论文阅读笔记之手术器械分类的注意约束自适应核选择网络(SKA-ResNet)(一)
注意力机制在 NLP领域运用广泛(RNN 及 LSTM的时序注意力,文本序列的注意力机制),计算机视觉任务中也逐渐借鉴这种机制,在深度学习中本身就具备注意力机制,经典分类检测任务中如果可视化特征图则可以清晰地看到目标的响应明显较为突出。
- 为什么还要引入注意力机制?
卷积核作用的感受野是局部的,要经过累积很多层之后才能把整个图像不同部分的区域关联起来,注意力实现通过卷积层池化等操作的不断堆叠而形成的整体效应,在其中一层是很难实现全局操作的。 - 基本思想:
让系统学会注意力——能够忽略无关信息而关注重点信息,通过注意力模块一步到位(相对而言)地实现注意力机制联系特征图全局信息,而非不断重复堆叠算子。

2.2.1 硬注意力(Hard-attention)与软注意力(Soft-attention)
(1)硬注意力(Hard-attention):
- 硬注意力机制是一种非此即彼的做法,直接强调哪些区域是被关注的,哪些区域是不被关注的,可以理解为0/1问题;
- 更加关注图像中的点,图像中的每个点都有可能延伸出注意力;
- 是一个随机的预测过程,更强调动态变化;
- 是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning) 来完
成;
(2)软注意力(Soft-attention):
- 软注意力机制的每个区域被关注的程度高低用0~1的score表示,可以理解为[0, 1]连续分布问题;
- 更关注区域或者通道;
- 是确定性的注意力,学习完成后可以通过网络直接生成;
- 是可微的注意力,在深度学习中,如果想要模型学习注意力机制,注意力模块应该是可微的,这样注意力模块变可以通过梯度更新参数。因此,计算视觉中主要还是应用soft-attenion ,可微性使得soft-attenion机制完美嵌入深度学习模型。
在软注意力机制中,根据注意力机制让模型关注的焦点不同,分为空间域(即特征图域)、通道域、通道空间混合和时序域注意力机制,具体视模型的任务而定。
2.2.2 通道域注意力
(1) Squeeze-and-Excitation Networks(SENet,2017CVPR)
SENet是通道域注意力的典型网络结构,由Momenta公司所作,并赢得ImageNet 2017的图像识别冠军,该网络对通道之间的相互依赖关系进行显式建模,通过注意力机制学习到不同通道的权值(所有通道权值和为1),然后乘上输出通道得到最终的输出,SE通道注意力模块如下图所示。
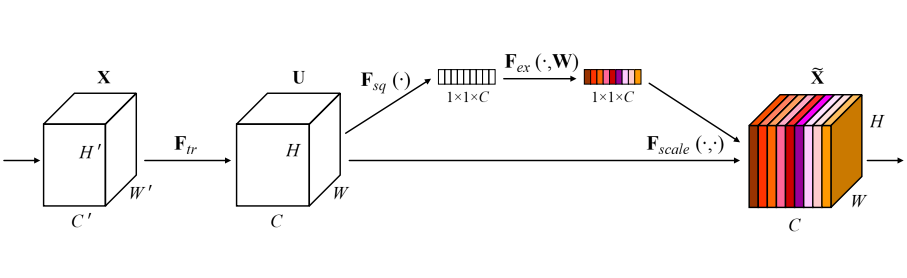
该注意力机制分成三个部分:挤压(squeeze),激励(excitation),以及scale(attention)。 首先将输入特征进行Global AVE pooling,channel 就变成1×1;然后bottleneck,其实就是一个浅层BP神经网络,第一个用来压缩通道,第二个恢复到原始通道数;最后接个sigmoid,生成channel间0~1 的attention weights,最后scale 乘回原输入特征。
