26-02-18,国际顶级期刊《Nature》发表论文《An agentic system for rare disease diagnosis with traceable reasoning》,核心研发团队来自上海交通大学、上海人工智能实验室、上海交通大学医学院附属新华医院、中南大学湘雅医学院附属儿童医院等机构,通讯作者为张娅、余永国、孙锟、谢伟迪。

2026-02-19,国际顶级肿瘤学期刊《Cancer Cell》发表论文《Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis》,由上海交通大学、上海人工智能实验室、上海交通大学医学院附属新华医院等机构的周潇、孙洛伊、何德轩、谢伟迪、王延峰、张娅、孙琨等学者联合完成。

这两篇文章均出自同一个团队,这种发文方式之前基本只会出现在国外的头部课题组;如果没有猜错的话,这两篇文章应该是同时期立项的,或者其中某一个项目是做实验过程中分离出来的。
这里可以多说一嘴,个人认为,目前的研究其实就两个大方向:小/大——如果做【小】研究,就关注小群体,例如这两篇文章的罕见病领域;如果做【大】研究,就关注模型本身的泛化性,例如上面那篇Nature提到的Agent技术,你把它应用的泛癌的研究中。
那篇Nature我在前两天已经写推送详细介绍过了,今天这篇推送,我们来看看这篇病理AI领域的基础模型,是如何和Nature肩并肩同步发表的。
病理诊断始终是癌症诊断的“金标准”,过去十年,深度学习的发展让计算病理学迎来了爆发,AI辅助诊断已经能在部分常见癌症上实现不错的效果。
但行业始终绕不开两个核心死穴:
- 一是标注成本极高,一张病理切片的标注需要资深病理医生耗费数小时,海量标注的门槛让绝大多数机构望而却步;
- 二是纯数据驱动的模型泛化性极差,尤其是在罕见癌症诊断上,因为训练数据稀缺,模型只会“死记硬背”见过的切片,遇到没学过的亚型就彻底失灵,零样本诊断能力几乎为零。
即便是此前行业顶尖的病理视觉语言大模型,也没能跳出这个局限。
