个人理解可能存在偏差,仅为参考文档;一切以官方文档为准。
Node.JS是一种JS解释器,这种解释器是在服务端运行的,它的作用是:使JS在服务端运行。从而实现JS前后端开发。
Node.JS基于V8引擎。
1)JS运行在浏览器,存在多款浏览器,有代码兼容性问题;Node.JS运行在服务端,只有一种解释器,不存在代码兼容性问题。
2)都有共同的内置对象、自定义对象,不同的宿主对象。
3)JS用于开发浏览器端交互效果,Node.JS用于服务器端开发,例如操作数据库、调用其它服务器
官网
文档 (非官方,个人或组织翻译)
1)脚本模式
控制台:
node 文件路径
2)交互模式
控制台:
node进入,两次ctrl + C或者输入.exit退出
Nodejs全局大对象叫global,所有和Node有关系的内容都挂载到这个对象下,而原生JS是window
在浏览器端控制台中,检测全局的关键字是
window在NodeJS控制台中,检测全局的关键字是
global
在浏览器端,JS存在着全局污染问题
//浏览器端JS访问全局变量、函数
var a = 1;
function fn(){
return 2;
}
console.log(window.a); //可以访问
console.log(window.fn()); //可以访问
//结果为 1和2
//由此,在浏览器端的JS,由于变量和函数都是全局,所以存在全局污染的问题
而在Node.JS脚本模式下,每个脚本文件都不是全局的,也就不存在这种全局污染问题
//Node.JS中的JS访问全局变量、函数
var a = 1;
function fn(){
return 2;
}
console.log(global.a); //不可访问
console.log(global.fn()); //不可访问
//结果为 undefined和报错(TypeError: global.fn is not a function)
//在Node.js脚本模式中,变量和函数都不是全局的,也就不存在全局污染问题
在Node.js交互模式下的变量就是全局的
console是控制台对象,用于输出到控制台
该对象为全局对象,在使用的时候无需引入模块
console.log(5); //日志
console.info(2); //消息,相当于Winform中MessageBox的info
console.warn(8); //警告,相当于Winform中MessageBox的warnning
console.error(6); //错误,相当于Winform中MessageBox的error
console.time(提示字符);
console.timeEnd(提示字符);
开始和结束的提示字符要一致
console.time('计时');
for(let i = 0;i<=100000;i++){
}
console.timeEnd('计时');
//打印结果 计时: 1.547ms
用于查看服务器端的进程信息
process.arch查看CPU架构
process.platform查看服务器的操作系统
process.pid查看服务器Node.js的PID
process.version查看服务器Node.js版本号
process.kill(进程PID)结束指定PID
nextTick(回调函数)
process.nextTick()函数的优先级比setImmediate()的优先级高
console.log(2); //1
setImmediate(() => { //4
console.log(1);
});
process.nextTick(() => { //3
console.log(4);
});
console.log(3); //2
/*
2
3
4
1
*/
所谓缓冲区,也就是内存中一块区域,用于临时存储数据。
Buffer缓冲、缓存
空间单位为字节,每个字符占1字节,一个汉字占3字节
当数据内容比Buffer空间大时,溢出部分将不能保存
Buffer.alloc(空间大小,目标数据);
var buf = Buffer.alloc(5, 'abcde');
console.log(buf); //<Buffer 61 62 63 64 65>
.toString()
var buf = Buffer.alloc(5, 'abcde');
console.log(buf); //<Buffer 61 62 63 64 65>
console.log(buf.toString()); //将buffer的内容转为字符串
引入模块是指引入哪些非全局的模块
像console、timer等这种内置的全局模块没必要引入。
NodeJS中引入模块使用require()方法。
引入模块有两种形式:
以路径开头
不以路径开头
所谓以路径开头文件形式导入,就是导入的路径加上./或../开头的形式
在以文件形式导入时,.js后缀也可以省略
以路径开头又有两种形式
文件形式
目录形式
require(模块文件路径);
var obj = require('./05model.js');
var obj = require('../../12model'); //省略.js后缀
注意:省略.js后缀的这种引入方式,一定要确保有该文件名的JS文件,
否则这种方式会当作目录形式导入
var obj = require('../../12model')
承接上面的,如果12model.js文件不存在,程序就会以目录形式去找寻12model文件夹。
然后先在该目录寻找一个叫package.json的JSON对象文件,并在该文件中读取"main"指定的文件名;
如果没有package.json这个文件,则会再去找一个叫index.js的文件。
package.json文件其实就相当于说明书(在开发中作为项目说明文件)就去找index.js文件
注意:package.json中只能有"main"一个属性指定文件,不能够指定多个文件
var obj = require('../../12model'); //如果该目录没有一个叫12model.js的文件,程序在该目录找一个叫12model的目录,再在其目录下寻找一个叫package.json的文件,然后读取该json文件中关于"main"的描述,如果没有该文件,则会找叫index.js的文件
//也就是先找12model/package.json文件,如果没有则找12model/index.js
//package.json文件
{
"main":"01_test.js" //固定的"main"属性
}
所谓不以路径开头,也就是导入时开头没有使用./或../
同样的,不以路径开头也分文件形式和目录形式
用于引入官方提供的核心模块
如querystring模块等
require('querystring');
这种方法导入,会先在当前目录下寻找一个叫node_modules的目录,再在里面寻找指定文件;如果当前目录下没有node_modules目录,则再往上级目录寻找node_modules,如果没有再上一级……
var res = require('cat'); //会在当前目录下的node_modules子目录寻找cat.js文件进行导入
当模块引入成功后,得到的是暴露对象
暴露的对象默认是一个空对象,如果要暴露哪些内容,只需要将其添加到这个对象即可
可以暴露属性、方法、对象、数组
module.exports = {
外部可访问的名称:需要暴露的变量或方法
}
如:
module.exports = {
myPool = pool
}
也可以
module.exports.外部访问的名称 = 需要暴露的变量或方法
如:
module.exports.myPool = pool;
或者
exports.外部访问的名称 = 需要暴露的变量或方法
如:
exports.myPool = pool;
或者
exports = { myPool:pool }
var a1 = 1;
function fun1(r = 0)
var arr1 = ['sdasd', 'dffw', 'fw'];
var obj1 = {
name: 'tao',
sex: '男'
};
module.exports = {
myProperty:a1, //将a暴露出去,外部可访问的名称为myA
myFunction1:fun1,
myArray:arr1,
myObject:obj1
};
上面这种用大括号包起来的,实际是利用了对象进行包装;当如果暴露的内容只有一项,应该直接把暴露内容赋值给module.exports
