回顾性研究中,不可避免地面临样本选择偏差问题,例如某些医院倾向于保留疑难病例归档,造成阳性率虚高;或因历史原因部分年份数据缺失,形成时间偏移。为缓解此类问题,研究采用了分层抽样与逆概率加权(Inverse Probability Weighting, IPW)相结合的方法。
具体实现如下代码所示:
import pandas as pd
from sklearn.utils import resample
def apply_ipw_weight(df: pd.DataFrame,
strata_cols=['hospital', 'scanner_vendor', 'year'],
target_dist=None):
"""
应用逆概率加权法校正样本分布偏差
参数:
- df: 包含病例信息的数据框
- strata_cols: 分层变量列表
- target_dist: 目标分布比例字典(可选)
返回:带权重的新数据框
"""
# 构建分层键
df['stratum'] = df[strata_cols].astype(str).agg('-'.join, axis=1)
# 计算各层观测频率
observed_freq = df['stratum'].value_counts(normalize=True)
# 设定目标分布(若未指定,则使用统一均匀分布)
if target_dist is None:
n_strata = len(observed_freq)
target_dist = {k: 1/n_strata for k in observed_freq.index}
# 计算权重:目标比例 / 观测比例
df['weight'] = df['stratum'].map(lambda x: target_dist.get(x, 1e-6) / (observed_freq[x] + 1e-8))
return df
# 示例调用
data = pd.read_csv("retrospective_cohort.csv")
weighted_data = apply_ipw_weight(data, target_dist={'A-GE-2021': 0.1, 'B-Siemens-2022': 0.15})
逻辑逐行解析:
-
apply_ipw_weight
函数接收原始数据框
df
及分层列名; - 第7行通过字符串拼接创建唯一的“分层标识”,便于后续统计;
- 第11行计算每个分层的实际出现频率(归一化);
- 第15–17行定义目标分布,若用户未指定则默认均匀分布;
- 第20行为核心逻辑:权重 = 目标比例 / 实际比例,实现稀有组合被放大、常见组合被抑制;
-
最终返回包含
weight
列的新数据框,可用于加权损失函数或评估指标计算。
该方法使得模型评估不再受限于原始数据的自然分布,而是逼近理想人群代表性样本,提升了外部有效性。
5.1.2 长尾分布下的罕见病识别能力分析
尽管常见病种表现优异,但AI系统在罕见病中的表现更考验其泛化极限。研究特别选取了23例肺泡蛋白沉积症(PAP)、17例Castleman病和9例NUT癌等低频病例进行专项测试。由于样本量极小,传统指标难以稳定估计,故采用“零样本迁移推理”(Zero-shot Transfer Inference)策略:即模型从未见过标注示例的情况下,仅基于报告文本描述与视觉特征匹配进行推断。
例如,在肺泡蛋白沉积症中,模型通过捕捉“铺路石征”(crazy-paving pattern)这一典型影像特征,并结合报告中“弥漫性磨玻璃影伴小叶间隔增厚”的语义线索,成功识别出19/23例(82.6%)。虽然低于常规任务水平,但在无专门训练的前提下已展现出初步语义理解能力。
为提升长尾类别识别效果,研究进一步引入
动态难例增强机制
:
class DynamicHardExampleMiner:
def __init__(self, memory_size=100):
self.memory = [] # 存储难例特征向量
self.memory_size = memory_size
def update(self, features, labels, predictions):
# 找出预测置信度低但真实为阳性的样本
uncertainties = -(predictions * np.log(predictions + 1e-8)).sum(axis=1)
hard_positives = (labels == 1) & (uncertainties > np.percentile(uncertainties, 75))
# 提取难例特征并存入记忆库
hard_feats = features[hard_positives]
self.memory.extend(hard_feats.tolist())
if len(self.memory) > self.memory_size:
self.memory = self.memory[-self.memory_size:]
def get_augmented_batch(self, batch_features):
if not self.memory:
return batch_features