它们大多用公开的病理图文对做简单的对比学习,就像教孩子认字只记图片和字形,却不教字义、词根和组词逻辑,最终只能认得见过的字,遇到生僻字就束手无策。
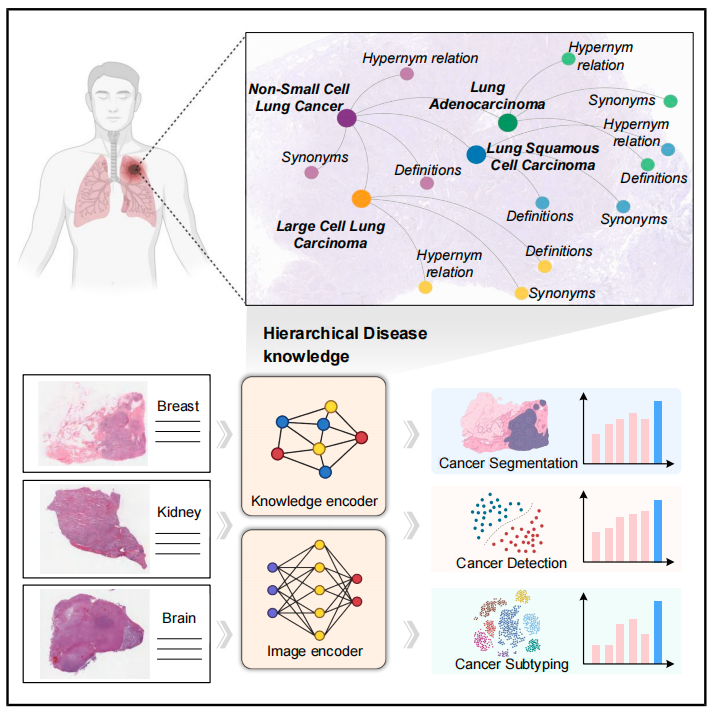
来自上海交通大学、上海人工智能实验室、上海交通大学医学院附属新华医院等机构的团队,研发出了KEEP(KnowledgE-Enhanced Pathology,知识增强病理大模型),这套首次将层级化疾病知识系统融入视觉语言预训练的病理基础模型,不仅在18个公开基准测试上全面领跑,更在罕见癌症诊断上实现了碾压式的性能突破,让病理AI真正从“刷题机器”变成了“懂医学知识的智能助手”。
KEEP模型的全链路逻辑:
- 先构建权威疾病知识体系
- 用知识引导模型训练与数据治理
- 落地到临床病理诊断全流程
- 通过海量基准测试验证性能
核心创新是把层级化医学知识系统性注入病理视觉语言大模型,解决了传统纯数据驱动模型泛化性差、罕见癌诊断失灵的行业痛点。
子图A:构建的疾病知识图谱示例
这是KEEP模型的知识根基,也是整个研究最核心的创新源头,展示了论文中构建的层级化疾病知识图谱的底层结构。
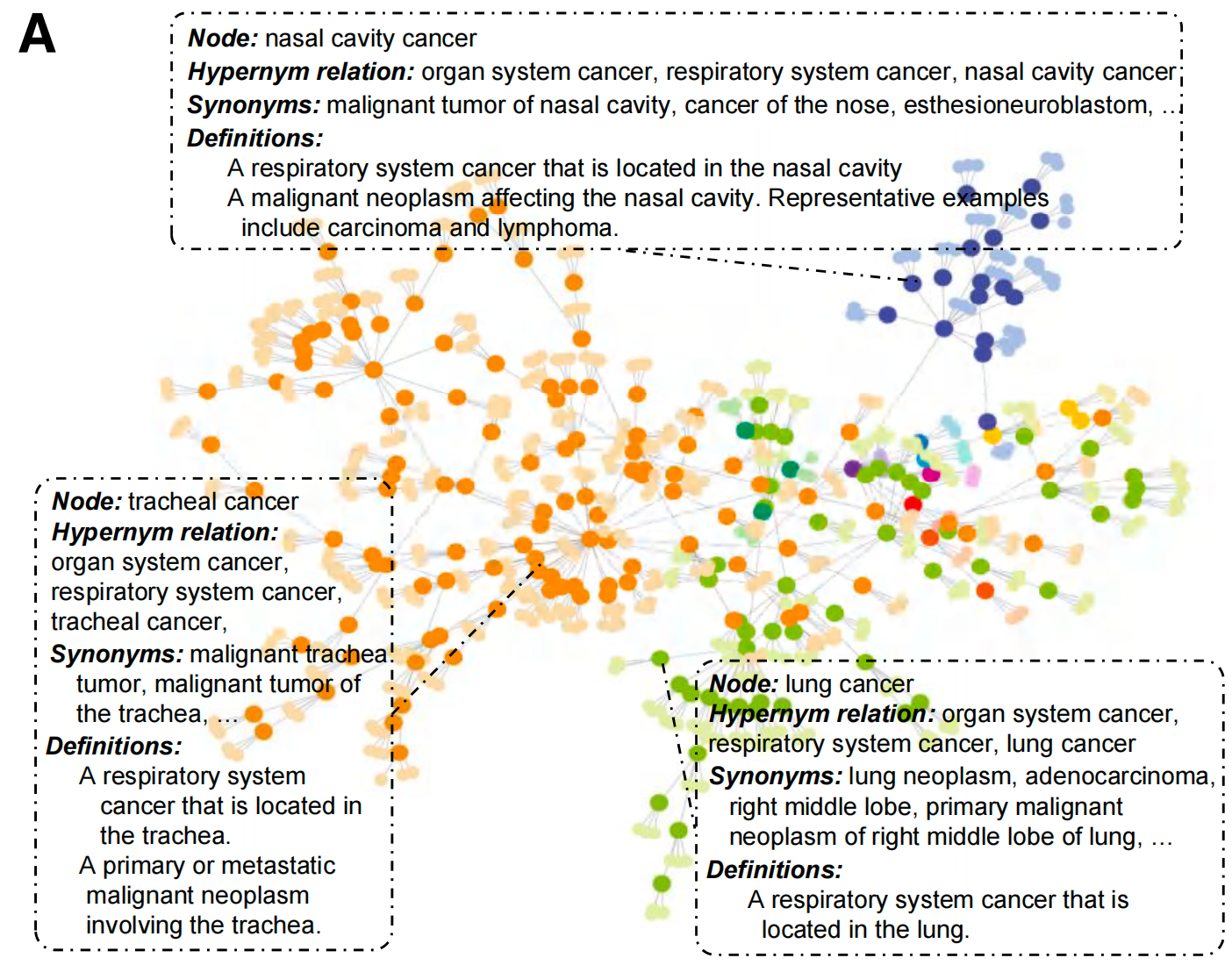
图中每一个彩色节点代表一个疾病实体,整个图谱最终整合了11454种人类疾病,每个疾病节点都包含三大核心医学属性(虚线框标注):
- 层级关系(Hypernym relation):疾病的从属/父子关系,比如示例中的鼻腔癌、气管癌、肺癌,都归属于“呼吸系统癌症→器官系统癌症”的层级链条,完整还原了医学上的疾病分类体系,论文中该图谱共包含15938组疾病上下位关系。
- 同义词(Synonyms):同一个疾病的不同医学表述,比如鼻腔癌的同义词包括“鼻腔恶性肿瘤、嗅神经母细胞瘤”等,解决了病理文本中疾病表述不统一的问题,图谱共收录108902个疾病同义词。