var person = {
name: 'tao',
sex: '男'
};
module.exports = person; //暴露的内容只有一项,所以没必要module.exports = { pubObject: person };这样,直接赋值给module.exports即可。
使用require()方法使用暴露的对象
//05model.js
function circumference(r = 0)
function area(r = 0) {
return Math.pow(r, 2) * Math.PI;
}
module.exports = ;
var res = require('./07_practical_circle.js');
console.log(res.getAera(20));
console.log(res.getCircumference(20)); //调用暴露的方法
Directory
__dirname
console.log(__dirname); //当前模块绝对路径
//C:Users15916OneDriveWEBFilestudy
File
__filename
console.log(__filename); //绝对路径+模块名称
//C:Users15916OneDriveWEBFilestudy07_practical_main.js
JSON文件里只有两种数据:一种是对象、一种是数组,属性名、值的字符串必须使用双引号””进行包裹,而不可使用单引号
{
"first": "noSet",
"next": "OK"
}
包(package):指的是第三方模块,需要下载安装才能使用
npm:用于管理包的工具,例如:下载安装、上传、更新、卸载…
npm在Nodejs安装时已经附带安装
查看npm版本
npm -v
CommonJS是一套模块化规范,NodeJS的引入、暴露都会基于这个模块规范。
由于npm默认镜像源是在国外的,有时可能会出现无法访问或者访问慢的情况,因此可换成国内源
查看镜像地址:
npm get registry
换源:
npm config set registry 镜像地址
如:
npm config set registry http://registry.npm.ta.org
初始化包信息,生成项目描述文件,会记录当前的包
当迁移项目的时候,只需要传这个项目描述文件,迁移的电脑再根据这个描述文件自动下载即可
npm init -y
下载安装包
npm install 包名称
下载package.js中记录的包到本地
npm install
卸载包
npm uninstall 包名
是客户端向服务器传递参数的一种方式,每一组传递的值分为参数名和参数值两部分
在网页地址中经常见
参数名1=参数值1&参数名2=参数值2
https://search.jd.com/Search?keyword=sid&enc=utf-8&wq=sid&pvid=8726bee2fc5b4678a62e48a44b801bdb
例如上面链接的keyword=sid&enc=utf-8
其中8726bee2fc5b4678a62e48a44b801bdb是base64格式编码
querystring为字符串查询模块,安全等级3,由于功能单一,目前已弃用
获取字符串的值需要先将字符串转成对象,然后再通过访问对象的属性来获取值
使用.parse(字符串)将字符串转换成对象
var qs = require('querystring'); //引入querystring模块
var str = 'a=12&b=15&kk=sqe';
var obj = qs.parse(str); //转换成一个对象
console.log(obj.a); //通过对象.属性来访问
.stringify(对象)将对象格式化为查询字符串
let emp = {
name:'小艺',
say:'miss you'
}
var str = qs.stringify(emp);
console.log(str);
URL:统一资源定位(网址),互联网上任何资源都有对应的url,用来访问资源。
大多数服务器端口使用的是443
http://www.codeboy.com:9999/1.html?lid=1#one
上面这个地址中,协议是http:// 域名/ip地址是www.codeboy.com 端口是9999 资源(文件)的路径是1.html 查询字符串是lid=1 锚点链接是one
使用new URL()将URL地址转换成对象
var str1 = 'http://www.codeboy.com:9999/1.html?a=1&b=2#one';
var obj1 = new URL(str1);
console.log(obj1);
//得到结果
URL {
href: 'http://www.codeboy.com:9999/1.html?a=1&b=2#one',
origin: 'http://www.codeboy.com:9999',
protocol: 'http:',
username: '',
password: '',
host: 'www.codeboy.com:9999',
hostname: 'www.codeboy.com',
port: '9999',
pathname: '/1.html',
search: '?a=1&b=2',
searchParams: URLSearchParams { 'a' => '1', 'b' => '2' },
hash: '#one'
}
通过对象点属性可以访问到各个参数
console.log(obj.searchParams); //获取查询字符串部分
console.log(obj.searchParams.get('a')); //获取传递参数a
Nodejs定时器有4种,常用两种
无论哪种定时器都是放在任务队列中执行的
定时器模块Timer
该对象为全局对象,在使用的时候无需引入模块
定时器其实也是异步的
setTimeout(回调函数,延时毫秒);
也就是延时多少毫秒做某件事
//延时3秒打印‘boom’
setTimeout(function(){
console.log('boom');
},3000);
clearTimeout(定时器变量)
var timer = setTimeout(function(){
console.log('boom');
},3000);
clearTimeout(timer); //清除定时器,也就是定时器不会再执行
setInterval(回调函数,间隔时间)
var s = setInterval(function(){
console.log('sss');
},1000);
clearInterval(定时器变量)
var s = setInterval(function(){
console.log('sss');
},1000);
clearInterval(s); //清除定时器,定时器不会再执行
setImmediate(回调函数)
setImmediate()函数的优先级比process.nextTick()的优先级低
同样的,清除用clearImmediate()函数即可。
const process = require('process')
process.nextTick(() => {
console.log('A') //2
process.nextTick(() => {
console.log('E') //5
})
setImmediate(() => {
console.log('F') //8
})
})
process.nextTick(() => {
console.log('B') //3
process.nextTick(() => {
console.log('G') //6
})
setImmediate(() => {
console.log('H') //9
})
})
setImmediate(() => {
console.log('C') //7
})
process.nextTick(() => {
console.log('D') //4
})
console.log('主线程') //1
/*
主线程
A
B
D
E
G
C
F
H
*/
