目录
一.假设检验
1.假设检验的基本步骤(以“小鼠血压实验”为例)
2.假设检验的两类错误(Type I, Type II Errors)
二.多重检验的难点
三.家族wise错误率(Family – Wise Error Rate, FWER)
1.控制FWER的方法
(1)邦费罗尼法(Bonferroni Method)
(2)霍尔姆逐步下降法(Holm’s Step – Down Procedure)
2.特殊场景下的FWER控制方法
(1)图基法(Tukey’s Method)
(2) 谢弗法(Scheffé’s Method)
3.FWER 与检验效力(Power)的权衡
四.错误发现率(False Discovery Rate, FDR)
五.重抽样方法(Re – Sampling Approach)在计算p值和控制错误发现率(FDR)中的应用
1.重抽样方法计算p值
2.重抽样方法控制错误发现率(Re – Sampling for FDR)
3.重抽样方法控制FDR
在当代大数据场景中,我们常面临 “海量数据”,进而需要检验大量原假设(null hypotheses)。比如在生物研究中,要检验 m 个原假设(),其中表示 “对照组小鼠第 j 个生物标记物的期望值,与治疗组小鼠第 j 个生物标记物的期望值相等”。但是,进行多重检验时,若解读结果不谨慎,容易错误地拒绝过多原假设(即把 “无差异” 的情况错误判定为 “有差异”)。
为了解决这个问题,错误发现率被提出。错误发现率的概念可追溯到 20 世纪 90 年代,21 世纪初因 “基因组学大规模数据集” 而流行。这类数据集的特点是不仅规模大,还通常为 “探索性目的” 收集。研究者要检验大量原假设,而非少数预先指定的原假设。如今,几乎所有领域都在收集无预先指定原假设的海量数据。错误发现率非常适合 “现代大数据探索性分析” 的现实需求,能有效控制 “错误拒绝原假设的比例”。下面以经典统计技术p值为核心,量化假设检验的结果。
一.假设检验
1.假设检验的基本步骤(以“小鼠血压实验”为例)




下图展示的是标准正态分布的概率密度函数,横轴表示检验统计量的取值。在假设检验中,检验统计量是用于衡量 “数据与原假设一致性” 的指标(比如前文提到的两样本 t 统计量T)。这里假设检验统计量服从标准正态分布(N(0, 1))。纵轴表示概率密度,它描述了 “检验统计量取某一值时,其出现的‘密度程度’”(概率密度函数下的面积代表概率,总面积为1,即所有可能取值的概率和为1)。
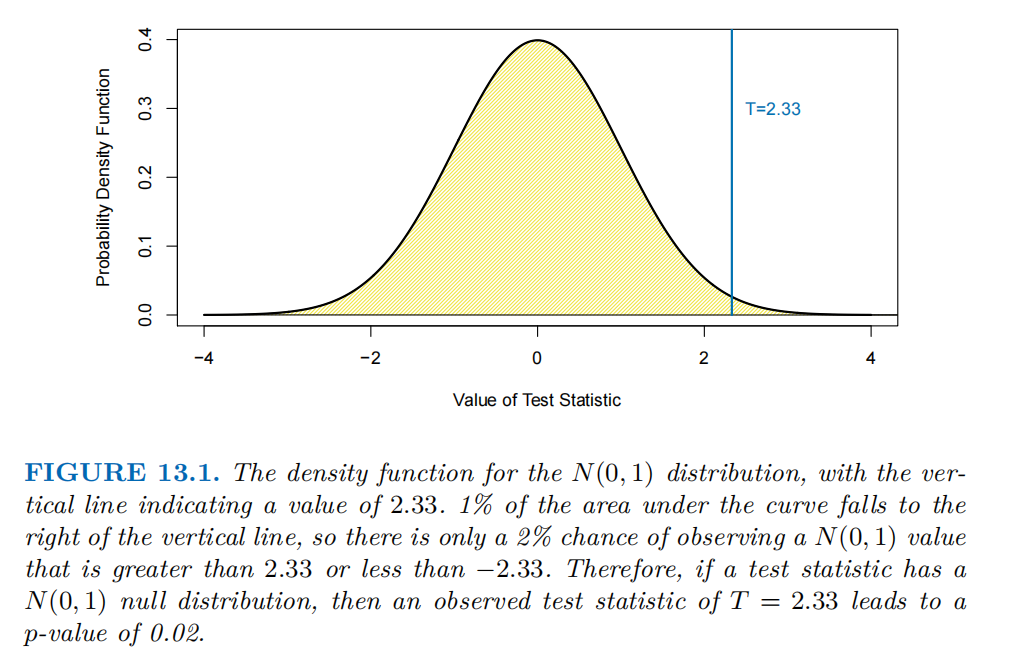
蓝色竖线(T = 2.33)表示观测到的检验统计量取值。比如在某次假设检验中,计算得到检验统计量T = 2.33。曲线下 “竖线右侧的面积” 为1%,即检验统计量T > 2.33的概率是1%;同理,“竖线左侧T < -2.33的面积” 也为1%。因此,“检验统计量取值大于2.33或小于-2.33” 的概率为1% + 1%= 2%
而p值的定义是在原假设为真的前提下,观测到与当前检验统计量相等或更极端结果的概率。这里 “更极端” 就是指 “比2.33大,或比-2.33小” 的情况。所以,当观测到检验统计量T = 2.33时,p值为0.02。
这表示如果原假设是真的,那么观测到 “这么大或更大 / 更小” 的检验统计量的概率只有2%。由于p值很小(0.02 < 0.05等常见显著性水平),这会成为 “拒绝原假设” 的证据,因为 “原假设为真时,出现当前数据的可能性极低”,更可能是备择假设成立。当然,若显著性水平=0.01,由于0.02>0.01,则不能拒绝原假设。
总结:
为预先设定的 “可接受的第一类错误率上限”,例如,=0.05表示每100次原假设为真的检验中,平均有 5 次会错误拒绝H0。下面会讲到第一类错误率,第一类错误率表示原假设为真时,错误拒绝H0的概率。
p<,可推翻原假设:
p<说明 “在原假设为真的情况下,观测到当前这么极端(或更极端)数据的概率只有 2%”,这个概率比我们预先设定的 “可容忍的第一类错误率上限(5%)” 还要小。
这意味着,“原假设为真却错误拒绝它” 的风险(第一类错误率)实际比我们能容忍的 5% 更低,所以我们有足够的理由拒绝原假设。p,不能推翻原假设:
则说明 “在原假设为真的情况下,观测到当前数据(或更极端数据)的概率不低于,此时 “原假设为真却错误拒绝它” 的风险超过了我们能容忍的上限,所以我们没有足够的理由拒绝原假设,选择不拒绝原假设。
2.假设检验的两类错误(Type I, Type II Errors)