- 定义(Definitions):疾病的权威医学定义,比如鼻腔癌的定义为“位于鼻腔的呼吸系统癌症,代表性类型包括癌和淋巴瘤”,所有定义均来自权威医学数据库,图谱共收录14303条疾病定义。
传统病理大模型仅靠“病理图片-文本描述”的配对死记硬背,而KEEP先让模型学透完整的疾病知识体系,搞懂疾病之间的关联、医学定义与规范表述,从根源上让模型“理解医学”,而非单纯拟合数据。
子图B:KEEP模型的知识编码与视觉-语言对齐阶段
这张图展示了KEEP模型从知识编码到预训练的完整技术流程,分为三个环环相扣的核心步骤,完整还原了论文的模型架构设计:
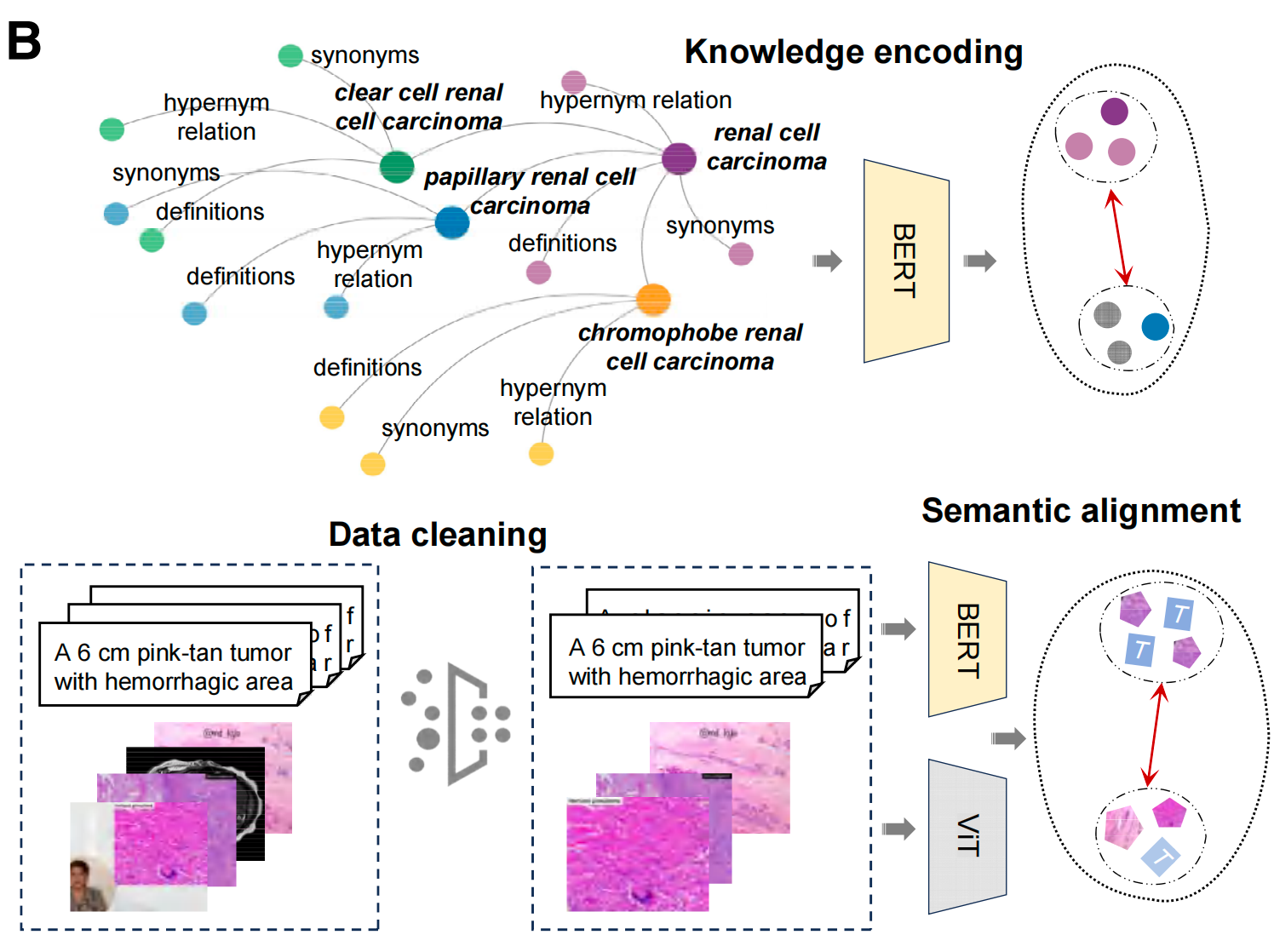
第一步:Knowledge encoding(知识编码)
- 输入:子图A中构建的疾病知识图谱,以肾癌的3种亚型为示例,每个亚型都有对应的同义词、定义、层级关系。
- 方法:采用基于BERT的文本编码器(论文中使用医学领域预训练的PubMedBERT),通过度量学习训练这个知识编码器。
- 目标:让同一个疾病的所有属性(同义词、定义、层级链条)在向量空间中紧密聚合,不同疾病的表征清晰区分(右侧可视化中,同一疾病的不同属性点被聚合到一起),让模型先学会精准的疾病语义表征。
第二步:Data cleaning(知识引导的数据清洗)
- 背景:公开病理图文数据集(OpenPath、Quilt1M)存在大量噪声,包括非病理图片、和图片无关的文本、不规范的标注。
- 操作:以知识图谱为引导,先微调YOLOv8过滤掉非病理图片,再提取文本中的医学实体,和知识图谱里的疾病、同义词做匹配,删除无医学实体的无效文本,把杂乱的百万级图文对,整理为纯净的、和疾病精准绑定的图文数据。
第三步:Semantic alignment(语义对齐)
- 操作:把清洗后的图文数据,按知识图谱的疾病层级关系重组成14.3万个语义组;用预训练好的知识编码器作为文本编码器,搭配病理视觉编码器,做知识增强的视觉-语言预训练。