第二个参数是要等待的毫秒数,而不是要执行代码的确切时间。JavaScript 是单线程的,所以每次只能执行一段代码。为了调度不同代码的执行,JavaScript 维护了一个任务队列。其中的任务会按照添加到队列的先后顺序执行。setTimeout()的第二个参数只是告诉 JavaScript引擎在指定的毫秒数过后把任务添加到这个队列。如果队列是空的,则会立即执行该代码。如果队列不是空的,则代码必须等待前面的任务执行完才能执行。
——《JS高级程序设计》的描述
console.log('111111');
setTimeout(()=>{
console.log('End');
},3000);
console.log('222222');
console.log('333333');
//打印结果为
/*
111111
222222
333333
End
*/
上面这个End会当程序等待3秒的时候输出
也就是说一次定时器还是周期定时器都是不阻塞主线程的,在主程序执行到把定时器的时候,继续执行主程序,而定时器部分会在等待够定时的时间后将定时器任务放入任务队列中,任务队列每放入一个任务执行一个。
一次定时器
var x = 0;
var doing = function() else {
console.log('OK');
}
}
doing(); //调用匿名函数,当x>25时候跳出
周期定时器
var x = 1;
var si = setInterval(() =>
console.log('嘀嘀嘀');
x++;
}, 3000);
var endTime = new Date('2022/5/14 21:46:00');
var si = setInterval(() =>
let lastDay = Math.floor(lastTime / 24 / 60 / 60);
let lastHour = Math.floor(lastTime / 60 / 60 % 24);
let lastMinu = Math.floor(lastTime / 60 % 60);
let lastSec = Math.floor(lastTime % 60);
console.log(`还剩${lastDay}天 ${lastHour}时:${lastMinu}分:${lastSec}秒`);
},
1000);
文件模块fs包含文件形式和目录形式
文件模块属于Nodejs独有,所以使用文件模块需要先导入fs模块
.statSync(文件或文件夹路径)
该方法是同步的,因此会发生阻塞。
注意:当同步方法发生报错时,后续程序将不再执行。
也就是,比如文件夹过大时,计算文件夹大小要耗很长时间,由于该方法是同步的,会阻塞后面代码的执行。
const fs = require('fs'); //导入模块
var s = fs.statSync('./es6.js'); //获取文件状态,获取到的是一个对象
console.log(s);
/*
Stats {
dev: 1458932571,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: 4096,
ino: 3096224743864365,
size: 1536, //文件大小
blocks: 8,
atimeMs: 1652406259000,
mtimeMs: 1652362217000,
ctimeMs: 1652406259683.276,
birthtimeMs: 1651820279349.3928,
atime: 2022-05-13T01:44:19.000Z,
mtime: 2022-05-12T13:30:17.000Z,
ctime: 2022-05-13T01:44:19.683Z,
birthtime: 2022-05-06T06:57:59.349Z
}
*/
只有同步的方式才使用变量将结果保存,异步方式是不使用变量进行保存的
不阻塞主线程的执行。
异步方法第二参数都是回调函数。
.stat(文件或文件夹路径,回调函数)
const fs = require('fs');
fs.stat('./01_homework.js',()=>{}); //异步,结果不用变量进行保存
线程池
由于js是单线程执行的,Nodejs的解决方法是主程序在运行时,执行到异步的操作,会将其放入线程池中,然后继续主程序的执行,线程中的异步执行完的结果是一个回调函数,异步把这个结果放入事件队列,主程序执行到最后,再执行事件队列的结果;所谓线程池,也就是除主线程以外的线程,在需要的时候就去借用一个线程,该借用的线程为独立的线程。
fs.stat('./tampermonkey.js', () => {
console.log(11111);
}); //执行完tampermonkey.js后打印11111
在回调函数中抛异常
也就是实现在回调函数中抛出可能产生的错误
只要在回调函数中传入一个参数即可
.stat(文件或文件夹路径,(错误参数)=>{处理})
.stat(文件或文件夹路径,(错误参数,无错误参数)=>{处理})
fs.stat('./00002.js', (err1) => {
console.log(err1);
}); //比如00002.js文件不存在,则抛出异常err
//-------------------------
fs.stat('./00002.js', (err1) =>
}); //比如00002.js文件不存在,则抛出异常'NO Found File'
//-------------------------
fs.stat('./00002.js', (err1,r) =>
console.log(r); //无错误时打印r
});
.isFile()
const fs = require('fs'); //导入模块
var s = fs.statSync('./es6.js');
console.log(s.isFile());
.isDirectory()
const fs = require('fs'); //导入模块
var s = fs.statSync('./es6.js');
console.log(s.isDirectory());
当创建的目录存在时会报错
注意:当同步方法发生报错时,后续程序将不再执行。
fs.mkdirSync(目录)
var mk = fs.mkdirSync('./NewFolder');
fs.mkdir(目录,回调函数)
fs.mkdir('./NewFolder',(e,s)=>);
注意:该方法是空目录,移除非空目录会报错
当移除的目录不存在时会报错
注意:当同步方法发生报错时,后续程序将不再执行。
fs.rmdirSync(目录)
var rm = fs.rmdirSync('./NewFolder');
fs.rmdir(目录,回调函数)
fs.rmdir('./NewFolder',(e,s)=>);
fs.readdirSync(目录)
var r = fs.readdirSync('./testMKDIR');
console.log(r);
fs.readdir(目录,回调函数)
fs.readdir('./testMKDIR',(e,s)=>)
写入的文件为文本文件。
当文件不存在会进行创建再写入,存在则覆盖。
fs.writeFileSync(文件路径,内容)
fs.writeFileSync('./222.js','112233334');
fs.writeFile(文件路径,内容,回调函数)
.appedFileSync(文件名,内容)
let emp = [
{ id: 1, name: '小艺' },
{ id: 2, name: '小宇' },
{ id: 3, name: '芹菜' }
];
for (const i in emp) {
fs.appendFileSync('user.txt', `${emp[i].id} ${emp[i].name}
`);
}
.appedFile(文件名,内容,回调函数)
读取到的是buffer数据,利用toString()转成字符串即可
readFileSync(文件名)
readFile(文件名,回调函数)
fs.copyFileSync(原文件名,复制后文件名)
fs.copyFile(原文件名,复制后文件名,回调函数)
unlinkSync(文件路径)
unlink(文件路径,回调函数)
fs.existsSync(文件名)
所谓文件流,就是将文件指以流的形式(分段)读写,在读写的时候要创建buffer。
流的形式是异步的。
创建读取流.createReadStream(文件路径)
事件监听