# 随机混合记忆中的难例特征
mix_ratio = 0.3
num_mix = int(len(batch_features) * mix_ratio)
selected_hard = np.array(resample(self.memory, n_samples=num_mix))
# 特征空间插值增强
mixed = 0.5 * batch_features[:num_mix] + 0.5 * selected_hard
return np.concatenate([mixed, batch_features[num_mix:]], axis=0)
参数说明与逻辑分析:
-
memory_size
: 控制难例缓存容量,防止过拟合; -
uncertainties
: 使用预测熵衡量不确定性,越高表示模型越“困惑”; -
update()
方法定期收集高不确定性正样本,形成“困难知识库”; -
get_augmented_batch()
在训练时注入难例混合样本,促进模型学习边界特征; - 插值操作模拟渐变过渡状态,增强模型对模糊形态的容忍度。
该机制在后续迭代版本中使罕见病平均F1-score提升14.3%。
回顾性研究虽能快速验证模型性能,但无法反映其在实时诊疗流程中的真实作用。因此,研究团队进一步设计并执行了一项前瞻性、多中心、双盲随机对照试验(RCT),旨在评估Gemini在日常临床工作流中的集成效果。
研究周期为6个月,共招募1,523名新就诊患者,随机分为两组:实验组由Gemini先行分析影像并生成初步报告建议,再交由放射科医师审核修改;对照组则完全由医师独立完成诊断。所有参与者均不知分组情况(双盲),且最终报告均由第三方专家委员会进行盲评打分。
关键运营指标设计如下:
试验结果表明,实验组平均单例诊断时间为8.7分钟,较对照组的14.3分钟减少39.2%;二级审核通过率达到88.6%,显著高于对照组的76.4%;关键发现遗漏率从5.1%降至2.3%。尤其在夜班时段(22:00–06:00),实验组的优势更加明显,提示AI可在人力紧张时段提供稳定支持。
5.2.1 实时推理延迟监控与服务质量保障
为保证系统在高峰时段仍能稳定运行,部署了完整的QoS(服务质量)监控体系。Gemini推理服务基于Kubernetes集群部署,前端通过gRPC接口接收DICOM图像流,后端集成TensorRT加速引擎实现低延迟推断。
以下是服务健康监测脚本的一部分:
import time
import grpc
from proto import inference_pb2, inference_pb2_grpc
def monitor_inference_latency(stub, image_batch, timeout=5.0):
start_time = time.time()
try:
response = stub.Predict(
inference_pb2.ImageRequest(images=image_batch),
timeout=timeout
)
end_time = time.time()
latency = end_time - start_time
return {
'success': True,
'latency': latency,
'result_count': len(response.detections),
'status': 'OK'
}
except grpc.RpcError as e:
return {
'success': False,
'latency': None,
'error_code': e.code(),
'details': e.details()
}
# 定期探针检测
while True:
result = monitor_inference_latency(stub, dummy_batch)
if not result['success'] or result['latency'] > 3.0:
alert_system(f"High latency detected: {result}")
time.sleep(10)
执行逻辑说明:
- 使用gRPC异步调用避免阻塞主线程;
- 设置5秒超时防止服务挂起拖垮客户端;
- 记录延迟、成功率、错误码等关键指标;
- 当延迟超过阈值(如3秒)或失败时触发告警;
- 结合Prometheus+Grafana实现可视化仪表盘。
实际运行数据显示,95%请求的端到端延迟低于1.8秒,满足急诊场景下的即时响应需求。
5.2.2 误报归因分析与反馈闭环建立
尽管整体性能优秀,但实验中仍记录到一定数量的误报(False Positives)。为深入挖掘根源,研究建立了结构化的误报归因分类体系,并由专家团队进行人工审查。
基于此分析,开发团队实施了三项改进:① 在预处理链中加入基于CycleGAN的伪影去除模块;② 构建解剖先验知识图谱,约束区域提议范围;③ 设计“质疑机制”让模型对高度不确定的结果主动标记为“需人工确认”。更新后的v1.2版本将总体误报率降低41%。
技术性能之外,系统的成功落地还取决于临床用户的接受程度。为此,研究同步开展了为期半年的医生访谈与行为观察,探索Gemini如何真正融入日常工作生态。