- 核心创新:传统模型是简单的“单图-单文本”对比学习,而KEEP是语义组级别的对齐,同时通过知识图谱消除假阴性(有亲缘关系的疾病不会被当成完全无关的负例),让病理图像的视觉特征,和疾病的医学语义实现深度绑定。
子图C:下游癌症诊断任务
这张图明确了KEEP模型能覆盖的三大核心临床病理任务,也是病理AI最核心的落地场景,证明KEEP是一个通用型病理基础模型,而非单一任务模型:
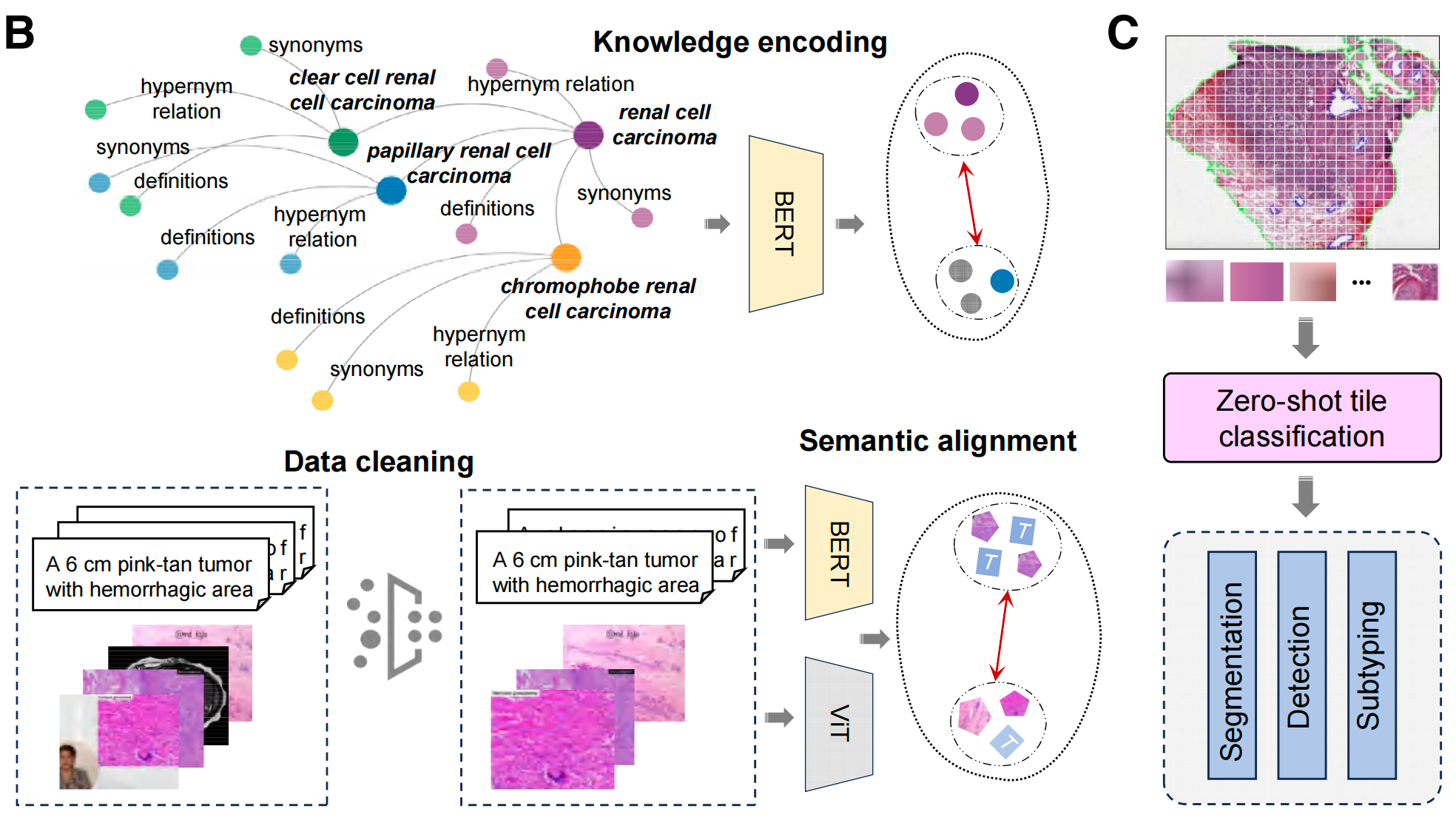
输入:将整张病理全切片(WSI)切分后的小图块(tile),先通过KEEP完成零样本图块分类。
三大核心任务:
- Segmentation(分割):精准圈定病理切片中的癌细胞区域(感兴趣区域ROI),是后续病理分析的基础,传统方法需要大量人工标注,KEEP可零样本完成。
- Detection(检测):判断整张病理切片是否存在癌细胞,即癌症阴阳性诊断,是癌症早筛、初诊的核心环节。
- Subtyping(分型):精准判断癌症的具体亚型(如肺癌分为腺癌/鳞癌),直接决定患者的治疗方案与预后,是精准医疗的核心。
三大任务均支持零样本完成,无需针对每个任务做大量标注和微调,适配临床中多样化的诊断需求。
子图D:癌症诊断的临床工作流
这张图以肺鳞癌诊断为实际案例,一步一步展示了KEEP在真实临床场景中的完整工作流程,完全对应论文中的临床落地设计,分为3个核心步骤:
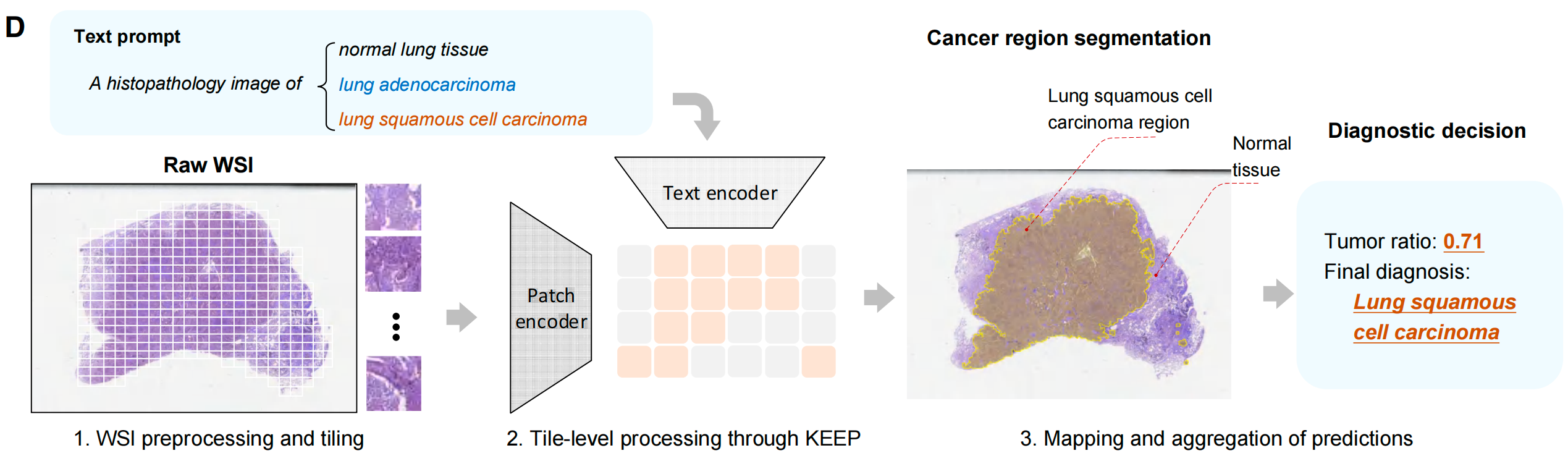
第一步:WSI预处理与分块
- 输入:Raw WSI(原始全切片病理图像),数字化病理切片通常有几十亿像素,无法直接处理。
- 操作:将整张切片在20×放大倍数下,切分为256×256像素的固定大小图块(tile),如同把大地图切分为小方格,方便模型逐个处理。
第二步:通过KEEP完成图块级处理
- 零样本核心:文本提示词(prompt)采用「模板+疾病名称」的固定格式,示例为