在读取的过程中还可以使用以下两个事件进行监听以获取一些信息
数据流入监听事件
.on('data',回调函数)(data字符串是固定的)读取结束监听事件
.on('end',回调函数)(end字符串是固定的)
const fs = require('fs');
//将一个文件按照流的形式读取,会分成多段
const rs = fs.createReadStream('./user.zip');
//通过事件监听是否有数据流入
//data是固定形式的字符串,表示数据入流
//通过回调函数获取流入的一段数据
var count = 0; //这里创建一个count变量在读取中进行流数据计数
rs.on('data', (c) => {
//c代表流入的一段数据
console.log(c);
count++;
});
//添加事件,监听是否读取结束
//end是固定的字符串,表示读取结束
rs.on('end', (c) => {
console.log(count); //由于流是异步的,因此不可在主线程进行计数,而需要通过end事件获取
});
实际读取过程中以上两个事件仅是可选的部分。
创建写入流.createWriteSteam(文件路径)
使用读取流的.pipe(写入流)方法
pipe() 就是管道
const fs = require('fs');
const rs = fs.createReadStream('./user.zip'); //流读取user.zip
const ws = fs.createWriteSteam('./user_copy.zip'); //创建写入流
rs.pipe(ws); //流写入到user_copy.zip
可以用来创建WEB服务器,为客户端提供资源(数据、html、css…)
超文本传输协议,浏览器(客户端)与WEB服务器间的一种通信协议。
浏览器发出请求(Request),服务器响应(Response)。
协议包含三部分:
General(通用头信息)
Response Headers(响应头信息)
Request Headers(请求头信息)
Request URL:请求的URL,要请求的服务器上的资源
Request Method:请求的方法,对以上资源的操作方式(增删改查)
Status Code:状态代码
100系列接收到请求但未结束
200系列 成功的响应
300系列响应的重定向 也就是发生跳转
400系列的都是客户端请求的错误
500系列服务器端错误
状态码详细参考一文读懂所有HTTP状态码含义
304:表示向服务器所请求的资源,浏览器本地已经缓存有一份,浏览器会直接取用本地缓存的资源,当服务器资源发生改变的时候才会再次请求。
Location:要跳转的URL
Content-Type:响应的内容类型,解决中文乱码
text/html; charset=utf8
http协议模块需要先引入。
以下为大致步骤:
1.引入模块
2.使用
.createServer()方法创建服务器3.使用
.listen(端口号,回调函数)设置端口进行监听
//1.引入模块
const http = require('http');
//2.创建web服务器(在本地创建 127.0.0.1)
const app = http.createServer();
//3.监听端口
app.listen(8080, () => {
console.log('服务启动成功');
});
//可以通过127.0.0.1:8080或者localhost:8080进行访问
通过事件监听是否有请求,一旦有请求自动执行回调函数。
回调函数中,第一个是请求的对象,第二个是响应的对象
//req是请求的对象,获取请求内容
//res是响应的对象,做出响应
//字符串'request'是固定的
app.on('request',(req,res) => {
//内容
});
响应
设置响应头信息
app.on('request',(req,res) => );
*/
//这种解决中文乱码问题的方法也可以在html中通过<meta charset=utf-8>实现
//设置响应的内容
res.write('响应内容');
//结束并发送响应
res.end();
});
跳转
app.on('request', (req, res) => );
请求
浏览器在访问服务器之初,默认访问的是/
浏览器端请求不同资源,都会在url后写上具体名称,是以/开头的,如
https://www.baidu.com/more
/more 就是请求的内容
app.on('request', (req, res) => {
//获取请求的url路径
console.log(req.url);
//获取请求的方法
console.log(req.method); //GET或者其他
}
此捕获是针对于原生的HTTP模块
服务器应该对每一个错误都进行处理
因此在.createServer()的时候应该利用回调进行捕获异常
而捕获有两种形式:一种是同步捕获、一种是异步捕获
try...catch
const server = http.createServer((req, res) =>
res.end('服务器正常');
} catch (err) {
console.log(err);
res.end("服务器异常,请稍后再试");
}
});
1)使用Promise().catch()的方式捕获
const server = http.createServer((req, res) => {
//异步捕获服务器错误
new Promise(() => {
throw new Error('我是一个错误');
}).catch((err) => {
console.log(err);
res.end("服务器异常");
});
});
2)使用try...catch时利用await/async捕获异步异常
const server = http.createServer(async(req, res) => { //async
//同步捕获服务器错误
try {
await foo(); //await
} catch {
console.log(err);
res.end("服务器异常");
}
});
function foo() {
return new Promise(() => {
throw new Error('我是一个错误');
});
}
一个基于Node.js平台,快速、开放、极简的第三方WEB开发框架
除此之外还有koa、阿里的egg等
express框架官方文档:官网(expressjs.com.cn)
使用前需要在shell中使用npm下载,然后引用模块
npm install express
const ex = require('express');
const app = express(); //开启服务器
app.listen(8080,()=>{ //设置端口,这里回调函数其实可以省略不写直接app.listen(8080);
console.log('服务器启动成功');
});
该框架将请求用路由来处理
URL到函数的映射。浏览器向服务器发起请求,服务器会根据请求url做出响应。
路由包含三部分,请求的URL、请求的方法、回调函数。
.get(请求的页面,回调);
如果有相同的路由,则只有第一个起作用
发送消息
.send(内容)
在一个路由中.send()方法只能执行一次,如果send()之后还有要执行的将发生错误:Error [ERR_HTTP_HEADERS_SENT]:Cannot set headers after they are sent to the client,
为了避免这种错误,应该在一定条件send()之后return防止往下执行。
//添加路由
//请求方法:get 请求的URL:/index
app.get('/index', (req, res) => {
//设置响应的内容并发送
res.send('这是首页');
});
跳转
.redirect(跳转页面)
//路由(get /study),执行跳转
app.get('/study', (req, res) => {
//跳转
res.redirect('http://www.tmooc.cn'); //注意不可以直接www. 要加上http
});
//当访问主页 / 时跳转 /index
//路由(get /),跳转 /index
app.get('/', (req, res) => {
//跳转