第一类错误率表示原假设为真时,错误拒绝H0的概率,通常要求控制在水平,即预先设定的 “可接受的第一类错误率上限”(比如=0.05,表示最多允许 5% 的第一类错误率)。检验效能则是1-,代表备择假设为真时,正确拒绝H0的概率。
第二类错误率表示原假设为假时,错误地不拒绝原假设的概率,通常用表示。而检验效能则是1-,代表原假设为假时,正确拒绝原假设的概率。
两类错误的权衡:
两类错误存在 “此消彼长” 的权衡,若严格控制第一类错误(如降低),会更难拒绝H0,导致第二类错误率上升;若放宽第一类错误的控制,第二类错误率会下降,但 “假阳性结论” 的风险增加。
通常认为第一类错误更 “严重”,因为会错误宣称 “存在科学发现”,因此假设检验多以 “控制第一类错误率” 为核心(如要求)。
二.多重检验的难点
对于单次检验的第一类错误控制,若单次检验中,设定p值阈值为 = 0.01,则 “原假设H0为真时,错误拒绝H0的概率不超过1%”。
而对于多重检验,当要检验m个原假设时,若简单地对每个假设都用 “p < 0.01则拒绝” 的规则,会导致第一类错误(错误拒绝真原假设)的数量大幅增加,也就是多重检验的 “假阳性膨胀”。
数学推导:

借助下面案例来理解“假阳性膨胀”:

下表是假阳性膨胀的量化框架:

实际中,V, S, U, W的具体值未知,但能观测到 “总拒绝数R = V + S”和 “总不拒绝数m – R = U + W”。
在多重检验中,由于V会随检验次数m增加而膨胀,导致R中 “假阳性的占比” 或 “假阳性的绝对数量” 大幅上升,这就是假阳性膨胀。实际中V的具体值未知,但通过观测R等总量,能为 “控制假阳性膨胀”提供分析基础。
三.家族wise错误率(Family – Wise Error Rate, FWER)
FWER是在多重检验(同时检验m个原假设)中,至少出现一次第一类错误(错误拒绝真原假设)的概率。
用公式表示为:
![]()
基于 “单次检验第一类错误率”的数学推导如下:

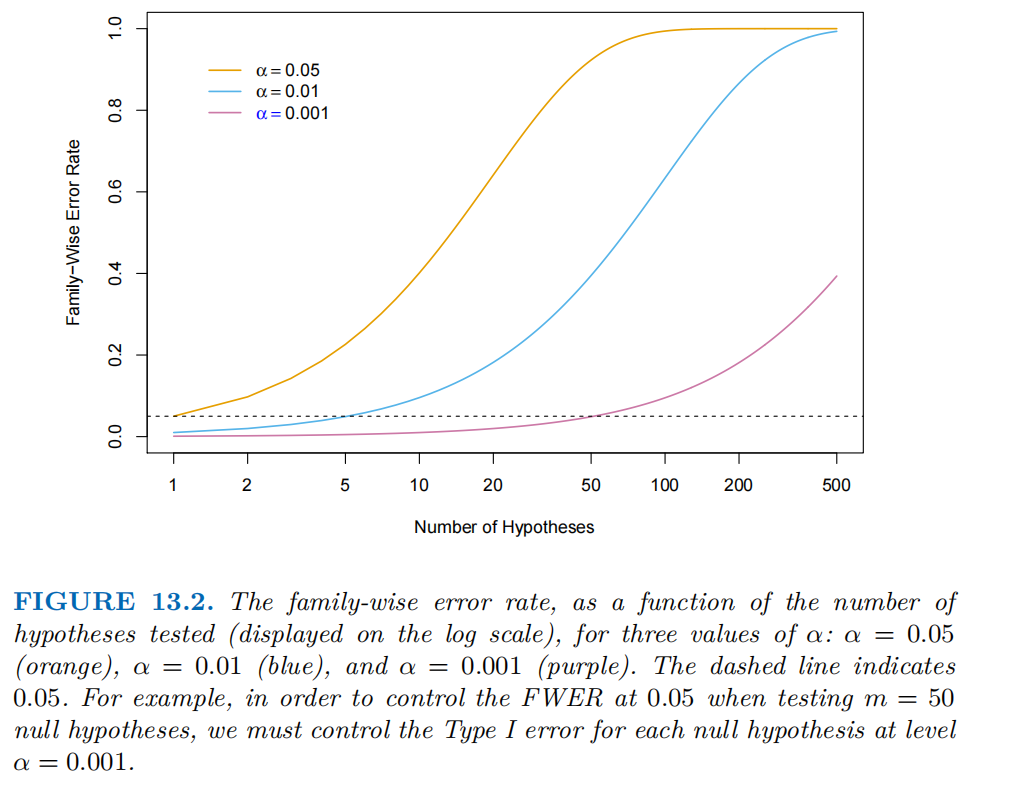
下图展示了FWER 随检验数量m变化的趋势,不同曲线对应不同的单次检验显著性水平( = 0.05)、( = 0.01)、( = 0.001)。
多重检验中,若直接用 “单次检验的显著性水平”(如 = 0.05)来判断每个原假设的拒绝与否,FWER会随 “假设数量增加” 急剧上升,远超过目标控制水平(图中虚线表示FWER的目标控制水平,0.05)。
如下图所示,当 = 0.05(橙色曲线)时,假设数量仅几十时,FWER就接近1(几乎必然出现第一类错误)。当 = 0.01(蓝色曲线)时,FWER上升速度比 = 0.05慢,但假设数量超过 100 时,FWER 也会大幅超过0.05。当 = 0.001(紫色曲线)时,FWER上升最慢,只有当假设数量非常大(如几百)时,才会接近0.05。

1.控制FWER的方法
(1)邦费罗尼法(Bonferroni Method)

下表展示了 “Fund 数据集” 中前 5 位对冲基金经理的 “月度超额收益率” 相关统计量,以及对 “经理平均超额收益率为0” 这一原假设的检验结果。列的含义如下:

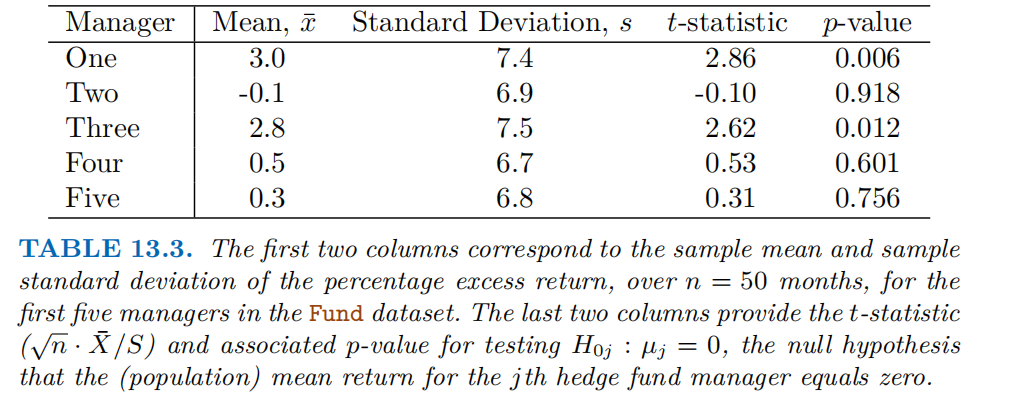
可以看到,若要控制FWER为0.05,单次检验的需设为0.05/5 = 0.01。此时只有第一个经理的p值(0.006)小于 0.01,会被拒绝;而若用单次=0.05,会错误拒绝更多真原假设,导致FWER超过 0.05。
邦费罗尼法的特点:简单易实现、不要求检验独立,但过于 “保守”(倾向于少拒绝原假设,易犯第二类错误)。
(2)霍尔姆逐步下降法(Holm’s Step – Down Procedure)