A histopathology image of [normal lung tissue/lung adenocarcinoma/lung squamous cell carcinoma](一张[正常肺组织/肺腺癌/肺鳞癌]的组织病理图像)。 - 处理逻辑:用KEEP的文本编码器将提示词编码为语义向量,用视觉编码器将每个图块编码为视觉向量,通过计算两者的相似度,给每个图块完成分类,判断其属于正常组织、肺腺癌还是肺鳞癌。
第三步:预测结果的映射与聚合
- 操作:将每个图块的预测结果映射回原切片的对应位置,生成可视化诊断热力图(黄色为预测的肺鳞癌区域,紫色为正常组织)。
- 诊断决策:计算肿瘤比例(Tumor ratio,癌细胞区域占总组织区域的比例,示例中为0.71),最终给出最终诊断:肺鳞癌。
全程零样本、无任务专属微调,且结果完全可解释——医生可直接看到模型判断的癌细胞区域,而非黑箱式的诊断结果,满足临床落地的核心要求。
子图E:全切片级癌症诊断性能
这是一张多任务雷达图,展示了KEEP在18个公开基准数据集、超14000张全切片图像上,与行业顶尖病理大模型(PLIP、QuiltNet、MI-Zero、CONCH)的性能对比,是论文核心的效果验证:
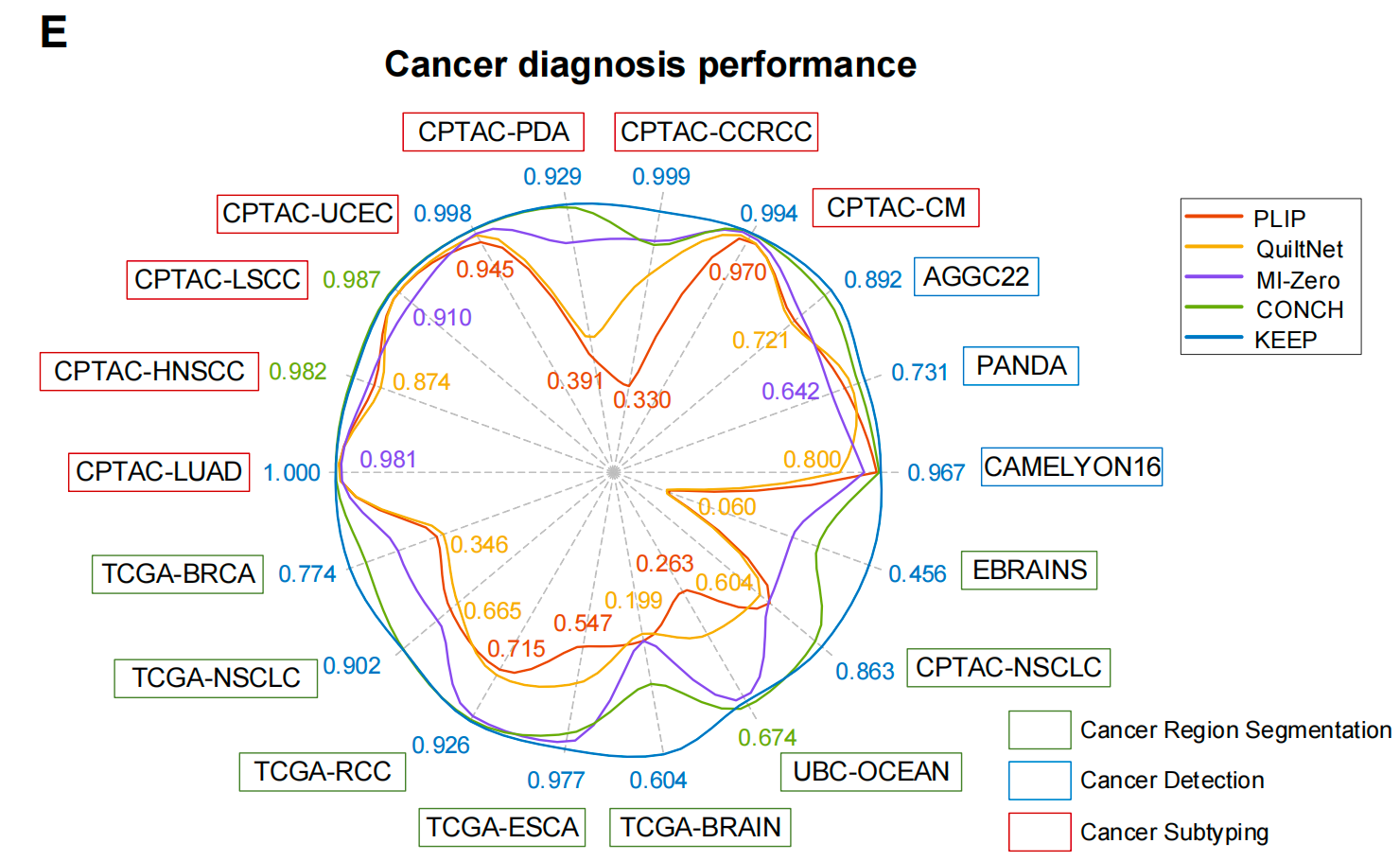
图例与数据集说明:
- 绿色:癌症区域分割任务的数据集,包括CAMELYON16(乳腺癌转移)、PANDA(前列腺癌分级)、AGGC22(前列腺癌Gleason分级)等。
- 蓝色:癌症检测任务的数据集,为7个CPTAC系列数据集,覆盖皮肤、肾、胰腺、子宫、肺、头颈6个部位的癌症。
- 红色:癌症分型任务的数据集,包括TCGA系列的乳腺癌、肺癌、肾癌、食管癌、脑癌,以及UBC-OCEAN(卵巢癌)、EBRAINS(罕见脑癌)等。
核心结果:
- 雷达图中,KEEP的蓝色曲线在绝大多数数据集上都处于最外侧,代表性能全面超越对比模型。
- 关键亮点:
- 癌症检测:95%特异性下,平均灵敏度达到0.898,是传统模型CHIEF的2倍以上,比CONCH高出5.1个百分点;在肺腺癌数据集上实现了1.000的完美AUROC。