论文 https://arxiv.org/pdf/1709.01507.pdf
代码 https://gitee.com/ran-boping/senet.pytorch
(2) Spatial Group-wise Enhance(SEGNet)
SEGNet在SENet的基础上做了些结构上的改动。作者提到,一个完整的feature是由许多sub feature组成的,并且这些sub feature会以group的形式分布在每一层的feature里,但是这些子特征会经由相同方式处理,且都会有背景噪声影响。这样会导致错误的识别和定位结果。所以作者提出了SGE模块,它通过在在每个group里生成attention factor,这样就能得到每个sub feature的重要性,每个group也可以有针对性的学习和抑制噪声。这个attention factor仅由各个group内全局和局部特征之间的相似性来决定,所以SGE非常轻量级。经由训练之后发现,SGE对于一些高阶语意非常有效。实验发现,该网络可以显著提高图像识别任务性能。
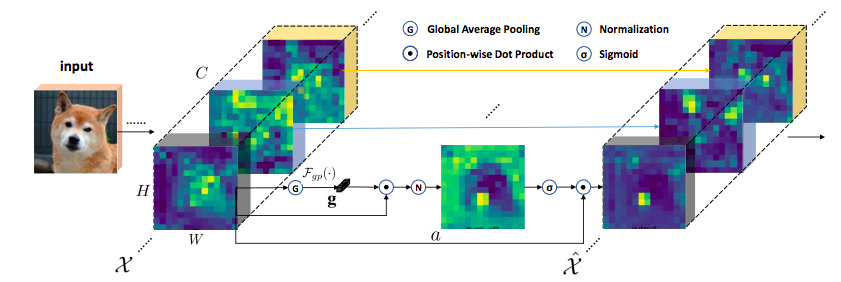
2.2.3 空间域注意力
(1)Spacial Transformer Networks(STN,2015NIPS)
论文认为,卷积神经网络虽然很强,但是仍然在特征图的空间不变性上有缺陷,虽然最大池化max pooling具有平移不变性,但是池化是一种小范围的局部操作,无法覆盖整个特征图,因此论文加入了空间变换模块,计算中涉及到了对整张特征图进行空间变换的操作,变换的焦点是图像的核心语义部分。这也是一种暗含注意力机制的操作,只是没有明说,通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息。具体地,训练出的spatial transformer能够找出图片信息中需要被关注的区域,同时这个transformer又能够具有旋转、缩放变换的功能,这样图片局部的重要信息能够通过变换而被框盒提取出来。既然对特征图进行空间变化,那么该模块的输入与输出的特征图维度不变,这也符合注意力机制的操作。
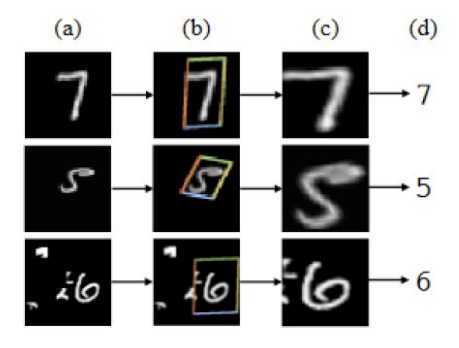
(2) Self-Attention GAN(2018)
Self-Attention在Self-Attention GAN 论文中用于空间域的注意力机制,是特征图的全空间域注意机制,即特征图所有像素之间的相关性,同样摆脱了传统卷积局部操作的限制。论文中对于特征图空间域的操作示意图如下图所示。
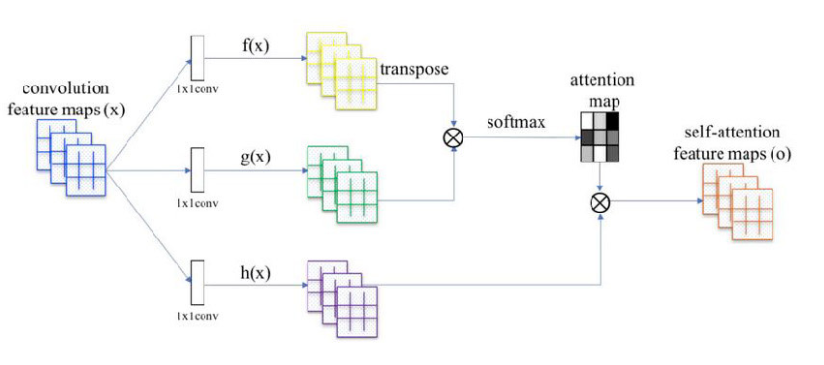
该结构的操作对象也是某一网络结构(resnet、Xception 等)的输出特征图,通常将最后如ResNet的两个下采样层去除使获得的特征图是原输入图像的1/8大小。Self- attention结构自上而下分为三
个分支,分别是query、key 和value。流程如下:
a.对特征图进行并联的二个通道压缩操作(1×1卷积操作),得到query和key,value初始特征图做1×1等通道卷积,通过reshape操作,强行合并query、key和value除通道数外的维度,然后对query和key进行矩阵乘(matmul) 操作,得到新的特征图,该特征图的某一个元素表示其行列 ID对应特征图元素的相关性,整个特征图反映了特征图中任意一个元素受所有像素的影响程度。
b.对自相关特征以行进行Softmax 操作,得到0~1的weights,这里就是我们需要的Self-attention 系数。
c.self-attention系数矩阵与value做matmul,在恢复到原始特征图的维度,最后与原始输入特征图矩阵做加权和。
2.2.4 空间域和通道域混合
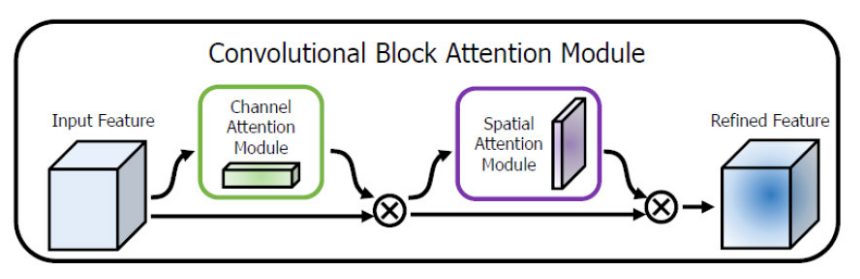
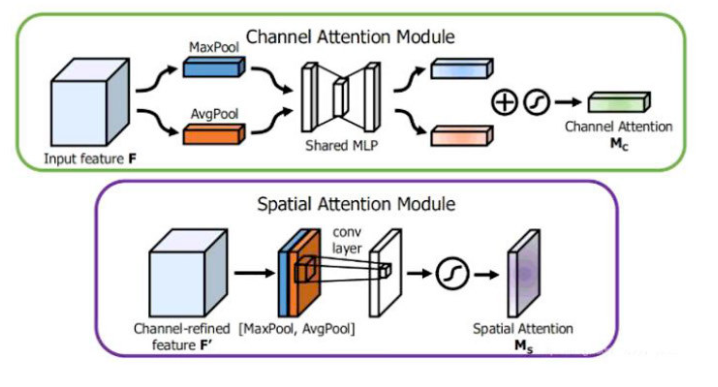
典型网络是CBAM(Convolutional Block Attention Module,2018ECCV) ,CBAM在SENet的基础上接上了空间域注意力,算是对SENet的进一步改进加强,使得该注意力模块结合了通道与空间的注意力机制,不同于SENet的是CBAM在通道与空间注意力上都使用了全局平均池化和全局最大池化,通道域则是加上这两种池化再sigmoid激活,而空间域则是对于特征图上每个像素位置在通道
方向上求均值和最大值得到两个特征图并concat,再卷积得到一个特征图,最后通过sigmoid函数。模块示意图如下图所示。
空间域与通道域展开:
2.2.5 时序域(视频分析)
Self-Attention 定从NLP中借鉴过来的思想,因此仍然保留了Query, Key 和Value等名称,原始论文《Attention Is All You Need》描述了其在机器翻译中的应用及有效性。在计算机视觉领域,一篇关于Self-Attention研究非常重要的文章《Non-local Neural Networks》 在捕捉长距离特征之间依赖关系的基础上提出了一种非局部信息统计的注意力机制——Self Attention,上文提到的Self Attention GAN也是其应用于图像空间域注意力机制的案例,后续计算机视觉的深度模型的很多改进版本均
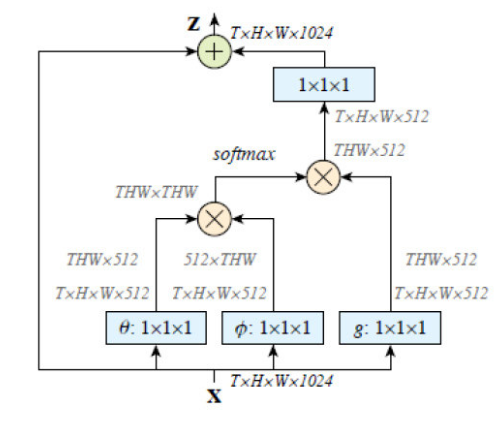
嵌入了该结构。Non- local论文中主要将其用于视频分类的案例中,研究对象为时序视频。这里应用的Self-Attention,则是对特征时序域做了注意机制,算法的流程和空间域的Self -Attention类似,只是此时是在时序上帧特征序列的相关性做了自注意力机制,即计算所有帧中的所有像素对当前帧的像素的关系权值的注意力机制,并且在通道压缩阶段query、key和value进行了相同比例的通道 压缩,最后有一个恢复通道的操作,其计算示意图如下图所示。
参考博客:
计算机视觉中注意力机制(Attention Mechanism)
视觉注意力机制 | 视觉注意力机制用于分类:SENet、CBAM、SKNet
SENet
SGE——Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