依然以下表举例,采用霍尔姆逐步下降法进行检验:

霍尔姆逐步下降法的特点:不要求检验独立,比邦费罗尼法更 “有力”(power更高,即更易拒绝假原假设),同时仍能控制FWER。
下图对比了邦费罗尼法和霍尔姆逐步下降法在控制家族 wise 错误率(FWER)时的表现。
横轴(Ordering of p-values)是m = 10个原假设的p值。纵轴(p-values (log scale))是p值的对数值,方便展示极小的p值差异。
黑色点对应m0 = 2个真原假设,即原假设实际为真,若被拒绝则属于第一类错误。红色点对应剩下的假原假设,即原假设实际为假,应被拒绝。
黑色水平线是邦费罗尼法的 “拒绝阈值”。所有p值低于该线的原假设会被邦费罗尼法拒绝。
蓝色曲线是霍尔姆法的 “拒绝阈值”。所有p值低于该曲线的原假设会被霍尔姆法拒绝。
左面板中两种方法拒绝的假原假设数量差异较小。中间面板,霍尔姆法比邦费罗尼法多拒绝 1 个假原假设。右面板,霍尔姆法比邦费罗尼法多拒绝 5 个假原假设。
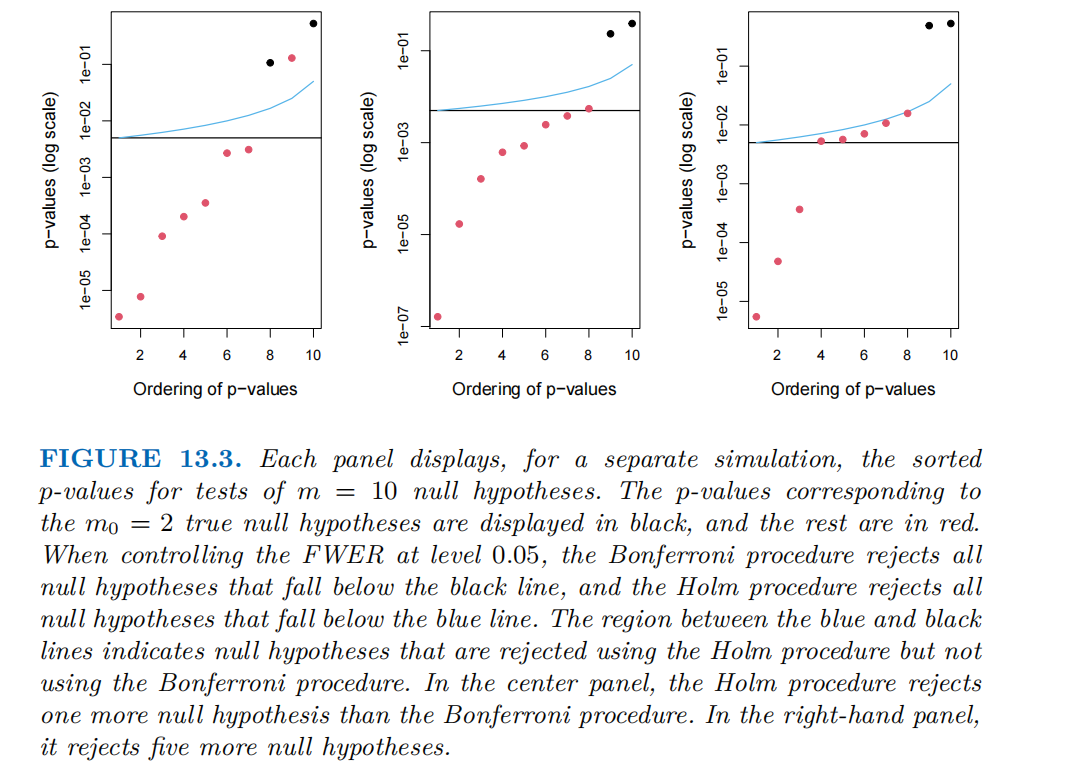
可以看到,控制 FWER(目标水平为 0.05)时,邦费罗尼法偏保守性,黑色线的阈值很低,导致 “只有极少数p值极小的假原假设会被拒绝”,容易遗漏应拒绝的假原假设(犯第二类错误)。霍尔姆法更加灵活,蓝色曲线的阈值高于黑色线,且形状更 “宽松”,因此 “更多假原假设会被霍尔姆法拒绝”(蓝色线与黑色线之间的区域,是 “霍尔姆法拒绝但邦费罗尼法不拒绝” 的假原假设)。
总结:
霍尔姆法在控制FWER的同时,比邦费罗尼法更 “有力”(power 更高),即能拒绝更多实际为假的原假设,减少第二类错误(错误保留假原假设),因此更适合多重检验场景。
2.特殊场景下的FWER控制方法
(1)图基法(Tukey’s Method)