- 癌症分型:脑癌分型任务平衡准确率0.604,比CONCH高出15个百分点;30种罕见脑癌分型任务中,比CONCH高出8.5个百分点。
- 癌症分割:在CAMELYON16、AGGC22数据集上,核心指标DICE系数比CONCH分别高出6.8和8.1个百分点。
KEEP在分割、检测、分型三大核心病理诊断任务上,全面超越了当时的行业顶尖模型。
子图F:图块级分类性能
这是一张极坐标雷达图,展示了KEEP在14个图块级病理图像分类基准数据集上的零样本分类性能,验证了模型最基础的视觉特征提取与泛化能力:
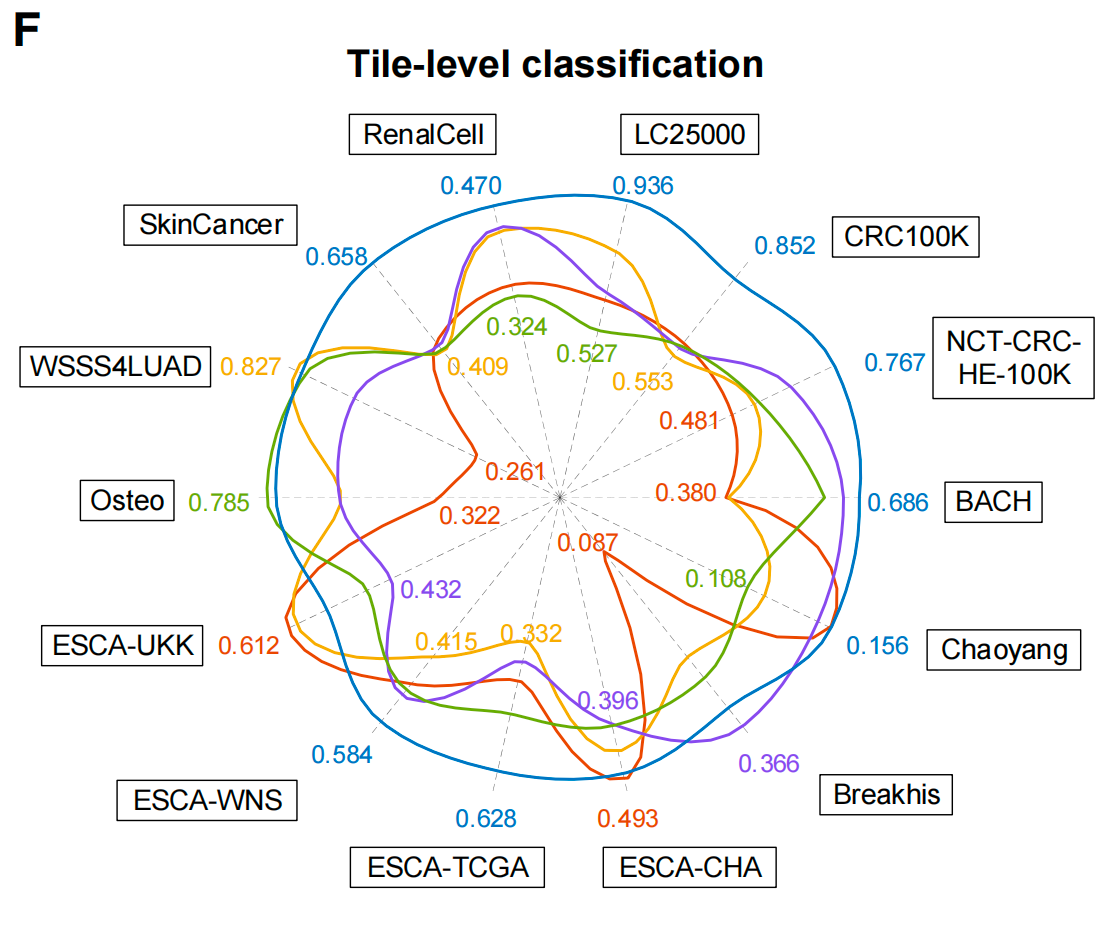
- 数据集说明:覆盖7种人体组织,包括乳腺、结肠、肺、肾、骨、皮肤、食管,每个数据集的分类类别从2到16不等,是病理图像分类的通用基准。
- 坐标轴规则:每个方向对应一个数据集,标注的数字为该数据集上的最佳性能,越靠外代表性能越好;内圈数字为最差结果,外圈为最佳结果。
- 核心结果:
- KEEP在14个数据集中的7个上拿到了最佳性能,全数据集平均性能比MUSK高0.078,比CONCH高0.130,是所有对比模型中平均性能最高的。
- 证明了KEEP不仅在全切片级的临床任务上表现优异,在最基础的图块级病理图像分类上,也具备极强的零样本泛化能力,视觉特征提取能力远超同类模型。
医学AI交流群
目前小罗全平台关注量120,000+,交流群总成员3000+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
团队介绍
罗小罗团队是一支以国内外硕博为主的科研团队,覆盖影像组学、病理组学以及基因组学等医学AI主流研究领域。
980+医学图像公开数据集查询系统,680+医工交叉开源代码仓库,最新的医学AI前沿论坛回放等你来探索!
团队的宗旨是汇聚国内外顶尖人才,构建医学AI生态,推动医学AI从实验室走向临床,期待您的加入!