res.redirect('/index'); //这里则不需要http
});
发送文件
.sendFile(文件绝对路径)
注意:是绝对路径,不可以使用相对路径。
如果想简短写,可以联合前面的关键字获取路径
//路由(get /datail),响应文件user111.txt
app.get('/detail', (req, res) => {
// res.sendFile('D:/BaiduSyncdisk/WEBFile/study/user111.txt');
res.sendFile(__dirname + '/user111.txt'); //__dirname可获取当前目录
});
修改响应信息头部
.header('Content-Type','text/html;charset=UTF-8');
app.get('/detail', (req, res) => );
get传参
从浏览器直接输入url访问,就是get请求
http://www.tmooc.cn/mysearch?keyword=笔记本&id=12
这里/mysearch是请求的内容
?keyword=笔记本 就是参数名和参数值
以?开头,&隔开每一项参数
这种情况,要获取上面url中keyword的参数值
使用.query方法获取到该参数对象,再通过对象.方法就能获取该参数名的值
注意:.query方法只适用此情况
app.get('/mysearch', (req, res) => {
// console.log(req.url, req.method);
res.send('搜索成功,您关键字为: ' + req.query.keyword);
});
由于get传参这种url是暴露的,一般账号密码等安全等级高(敏感)信息不适用这种方式。
路由传参
路由传参是指url中对参数名进行了隐藏,像下面这样
http://www.tmooc.cn/mysearch/111/aaa
这里/mysearch是请求的内容
/111 是参数值,其实是有参数名的,但是参数名被隐藏了
直接以/开头,下一个参数再以/开头
这种情况,可以先在路由的请求部分指定参数名
再通过req参数的.params获取到该参数对象,再使用对象点属性来获取值
//该路由指定当请求的资源为/mysearch且有一个被隐藏参数名的url
//也就是比如 http://www.tmooc.cn/mysearch/111 这样的url
//而http://www.tmooc.cn/mysearch这样不符合这个路由
app.get('/mysearch/:pname', (req, res) => {
res.send(req.params.paname);
});
如果需要多个参数传值,则继续使用/隔开即可
//请求为/mysearch的url中传参3个参数,就符合该请求
app.get('/mysearch/:pid/:pname/:count', (req, res) => {
res.send(`你访问的商品 id为${req.params.pid} 商品名:${req.params.pname} 数量:${req.params.count}`);
});
// http://www.tmooc.cn/mysearch/04/小米Air/15
POST传参
POST请求:需要通过HTML表单发起的请求
POST传递是以流的形式,URL不可见,用于传递大的文件或数据
因为是流的形式,
老旧的写法(已淘汰):所有获取信息可以通过on()事件来获取
常用写法
常用的写法是使用:请求内容解析 .body
req.on('data',(c)=>{ //'data'这个字符串是固定的
c.toString(); //得到的是查询字符串
//再使用querystring模块的parse方法转成对象,再获取
});
如:
//路由(post /myreg)
app.post('/myreg', (req, res) => {
//通过事件监听是否有数据传递
req.on('data', (c) => {
//c是传递的一段数据
var str = c.toString(); //c得到的是buffer,所以需要用tostring进行转换成查询字符串
//把查询字符串转为对象
var obj = qs.parse(str);
console.log(obj.username);
});
res.send('登陆成功');
});
注意:这个.on()事件是异步的,所以不可在回调外边获取,上面的执行顺序是主线程先.send()再执行.on()异步的回调。
所以如果要拿到异步结果,上面应该改成
req.on('data', (c) => {
//c是传递的一段数据
var str = c.toString();
var obj = qs.parse(str);
console.log(obj.username);
res.send('登陆成功,欢迎'+obj.user); //在异步中写
});
简化和隔离基础设施与业务逻辑之间的细节,让开发者更关注业务,提高开发效率
拦截对WEB服务器的请求
可用于作验证身份验证等
也就是请求前被拦截,做一定处理再决定是否继续进行。比如验证是否是管理员身份、商品打折扣等。
共分为5级:
应用级中间件
路由级中间件
内置中间件
第三方中间件
错误处理中间件
中间件使用.use() 方法
也称为自定义中间件,一旦拦截到请求,就自动调用一个函数。
也就是当访问该资源时,服务器会先拦截请求,执行某个函数,该函数再决定是否继续。
.use(拦截的请求资源URL,拦截后要调的函数)
其中这个要调的函数也有三个参数,分别为:请求,响应,是否继续
const ex = require('express');
const app = ex();
app.listen(8080, () => {
console.log('服务器启动成功');
});
//这样写中间件函数是为了可以 复用
function fn(req, res, next) else {
//否则是管理员,允许往后执行
//往后执行可能是下一个中间件,或者是路由
next();
}
}
//添加中间件,拦截对/list的请求
app.use('/list', fn);
//路由(get /list) 响应这是管理员页面
app.get('/list', (req, res) => {
res.send('你现在查看的是后台,只有管理员有权限查看');
});
app.use('/delete', fn); //复用了中间件函数fn
app.get('/delete', (req, res) => {
res.send('删除成功');
});
//拦截/shopping请求,先进行打折
function discount(req, res, next)
//添加中间件,拦截对/shopping的请求
app.use('/shopping', discount);
//添加到购物车路由(get /shopping)
app.get('/shopping', (req, res) => );
.use(要拦截的URL,路由器)
路由器
在团队协作开发的过程中,如果都往一个里去写,肯定会出现路由混乱的情况,因此就有了路由器。
路由器是用来管理路由,最终路由器被WEB服务器使用。
说白了就是将一系列路由单独放在一个文件中进行管理,避免出现路由重复的混乱情况。
路由器的使用
路由器的使用也就是路由级中间件
1.路由器文件创建
大致步骤:
引入
express模块使用
.Router()方法创建路由器使用路由器的
.get()方法创建路由暴露出去
举例:user.js (用户的路由器模块文件)
//引入express模块
const ex = require('express');
//创建路由器对象
const r = ex.Router();
//往路由器添加路由
//路由(get /list)
r.get('/list', (req, res) => {
res.send('这是用户列表');
});
//暴露(导出)路由器对象
module.exports = r;
2.导入路由器文件
大致步骤:
引入
express模块创建服务器
引入该暴露的路由器模块
并使用
.use(前缀,引入的路由器模块)方法引入路由器文件的路由
使用.use()方法,该方法的这个前缀参数非必须要写(可以省略),添加前缀只是为了区别不同资源而添加的。
比如用户商品都有/list的路由,为了不混乱,加个前缀user,访问的时候就需要/user/list,访问商品就是/product/list