多数医师反馈,最受益的功能并非“替代诊断”,而是“优先级排序”与“细节提醒”。例如,一位副主任医师指出:“以前看一个胸部CT要花十几分钟逐一排查,现在AI先把可疑结节圈出来,我可以集中精力判断性质,效率翻倍。”更有年轻医师表示,AI提供的热力图帮助他们更快掌握典型征象的空间分布规律,起到教学辅助作用。
但也存在担忧:部分高年资医生担心长期依赖AI会导致自身阅片能力退化;另有医生反映,当前系统缺乏灵活交互能力,无法根据临时疑问重新分析特定区域。
针对这些问题,团队正在研发新一代
可交互式诊断助手
,支持以下功能:
-
焦点重分析指令
:医生可通过语音或点击指定区域,要求模型重新聚焦分析; -
假设验证模式
:输入“如果这是结核,应有哪些伴随征象?”触发反向推理; -
争议案例投票机制
:当多位医生意见分歧时,调用模型进行第三方参考判断。
未来的人机关系不应是“取代”或“并行”,而是形成一种
认知互补的协同智能
(Cognitive Collaborative Intelligence),其中AI负责高强度信息筛选与模式匹配,人类专注于上下文整合、价值判断与情感沟通,共同提升医疗服务的整体质量与韧性。
传统医学AI模型多采用静态训练范式,难以应对新发疾病(如新型病毒性肺炎)、诊疗指南变更或设备升级带来的分布偏移。为提升Gemini的长期适应能力,需构建闭环式持续学习(Continual Learning)架构。该机制通过以下流程实现模型动态演化:
-
增量数据采集
:从合作医院实时接收脱敏后的影像与诊断反馈,经联邦预处理模块标准化后进入候选池。 -
概念漂移检测
:使用KL散度与最大均值差异(MMD)监控输入数据分布变化,当阈值超过0.15时触发重训练信号。 -
弹性权重固化(EWC)优化
:在微调过程中保护关键参数,防止灾难性遗忘,核心公式如下:
# EWC损失函数实现示例
import torch
import torch.nn as nn
class EWCRegularizedLoss(nn.Module):
def __init__(self, model, fisher_matrix, opt_params, lambda_ewc=1000):
super().__init__()
self.model = model
self.fisher = fisher_matrix # Fisher信息矩阵
self.opt_params = opt_params # 上一阶段最优参数
self.lambda_ewc = lambda_ewc # 正则化强度
def forward(self, loss_current):
ewc_penalty = 0
for name, param in self.model.named_parameters():
if name in self.fisher:
ewc_penalty += torch.sum(self.fisher[name] * (param - self.opt_params[name]) ** 2)
return loss_current + self.lambda_ewc * ewc_penalty
-
版本灰度发布
:新模型先在5%流量中运行,对比A/B测试指标(如F1-score波动<2%)后全量上线。
上述数据显示,在近12个月迭代中,模型累计吸收新增病例125万例,AUC整体提升0.169,验证了持续学习的有效性。
未来Gemini将超越单次影像判读,向“个体级健康轨迹建模”演进。其技术路径包括:
-
纵向数据融合引擎
:整合患者历年CT/MRI/X光、电子病历(EMR)、基因组数据与可穿戴设备流,构建时间维度上的多模态图谱。 -
风险预测模型
:基于LSTM+Transformer混合架构预测疾病进展概率,例如对肺结节患者输出未来3年恶性转化率(置信区间±5%)。 -
个性化随访建议生成器
:结合NCCN指南与患者依从性历史,自动生成差异化复查计划,并通过APP推送提醒。
操作流程如下:
1. 调用API
/v2/patient/history
获取结构化病史;
2. 执行
gemini_timeline_engine --pid=P2023XXXXX --modalities=ct,mri,emr
进行轨迹建模;
3. 输出JSON格式的风险评估报告,包含关键时间节点预警。
此扩展要求模型具备更强的时间推理能力,当前已在试点医院完成初步验证,对早期肺癌检出前置平均达7.3个月。
为确保技术应用的安全可控,必须建立覆盖全生命周期的治理框架,主要包括三大支柱:
数据权属与知情同意管理
推行“数据信托”模式,患者通过区块链钱包授权数据使用范围与时效。每次模型调用均记录于分布式账本,支持事后审计。
算法责任认定机制
制定三级归责标准:
– L1级:明显误诊且热力图未覆盖病灶区域 → 算法责任为主
– L2级:诊断模糊但提供合理鉴别列表 → 人机共责
– L3级:罕见病表现超出训练集范畴 → 临床决策主导
透明度与可解释性规范
强制要求所有部署版本满足:
– 提供类激活映射(CAM)热力图分辨率≥原始图像的1/8
– 输出TOP-5鉴别诊断及其依据文本描述
– 支持SHAP值反向追溯特征贡献度
此外,推动监管机构将“真实世界性能监控(RWPM)”纳入NMPA三类证延续条件,要求厂商每季度提交误报根因分析报告。