病理AI一站式分析软件
我们团队针对刚入门病理AI领域的同学/老师,开发了一个一站式软件,可以让大家避免复杂的命令行操作;
如果有需要,可以扫码咨询!
KEEP最核心的突破,是颠覆了传统病理大模型“纯数据驱动”的预训练逻辑,开创了“医学知识+图文数据”双轮驱动的全新范式。
如果说传统模型是“先看切片,再硬记对应的病名”,那KEEP就是“先学透完整的疾病知识体系,再结合切片理解病理特征”;
二者的本质差异,就像业余爱好者靠脸认明星,和专业医生靠解剖学、病理学知识诊断疾病的区别。
想要让AI真正“懂”病理,而非单纯拟合数据,KEEP通过三个环环相扣的核心步骤,把权威医学知识深度注入了模型的“基因”里。
想要教AI诊断疾病,首先要让它搞懂“什么是疾病,疾病之间有什么关系”。
研究团队没有直接让模型去学杂乱的图文数据,而是先整合了国际权威的疾病本体库(DO)和统一医学语言系统(UMLS),构建了一套超大规模的疾病知识图谱。
这套图谱包含了11454种疾病实体,以及139143个对应的疾病属性——其中有108902个疾病同义词、14303条权威疾病定义,还有15938组疾病上下位层级关系。
比如肺鳞癌,不仅有它的别名、定义,还明确了它属于非小细胞肺癌,而非小细胞肺癌又属于肺癌的完整层级链条。
在此基础上,团队基于PubMedBERT训练了专门的知识编码器,通过度量学习让模型学会:同一个疾病的同义词、定义、层级链条,在向量空间里要紧紧靠在一起;不同疾病的表征要清晰分开。
这就像给AI编了一本带完整思维导图的《疾病百科全书》,让它先彻底搞懂疾病的“底层逻辑”,而不是上来就看切片、记特征。
传统病理大模型的训练数据,大多来自公开平台的图文对,这些数据不仅规模远小于通用视觉领域,还充满了噪声:有非病理的影像图片,有和图片无关的文本描述,还有大量不规范、不结构化的标注,就像一本东拼西凑、错漏百出的课堂笔记,AI根本学不到真正有用的知识。
KEEP用提前构建好的知识图谱,给这套“杂乱笔记”做了一次彻底的校对和整理:
- 图像去噪:微调YOLOv8目标检测模型,过滤掉数据集中非病理的图片,最终保留的样本里99.9%都是纯净的病理图像;
- 文本提纯:用自然语言处理工具提取文本里的医学实体,和知识图谱里的疾病、同义词做精准匹配,删掉没有医学实体的无效文本;
- 语义分组:把清洗后的百万级病理图文对,按照疾病的上下位关系,重组成了14.3万个语义结构清晰的分组,让讲同一个疾病、同一类特征的图文对归到一起。
这一步就像把杂乱的错题本,整理成了分章节、分知识点的系统教材,AI学习的时候,再也不会被无效信息干扰,能精准地把病理图像和对应的疾病知识绑定在一起。
有了知识编码器和结构化的数据集,KEEP终于实现了真正的知识增强视觉语言预训练。
团队用预训练好的知识编码器作为文本编码器的初始化权重,用在病理领域经过验证的UNI模型初始化视觉编码器,让图像和文本的对齐,不再是简单的“图片-文字”配对,而是“病理特征-疾病知识”的深度语义对齐。
更巧妙的是,团队针对病理数据的特点,设计了三大训练优化策略:难正例挖掘、最难负例挖掘,还有最关键的假阴性消除。
传统对比学习会把不同疾病的图文对都当成负例,但在医学里,肺腺癌和肺鳞癌都属于非小细胞肺癌,二者有亲缘关系,强行当成完全无关的负例,会让模型学不到疾病之间的关联。
KEEP通过知识图谱里的层级关系,判断两个疾病是否有共同的上位节点,避免把有亲缘关系的疾病当成负例,从根源上解决了假阴性的问题。
这就像老师教学生区分两种相似的疾病,不会让学生把它们当成完全无关的东西,而是先讲清楚它们的共同点和核心区别,让学生理解着去区分,而不是死记硬背两张图片的差异。
也正是这个设计,让KEEP对癌症亚型,尤其是罕见亚型的区分能力,实现了质的飞跃。
研究团队对KEEP做了迄今为止最大规模的病理大模型评估,覆盖了18个国际公开基准测试、超14000张病理全切片图像,还有4个机构内部的罕见癌症数据集(926例病例),涵盖了病理AI三大核心临床任务:癌症区域分割、癌症检测、癌症分型,全面对标了当前行业最顶尖的病理大模型。
所有公开基准测试,团队都采用了最严格的零样本设置——不给模型做任何任务专属的微调,只靠预训练学到的知识和能力完成任务,这最能考验模型的通用能力和泛化性,也最贴近临床里“遇到新病种、新数据集”的真实场景。
在癌症区域分割任务上,KEEP的表现堪称惊艳。
在乳腺癌转移检测的CAMELYON16数据集、前列腺癌分级的PANDA数据集、前列腺癌Gleason分级的AGGC22数据集上,KEEP的DICE系数(衡量分割精准度的核心指标),比当时的行业SOTA模型CONCH分别高出6.8和8.1个百分点;
经过简单的形态学后处理,DICE系数还能再提升3-9个百分点。
这意味着,KEEP能比之前最好的模型,更精准地圈出切片里的癌细胞区域,漏标和误标的概率大幅降低,给病理医生提供的参考也更具临床价值。
在癌症检测任务上,KEEP在7个CPTAC癌症数据集(覆盖皮肤、肾脏、胰腺、子宫、肺、头颈6个部位)的测试中,在95%特异性的临床标准下,平均灵敏度达到了0.898。
这个数字是传统病理大模型CHIEF的2倍多,比CONCH高出5.1个百分点,比MUSK高出4.4个百分点。