举例:app.js (服务器文件)
//引入express模块
const ex = require('express');
//引入暴露的路由器对象模块文件
const userRouter = require('./user.js');
// console.log(userRouter); 只是作为测试是否成功引入
//创建服务器和绑定端口
const app = ex();
app.listen(8080, () => {
console.log('服务器启动成功');
});
//使用用户路由器,给所有的URL添加前缀/user
app.use('/user', userRouter); //127.0.0.1:8080/user/list
404拦截
.use()方法省略请求资源的参数,只写回调函数即可
注意:404请求的拦截,要把这个路由放在最后面,否则所有都会先被404拦截掉
....
//路由(get /list) 响应这是管理员页面
app.get('/list', (req, res) => {
res.send('你现在查看的是后台,只有管理员有权限查看');
});
....
//拦截所有的请求
//放在所有路由之后,否则所有的请求都会被这个拦截
app.use((req, res) => {
res.status(404).send('Not found');
});
由于庞大的服务器资源是数不胜数的,不可能每一个资源都去写一个路由,因此对于静态的资源部分,可以使用静态资源托管的方式。
静态资源:包括html,css,js,图形,视频,声音…
托管静态资源
客户端请求静态资源,不需要通过路由响应,而是自动查找资源
.static()方法
步骤:
创建一个公开的资源目录,里面放有静态的资源文件
使用express框架的
.static(托管的目录路径)方法指定这个公开的静态资源目录再使用express框架的
.use()方法设置该目录
const ex = require('express');
const app = ex();
app.listen(8080, () => {
console.log('启动成功');
});
//使用中间件托管静态资源到public目录
//如果请求的是静态资源都会自动到该目录找
app.use(ex.static('./public'));
//比如访问 //127.0.0.1:8080/111.html,web服务器就会自动往这个public目录里找111.html
请求内容解析
将POST传递的参数转为对象
由于POST是以流的形式传递的,因此获取POST数据需要通过事件进行获取,而获取到的信息又是查询字符串形式,因此,还需要再通过querystring模块的.parse()方法将其转成对象方可使用,过于复杂。
const qs = require('querystring');
app.post('/mylogin', (req, res) => {
req.on('data', (c) => {
res.send(qs.parse(c.toString()).uid + ' 登录成功');
});
});
以上是以前的写法,过时了
而在express框架中,只需要express.urlencoded({ extended: false}) 指定用原生的querystring还是扩展的第三方模块转换对象。
true是用第三方qs模块进行处理请求参数,false是使用内部queryString内置模块处理请求参数。
然后路由中使用.body获取到对象。
<!-- public目录下的login.html -->
<body>
<!-- action 提交地址 将数据提交到哪里去?(就是服务器端的路由)
method 提交时使用的方法 get post
input 可视化表单制作 用户输入信息的地方 -->
<form method="post" action="/mylogin">
<h1>账户</h1>
用户<input type="text" name="uid">
<br> 密码
<input type="text" name="pwd">
<br>
<input type="submit">
</form>
</body>
const express = require('express');
const qs = require('querystring');
const app = express();
app.listen(8080, () => {
console.log('已启动服务器');
});
//指定public目录为静态资源
app.use(express.static('./public'));
//将post传递的参数转为对象
app.use(express.urlencoded({
//是否使用扩展的方法转为对象
extended: false //false不使用(使用原生的querystring),true使用
}));
app.post('/mylogin', (req, res) => {
console.log(req.body); //得到查询字符串的对象
res.send('你的POST请求为:'+req.body.uid); //对象.属性即可获取请求的信息
});
这个.urlencoded( extended: false )是针对POST请求来的,因为前端页面POST请求的数据要遵循HTTP规定,会对英文和标准符号以外的特殊字符(如:中文)或符号进行编码,服务器需要对其进行解码,.urlencoded( extended: false )就是告诉服务器使用扩展的模块方法进行解析还是用原生的querystring。
压缩
var compression = require('compression')
var app = express();
// 启用gzip
app.use(compression());
除此之外还有很多中间件,参考:
Express 4.x – API Reference – Express 中文文档 | Express 中文网 (expressjs.com.cn)
也就是一旦发生错误,将执行指定的中间件,使用next(错误)
//路由器文件user.js
router.post('/reg', (req, res, next) => );
});
//服务器文件app.js
//添加错误处理中间件,拦截所有路由传递过来的错误
app.use((err, req, res, next) => {
//err 收到的传递过来的错误
res.send({
code: 500,
msg: '服务器错误'
});
});
前面我们每次修改服务器文件都需要手动将服务器文件进行停止,再开启。
而使用nodemon就可以帮助我们自动管理这个文件,保存即可自动重新启动服务器
nodemon是第三方工具,使用前需要先用npm安装
npm install nodemon
然后再通过nodemon 服务器文件路径
nodemon .app.js
需要先使用npm下载安装
npm install mysql
有两种创建连接方式:
创建连接对象,单独使用连接
创建连接池对象,使用连接池连接
一般使用创建连接池对象这种方式
const mysql = require('mysql');
//创建连接对象
const ms = mysql.createConnection({
host: '127.0.0.1',
port: '3306',
user: 'root',
password: '',
database: 'tedu' //需要进入的数据库名
});
//测试连接是否可用
ms.connect(); //控制台不显示,代表正常连接
//执行SQL命令,会自动获取连接
c.query('SELECT * FROM `emp`');
创建连接对象的方式去连接数据库,在访问量庞大时,开销也会很大;比如在大量的并发访问时,假如某网站一天的访问量是10万,那么,该网站的服务器就需要创建、断开连接10万次,频繁地创建、断开数据库连接势必会影响数据库的访问效率,甚至导致数据库崩溃。因此就有了连接池的概念。
连接池技术的核心思想是:连接复用,通过建立一个数据库连接池以及一套连接使用、分配、管理策略,使得该连接池中的连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。
简单说就是,连接池就好比生活中的共享单车群,从A地到B地,不需要每个人都买一辆单车,扫个码就能骑,骑到目的地关锁后;别人再扫码也能使用这辆共享单车。连接池的连接也如此,使用完成会归还到连接池中,供再次使用。
const mysql = require('mysql');
//创建连接池对象
const pool = mysql.createPool({
host: '128.0.0.1',
port: '3306',
user: 'root',
password: '',
database: 'tedu',
connectionLimit: 20 //限制连接的数量;限制并非随便设置,这和服务器的硬件性能有关系,需要考虑服务器的问题
});
//执行SQL命令,会自动获取连接
pool.query('SELECT * FROM `emp`');
如果不进行connectionLimit设置连接限制,默认连接限制是15个。
一般中小型项目15个连接足够。
因为连接池中的连接只有往数据库中执行命令的时候才会连接;因此创建连接池的方式不需要进行连接测试是否成功
MySQL模块的SQL操作,都使用.query(SQL命令字符串,回调函数) 该方法是异步的
查询语句,成功返回的结果(回调函数的result参数)是一个查询的结果
插入语句,成功返回的结果(回调函数的result参数)是一个插入数据信息的对象
注意:这里的SQL语句不需要加;
//执行SQL命令,会自动获取连接
//回调函数err是错误结果,result是成功返回的结果
pool.query('SELECT * FROM emp', (err, result) => );
/*结果为:
[
RowDataPacket {
eid: 1,
ename: 'tom',
sex: 1,
birthday: 1997-04-20T16:00:00.000Z,
salary: 8500,
deptId: 10
},
RowDataPacket {
eid: 2,
ename: 'lisa',
sex: 0,
birthday: 1998-06-05T16:00:00.000Z,
salary: 7600,
deptId: 20
},
RowDataPacket {
eid: 3,
ename: 'guary',
sex: 0,
birthday: 1999-03-28T16:00:00.000Z,
salary: 8600,
deptId: 10
}
]
*/
SQL语句的拼接
//模拟用户在浏览器传入参数
//假设传入的是jyee
var str = 'jyee';
pool.query(`SELECT * FROM `emp` WHERE `ename` = '${str}'`, (err, res) => );
SQL注入
所谓SQL注入攻击:就是往SQL命令加入新的命令,会破坏已有SQL命令
例如:
SELECT * FROM `emp` WHERE "1";
SELECT * FROM `emp` WHERE 1;
#上面这两句都可以获取所有员工的信息
因此
//假如用户传入了字符串
var str = 'jyee" or "1';
//原本想得到的查询语句为SELECT * FROM `emp` WHERE `ename` = "jyee";
pool.query('SELECT * FROM `emp` WHERE `ename` = "' + str + '"', (err, res) => );
//和用户的字符串拼接之后却变成了SELECT * FROM `emp` WHERE `ename` = "jyee" or ”1“;
//从而暴露了所有用户的信息
//这种行为就是SQL注入
防注入
也就是在查询语句中先用一个占位符占位,等待被替换。
当遇到有攻击性的语句时则会被过滤掉
在MySQL模块中的步骤为:
SQL命令语句中使用
?作为占位符。使用
.query(SQL命令语句,占位符替换的数组,回调函数)方法
var data1 = 7900;
var data2 = 30;
pool.query('SELECT * FROM `emp` WHERE `salary` = ? AND `deptId` = ?', [data1, data2], (err, result) => );
/*结果为
[
RowDataPacket {
eid: 7,
ename: 'jyee',
sex: 1,
birthday: 1998-02-13T16:00:00.000Z,
salary: 7900,
deptId: 30
}
]
*/
var str2 = '"jyee" or "1"';
pool.query('SELECT * FROM `emp` WHERE `ename` = ?',[str2],(err,result)=>);
//结果为[]
//插入数据
//普通写法
var eobj = {
ename: 'xiaoming',
sex: 1,
birthday: '1997-05-20',
salary: 8900,
deptId: 30
};
//'INSERT INTO `emp` VALUES(null,?,?,?,?,?)' 因为是自增列,所以需要指定自增列为null
pool.query('INSERT INTO `emp` VALUES(null,?,?,?,?,?)', [eobj.ename, eobj.sex, eobj.birthday, eobj.salary, eobj.deptId], (err, result) => );
/*结果为
OkPacket {
fieldCount: 0,
affectedRows: 1,
insertId: 10,
serverStatus: 2,
warningCount: 0,
message: '',
protocol41: true,
changedRows: 0
}
*/
在MySQL模块中,有以下简便写法(该方法仅为MySQL模块提供的简便写法,并非原生的SQL语句):
//MySQL模块提供的简便写法
pool.query('INSERT INTO `emp` SET?', [eobj], (err, result) => );
//注意:SET?间不需要空格
//eobj对象中的属性列名称必须与数据库列名称对应;而该对象的属性名的顺序没有要求;该对象中缺少属性名也可以,缺少的列会自动填补NULL值
判断是否成功
可以通过其affectedRows属性进行判断,0是没有删除,大于0是已删除
删除数据时,当删除的数据不存在时,并不会执行删除
因此删除数据时应该进行判断是否删除成功
在mysql模块中删除数据,成功返回的结果是一个删除信息描述的对象
var delId = 8;
pool.query('DELETE FROM `emp` WHERE `eid` = ?', [delId], (err, result) => );
判断是否成功
可以通过其affectedRows属性进行判断,0是没有删除,大于0是已删除
所谓前后端交互就是指后端给前端的请求响应回来的API(接口),前端再进行渲染。
接口:后端为前端提供的动态资源。
接口有很多种风格很多种规范,其中最流行的是RESful接口。
查看请求后端响应的数据:浏览器开发者模式—-网络—-Fetch和XHR—-响应
接口的五部分:接口地址、返回格式、请求方式、请求示例、接口备注。
我们写的路由其实就是接口
REST:表述性状态转移
RESTful接口:分布式超媒体架构风格接口
RESTful风格API详解

http://127.0.0.1:8080/v1/users/checkmail
v1版本号
users资源名称(复数)
checkmail 表示这是检查邮箱的操作
上面这种URL是RESTful风格的推荐形式:
使用路由传参的方式
先写版本号
再写资源名称(名称建议是复数,名称不能使用动词)
如果资源的操作在URL中不足以说明,可以继续加一些名词进行描述
因此,之前的路由访问方式都是不推荐的,应该如下
app.get('/v1/users/:p',(req,res)=>{
res.send('RESTful风格的路由');
});
对资源的操作方式,分为增删改查
get 获取资源
post 新建资源(插入数据)
put 修改资源
delete 删除资源
使用get传递过滤数据
http://127.0.0.1:8080/v1/users?pno=2
http://127.0.0.1:8080/v1/users?s1=8000&s2=100000