通俗来说,就是在保证100个阴性样本里最多只误诊5个的前提下,KEEP能查出近90%的癌症患者,漏诊率远低于此前的所有模型,这在癌症早筛场景里,有着至关重要的临床意义。
在癌症分型任务上,KEEP在7个常见癌症分型数据集中的6个上,都拿到了最好的成绩。
尤其是在脑癌分型任务上,KEEP的平均平衡准确率达到0.604,比CONCH高出15个百分点,比其他模型高出25个百分点。
要知道,癌症分型直接决定了患者的治疗方案,是精准医疗的核心前提,KEEP能在零样本的前提下,实现如此高的分型准确率,已经具备了极强的临床辅助潜力。
更关键的是,团队的消融实验直接证明:仅仅是知识注入这一项设计,就给癌症分割和分型任务带来了平均7.3%和7.2%的性能提升。
这说明KEEP的性能突破,不是靠模型堆料、数据堆砌实现的,而是来自于知识增强的核心创新,这也给整个计算病理学领域,指明了一条全新的发展路径。
罕见癌症的核心痛点,就是病例极少、训练数据稀缺,传统纯数据驱动的模型,根本学不到足够的特征,在零样本场景下基本没有区分能力。
团队用了两类最具挑战性的罕见癌数据集,来验证KEEP的能力:
- 一类是EBRAINS数据集里的30种罕见脑癌,每种亚型仅有30张全切片图像;
- 另一类是上海交通大学医学院附属新华医院的内部数据集,包含816例儿童罕见癌症全切片图像,覆盖神经母细胞瘤、肝母细胞瘤、髓母细胞瘤等临床诊断难度极高的病种。
在30种罕见脑癌的分型任务上,KEEP的平衡准确率达到0.456,是PLIP、QuiltNet等传统模型的4倍多,比CONCH高出8.5个百分点,比MUSK高出15.5个百分点。
要知道,这些罕见脑癌亚型,很多基层病理医生都未必能精准区分,而KEEP在没有经过任何针对性微调的零样本场景下,就能实现如此高的准确率。
在儿童罕见癌症数据集上,KEEP的表现同样亮眼:在神经母细胞瘤、肝母细胞瘤的零样本分型任务上,KEEP显著优于所有对比模型;
即便是只有1-8个训练样本的少样本场景,KEEP也始终保持领跑,在5折交叉验证下,平衡准确率达到0.671±0.085,是所有视觉语言病理模型里的最高水平。
团队在研究中发现了一个极具说服力的细节:传统模型在罕见癌分型任务上,基本会把绝大多数样本都归到同一个亚型里,完全没有区分能力;而KEEP因为提前掌握了完整的疾病知识体系,就算没见过这个罕见病的切片,也能通过它和其他疾病的亲缘关系、定义特征,做出合理的诊断。
这正是KEEP最核心的价值——它让病理AI的零样本能力,从“见过类似图片才能认”,变成了“懂了医学原理就能推断”。
在过去的两年里,整个行业都陷入了“纯数据驱动”的内卷:大家都在拼命堆更大的模型、找更多的图文数据,却始终无法解决标注成本高、泛化性差、罕见病诊断失灵的核心痛点。
而KEEP证明,把权威的医学领域知识,系统性地融入大模型的预训练过程,能以更低的成本,实现更好的性能,甚至能完成传统模型根本做不到的罕见癌零样本诊断。
这打破了行业的路径依赖,让“知识+数据”双轮驱动,成为病理大模型全新的发展方向。
对于临床诊断来说,KEEP的出现,又把技术落地的进程往前推了一步。
一方面,它试图打破罕见癌诊断的资源壁垒,以前只有顶级三甲医院的专家能确诊的罕见病,现在通过KEEP的辅助,基层医院的病理医生也可能做出精准的判断,极大地缩小了不同地区的医疗资源差距,让更多罕见癌患者能尽早确诊、及时治疗。
另一方面,KEEP的零样本泛化能力,让AI病理系统不用针对每个医院、每个病种做单独的微调,大大降低了AI病理落地的成本和门槛,能更快地普及到各级医院,真正走进临床日常。
更重要的是,KEEP的诊断具备极强的可解释性:它能给病理医生输出清晰的癌细胞区域热力图,明确告诉医生“癌细胞在哪,为什么判断是这个亚型”,而不是像传统模型一样,只给出一个冷冰冰的诊断结果。
这种可解释性,是AI病理能获得医生信任、真正融入临床 workflow 的核心前提。
当然,研究团队也在论文里坦诚了KEEP的局限性。
对于极罕见的疾病,因为缺乏足够的文本描述和数据,模型的性能还有提升空间;
未来还可以结合提示学习,进一步提升模型的鲁棒性,还能整合基因组、表观组的多组学数据,让AI不仅能看病理切片,还能结合基因信息,实现更精准的分子分型和预后预测。
病理医生的培养,需要十几年的寒窗苦读,不仅要看无数的切片,更要建立完整、系统的医学知识体系。
过去的病理AI,就像是一个只会刷题的“考生”,而KEEP的出现,试图让AI病理学会像真正的医生一样,用知识体系去理解、去判断、去诊断。
这不仅是AI技术的一次突破,更是给无数癌症患者,尤其是罕见癌患者,带来了新的希望。
未来,随着知识增强病理大模型的不断迭代和落地,会有更多患者能获得更早、更精准的癌症诊断,让“金标准”的病理诊断,不再受限于地域和资源,真正实现普惠的精准医疗。
参考文献
本文核心内容源自发表于国际顶级肿瘤学期刊《Cancer Cell》的研究论文《Knowledge-enhanced pretraining for vision-language pathology foundation model on cancer diagnosis》,由上海交通大学、上海人工智能实验室、上海交通大学医学院附属新华医院等机构的周潇、孙洛伊、何德轩、谢伟迪、王延峰、张娅、孙琨等学者联合完成。