格式为JSON;JSON是一种字符串对象,里边通常是数组或者对象。
其中包含
状态码 code
消息 msg
数据 data
{"code":200,"msg":"登录成功"}
{"code":200,"msg":"登录成功","data":{"user":"tit","uid":"005"}}
当后端写好了接口,我们需要测试接口通常借助HTML来进行调试,但是接口很多的时候这并不方便,因此可以使用APIPost来进行。
ApiPost:是一款类似Postman可以对网页调试,模拟发送网页HTTP/HTTPS请求的工具。通常我们可以用来很方便的模拟get、post或者其他方式的请求来调试接口。
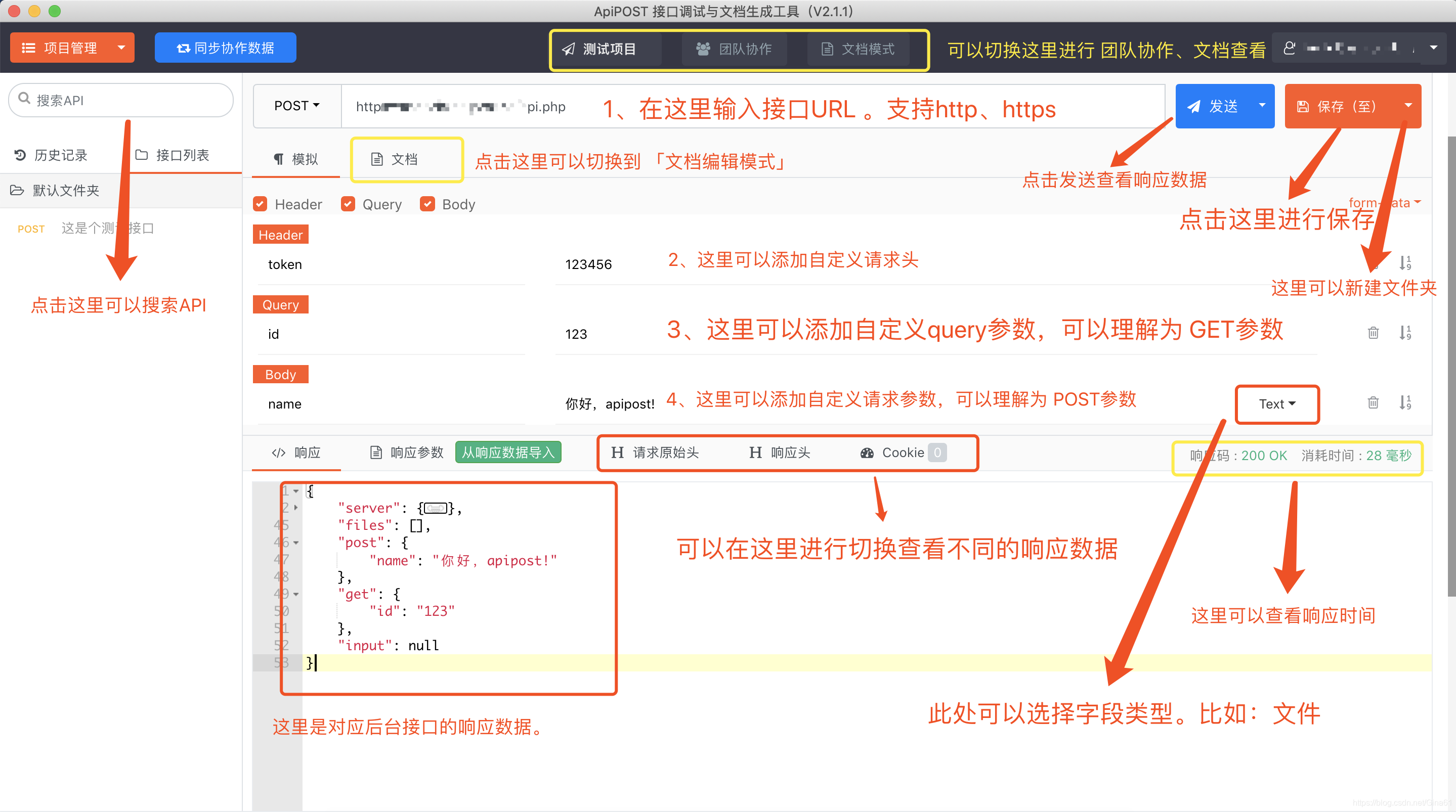
也就是这个工具是给前端拿来测试后端的端口的。
POST
使用POST时,APIPost的参数传值必须是Body,而不能是Header
要使用application/x-www-form-urlencoded
PUT
如果PUT路由URL中参数间使用的是&符号,而不是/;则,APIPost测试的URL参数间也要使用&
// 4. 修改商品 put /v1/modPrds
// router.put('/v1/modPrds/:id/:pname/:title/:price',(req,res)=>{...});
// apipost测试 http://127.0.0.1:8080/prd/v1/modPrds/7/apipost/有点sha的软件/888
// apipost测试 http://127.0.0.1:8080/prd/v1/modPrds/7&apipost&有点sha的软件&888
router.put('/v1/modPrds/:id&:pname&:title&:price', (req, res) => );
return;
}
// 修改操作返回的是受影响的行数
if (result.affectedRows > 0) {
res.send({
code: 200,
msg: '修改成功'
})
} else {
res.send({
code: 400,
msg: '修改失败'
})
}
});
})
正则表达式验证的是字符串格式,不是固定死字符串内容。
在JS中,正则表达式使用有两种形式
字面量
构造函数
所谓字面量就是直接使用斜杠/包裹正则表达式。
构造函数则是new RegExp(字符串)
console.log(str.replace(/我草|卧槽|wocao/gi);
.test() 检测是否符合规则(布尔)
.replace() 查找符合规则的字符并使用字符串替换
[开始数字-结束数字] 单个数字的匹配范围
1[0-5]5 指定1和5间数字范围为0-5
125
155
[0-9]可以直接使用d
{次数} 量词,用于修饰字符出现的次数
1[0-5]{2} 指定1后面有两个0-5范围的数字
125
155
^ 指定该字符必须出现在开头的位置
$ 指定该字符必须出现在结尾的位置
^1 指定第一个字符必须为1
1$ 指定最后一个字符必须为1
关键词| 指定匹配文本中出现该关键词
/g 全局查找,匹配文本中所有的
/i 忽略大小写
var str = `有一天,小王来到了小李家,说:我草,你家好大
小李轻蔑回了一句:卧槽,这还算大,其实还有地下室18层
小王补充说:WOCAO,还有地下室!~`;
console.log(str.replace(/我草|卧槽|wocao/gi, "**")); //在正则的最后写gi g:全局 i:忽略大小写
/*
有一天,小王来到了小李家,说:**,你家好大
小李轻蔑回了一句:**,这还算大,其实还有地下室18层
小王补充说:**,还有地下室!~
*/
Git 详细安装教程
查看git版本
git --version
VSC系统(版本控制系统),用于项目中存储、共享、合并、历史回退、代码追踪等功能
2000年之前,使用的是CVS;2010年之前使用SVN;2010年之后使用的是Git
工作目录:是一个目录,用于保存项目中所有的文件
暂存区:是内存中的一块区域,用于临时保存文件的修改
Git仓库:是一个特殊的目录,保存项目所有的文件以及每次的修改记录
在项目目录下右键—-Git Bash Here 命令行操作(Git GUI Here:图形化操作,Git Bash Here:命令行操作)
1)(首次安装后)第一次使用Git前,告诉Git系统你是谁
git config --global user.name "自定义用户名"
git config --global user.email "自定义用户邮箱"
要修改用户名或邮箱,重新执行这语句即可
2)创建Git仓库来管理当前的项目
git init
3)查看当前Git系统的状态
git status
提示:On branch master nothing to commit, working tree clean表示仓库中所有文件已经提交了,没有需要单独管理的文件
4)将文件添加到暂存区
git add 文件名称
如:
git add index.html
添加后可通过git status查看状态
如果需要提交多个文件:
git add 文件名1 文件名2 文件名3 ...
提交全部改变的文件:
注意:删除的文件也算改变,也会被提交
git add .
5)将暂存区所有的文件提交到Git仓库
这里的提交说明是备注
git commit -m "提交说明"
如:
git commit -m "第三次提交01"
6)查看Git仓库中所有的提交日志
git log
注意:当回退到某一版本时,使用了清屏操作后,git log将查询不到之前的该回退之后的提交日志。
这时可以使用
git reflog 查询所有的提交日志
git reflog
7)忽略文件
也就是有些文件或目录不需要提交到仓库,可以设置忽略
在更目录创建一个名为.gitignore的文件,然后在里面写需要忽略的文件或目录
如:
忽略pic目录和tao.txt文件。.gitignore内写:
pic/
tao.txt
注意:.gitignore文件也需要上传到仓库中
平时需要忽略的文件有:node_modules
8)历史回退
git reset --hard 提交的ID
先用git log查询到提交的ID,然后再使用即可
如:
git reset --hard be21883e6cad92bb33683699b030f4932c8f631d
9)分支
从主线中分离出来,不影响其它线程的开发,从而实现并行开发
Git下默认只有一个分支master
①创建新的分支
git branch 分支名称
查看所有的分支
git branch
②切换分支
切换分支前最好先使用git status确保当前工作环境是干净的,避免出现管理错误
git checkout 分支名称
③在该分支上做该模块的开发(add提交,commit标注。。等)
④合并分支
也就是当所有开发完成之后会进行分支项目合并
注意:需要在主分支下进行
git merge 分支名称
当两个进行合并的时候会出现冲突,只需要将冲突的东西去掉即可
如:index.html
111111
<<<<<<< HEAD
<br> user做了修改
=======
<br> product模块进行了修改
>>>>>>> product
只需要将<<<<<<< HEAD、=======、>>>>>>> product去掉
然后,再次git上传即可
10)删除分支
删除已合并的分支
git branch -d 分支名称
强制删除分支(无论是否合并)
git branch -D 分支名称
代码托管平台GitHub、Gitee、Gitlab等
①先创建远程仓库
②使用git push 远程仓库地址 分支名称 命令推送到远程仓库
如:
git push https://gitee.com/Myotsuki/myproduct.git master
③输入gitee或者github的账号密码
控制面板 -> 凭据管理器 -> Windows凭据,找到凭据删除即可
gitee项目页 -> 管理 -> 仓库成员管理 -> 开发者 -> 邀请成员
git clone 仓库地址
如:
git clone https://gitee.com/Myotsuki/myproduct.git
拉取建立在使用过克隆远程代码到本地之后
git pull 远程仓库 分支名称
如:
git pull https://gitee.com/Myotsuki/myproduct.git user
clear
:q