下图对应的模拟场景为G = 6个均值,其中(1= 2 = 3 = 4 = 5 6),因此m = 6 * 5 / 2 = 15个原假设中,10个为真(对应黑色点)、5个为假(对应红色点)。
黑色水平线是邦费罗尼法的 “拒绝阈值”,即所有p值低于该线的原假设会被邦费罗尼法拒绝。
蓝色水平线是图基法的 “拒绝阈值”,即所有p值低于该线的原假设会被图基法拒绝。
绿色水平线表示“不进行多重检验校正” 时的 “第一类错误控制阈值”,即所有p值低于该线的原假设会被拒绝,但此时FWER 会大幅膨胀。
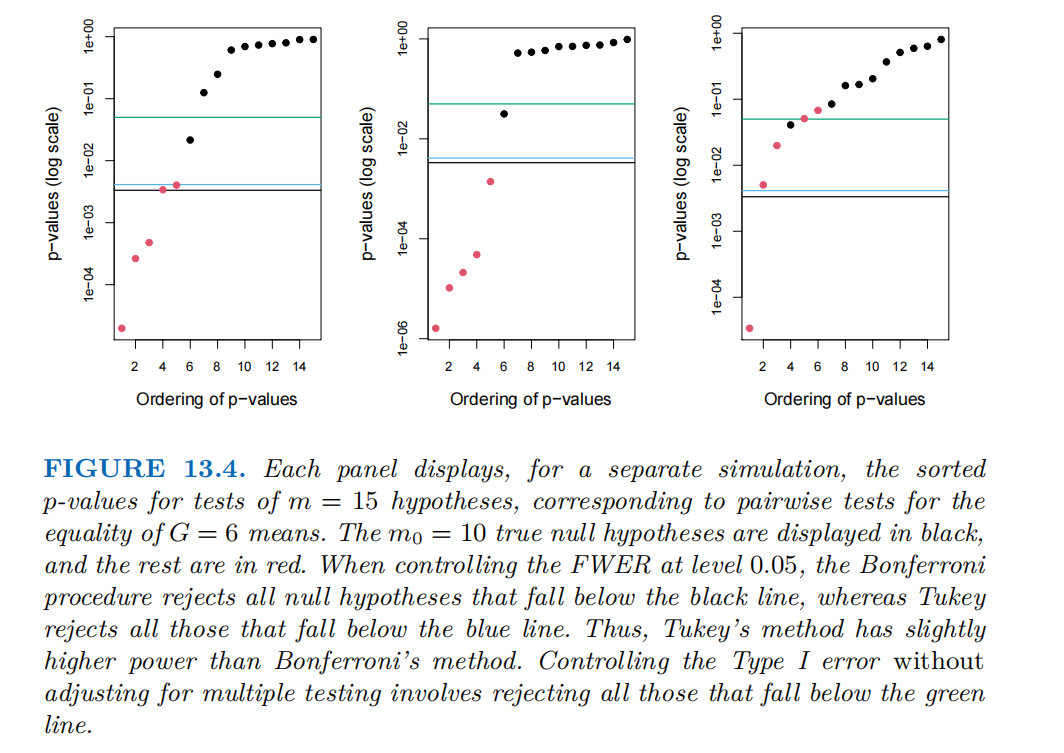

总结:
三个子图是不同的模拟场景,但核心趋势一致:
1.图基法的拒绝阈值始终比邦费罗尼法高,因此能拒绝更多假原假设,也就是说图基法在控制FWER的同时,比邦费罗尼法更灵活、更有力,能更有效地识别假原假设。
2.无校正时拒绝的原假设最多,但FWER失控,即虽然会拒绝很多原假设,其中必然包含大量 “错误拒绝的真原假设”,从而让 “至少犯一次第一类错误” 的概率远远超过预先设定的控制水平。若 FWER 设定为 0.05,表示 “我们能容忍‘至少犯一次第一类错误’的概率不超过 5%”;若实际 FWER 达到 0.1,则 “至少犯一次第一类错误” 的概率上升到了10%,错误率的容忍度被突破,错误拒绝真假设的概率就被提高了。
(2) 谢弗法(Scheffé’s Method)


假设我们希望控制FWER为,比如=0.05,即 “在所有可能的线性组合检验中,至少犯一次第一类错误的概率不超过”,如何确定:


的推导是针对 “所有可能的线性组合检验” 的整体错误率控制,因此无论后续要检验 “哪一种线性组合”(比如换一组经理的均值组合),都可以用同一个判断,无需因为 “检验的线性组合不同” 而重新计算阈值。所以谢弗法的核心优势在于同一阈值可用于 “任意分组的线性组合检验”,无需额外调整多重检验。
3.FWER 与检验效力(Power)的权衡
效力是 “成功拒绝的假原假设数” 与 “总假原假设数” 的比值:
![]()
下图对应的模拟场景为90%的原假设为真,剩余10%为假。
展示了检验效力(Power)与家族wise错误率(FWER)之间的关系,同时体现了检验次数m对这种关系的影响。横轴为家族wise错误率,纵轴为检验效力,垂直虚线表示标记FWER为0.05,即常见的 “控制第一类错误率为5%” 的目标。
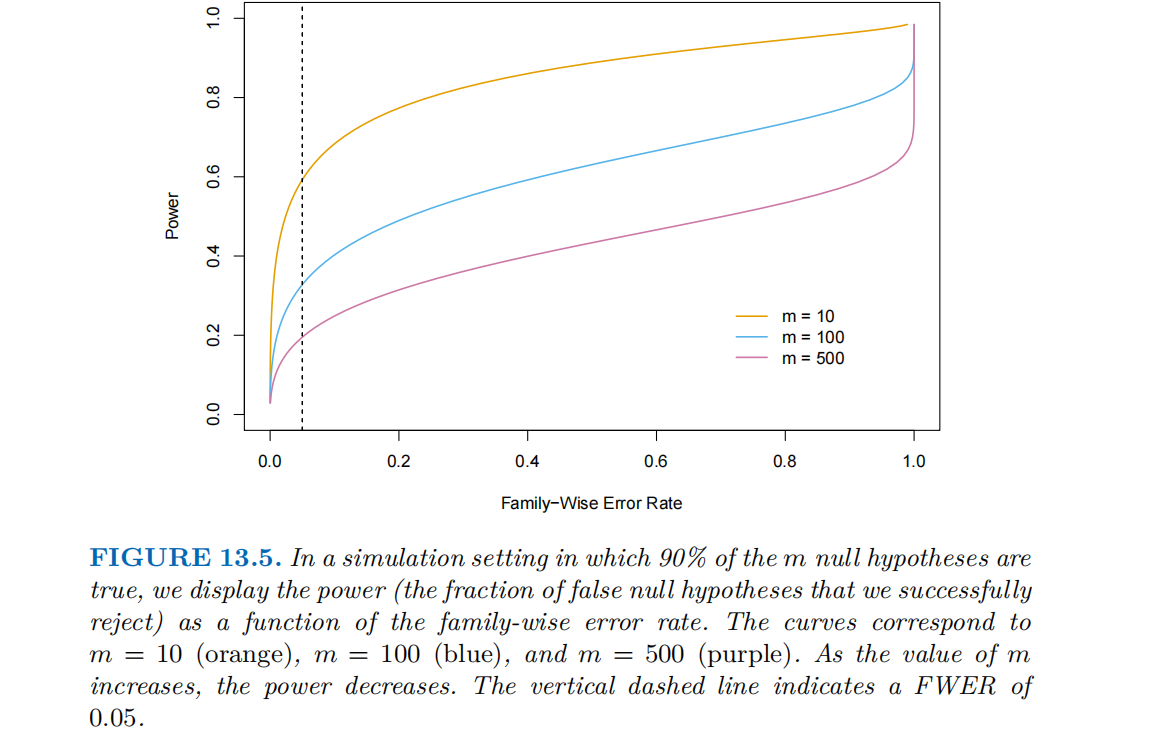
从图中可以得出以下两个结论:
(1)FWER与效力的权衡:
当FWER增大时,效力上升。因为允许 “更多第一类错误(错误拒绝真原假设)”,意味着我们更 “大胆” 地拒绝原假设,因此更有可能拒绝真正的假原假设(提高效力)。
当FWER减小时,效力下降。为了严格控制 “错误拒绝真原假设” 的概率,我们会更 “保守” 地拒绝原假设,导致真正的假原假设也更难被拒绝(降低效力)。(2)检验次数m对效力的削弱:
当检验次数m增加时,相同FWER下,效力显著下降:
如图所示,当 FWER = 0.05(垂直虚线处):m = 10时,效力约为0.6(能正确识别60%的假原假设);m = 100时,效力降至约0.2(仅能正确识别 20% 的假原假设);m = 500时,效力接近 0(几乎无法正确识别假原假设)。
原因如下:
控制 FWER 的核心是 “保证错误拒绝真原假设(第一类错误)的概率不超过”。当m很大时,“真原假设的数量” 占比越高(图中模拟场景是 90% 的原假设为真),为了满足这一保证,会 “被迫少拒绝甚至不拒绝原假设”,导致效力极低。因为若拒绝过多,“错误拒绝真原假设” 的概率会超过。
四.错误发现率(False Discovery Rate, FDR)

控制FDR的经典方法为本杰明尼 – 霍奇伯格流程(Benjamini – Hochberg Procedure),步骤如下:

下图对比了邦费罗尼法(控制FWER)和本杰明尼 – 霍奇伯格法(控制FDR) 在“Fund 数据集(m = 2000)个检验)” 中的表现。横轴是对m = 2000个检验的p值进行从小到大排序后的序号;纵轴为p值的大小。

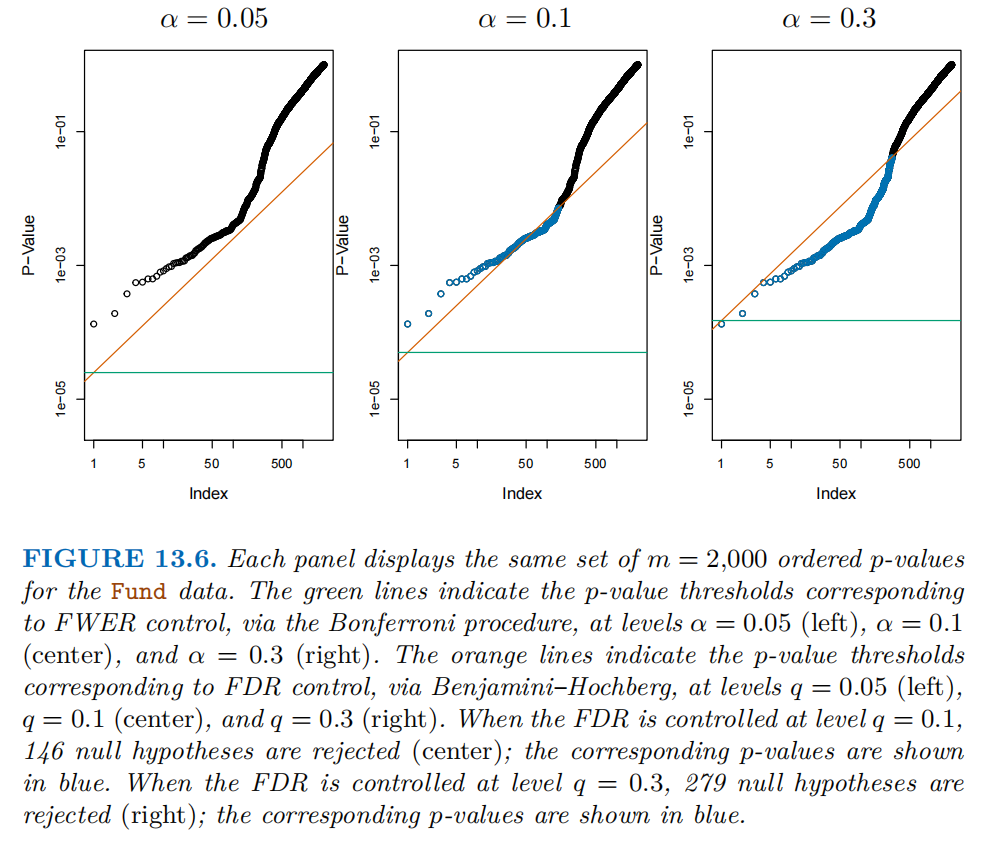


总结:
FDR控制比FWER控制更灵活、更有力。可以看到,在相同错误率控制水平下,FDR控制能拒绝更多原假设(提高检验效力),且随着FDR控制水平 q 的增大,拒绝的原假设数量显著上升,但代价是接受一定比例的假阳性,即错误地拒绝原本为真的原假设。FDR在 “大量检验场景” 下更具优势。
FDR是FWER的 “灵活替代”,适合“大量检验、探索性分析” 场景。本杰明尼-霍奇伯格流程是控制FDR的实用工具,能在保证 “假阳性比例可控” 的前提下,显著提高检验效力,至今仍被广泛应用。
五.重抽样方法(Re – Sampling Approach)在计算p值和控制错误发现率(FDR)中的应用
1.重抽样方法计算p值


步骤如下:

下图展示了Khan数据集中第11个基因的 “检验统计量零分布”。
横轴表示检验统计量(双样本t统计量)的取值范围(从-4到4)。纵轴表示零分布的 “概率密度”(黄色柱形是重抽样零分布的近似,橙色曲线是理论零分布)。蓝色竖线是第11个基因的实际检验统计量T = -2.0936(近似为T = -2.09)。该基因的理论p值为0.041,重抽样p值为0.042。
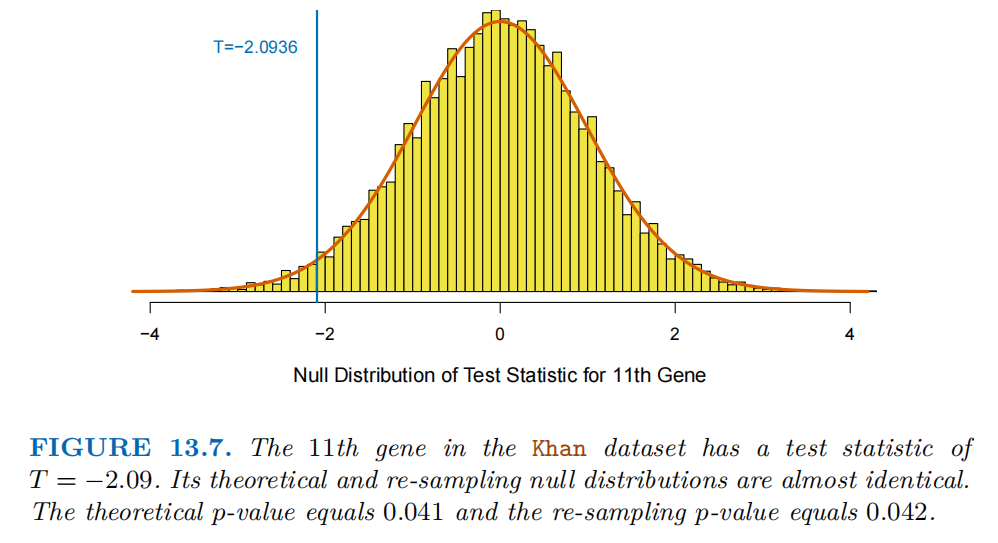

理论零分布(如t分布)的使用依赖 “数据正态性、方差齐性” 等假设。重抽样(置换法)不依赖这些假设,是 “非参数” 的近似方法。
当 “理论零分布与重抽样零分布一致” 时,说明数据满足理论分布的假设,此时两种方法均可信赖;且重抽样p值与理论p值的微小差异,是重抽样 “有限次置换(如B = 10000)” 带来的随机误差,不影响结论。
总结:
理论零分布与重抽样零分布几乎一致,因此理论p值(0.041)和重抽样p值(0.042)差异极小,说明此时理论分布可靠,重抽样与理论方法结果一致。
下图展示了Khan数据集中第877个基因的 “检验统计量零分布”。第 877 个基因的实际检验统计量T = -0.5696(近似为T = -0.57)。该基因的理论p值为0.571,重抽样p值为0.673。
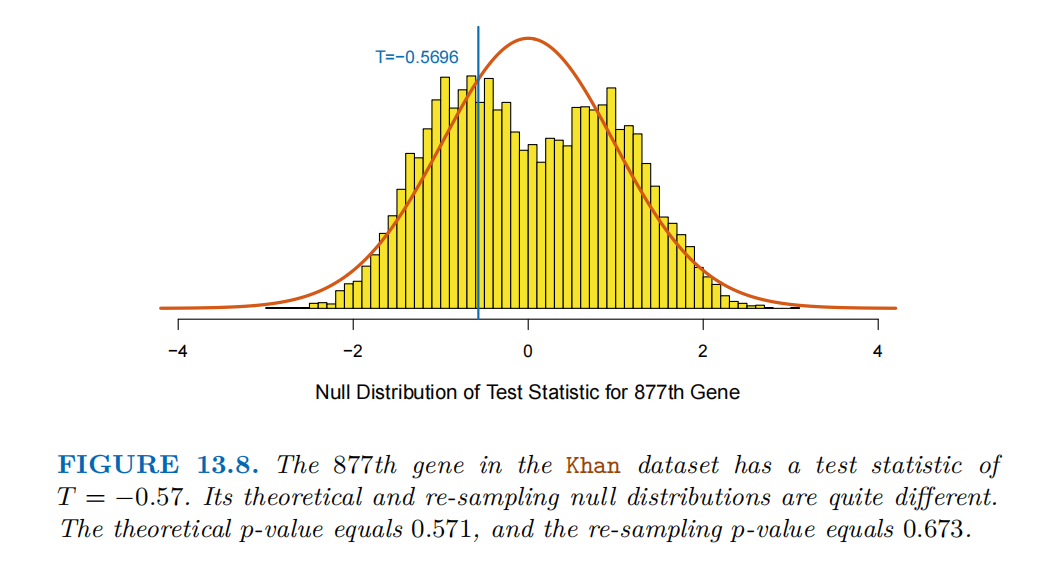

理论零分布(如t分布)的使用依赖 “数据正态性、方差齐性、无极端值” 等假设。重抽样(置换法)不依赖这些假设,是 “非参数” 的近似方法,更能反映数据的实际分布特征。
当 “理论零分布与重抽样零分布差异大” 时,说明数据不满足理论分布的假设(如图中可能存在极端值、偏态分布等),此时理论方法的p值会不可靠,而重抽样方法的结果更能反映真实的统计显著性。
总结:
因存在极端值,数据分布偏态,理论零分布与重抽样零分布差异显著,导致理论p值0.571和重抽样p值0.673差异大,此时理论分布不可靠,重抽样结果更可信。
所以,重抽样(置换法)特别有用的两种场景:

2.重抽样方法控制错误发现率(Re – Sampling for FDR)


也可按照下面的公式先计算每个原假设的重抽样p值:
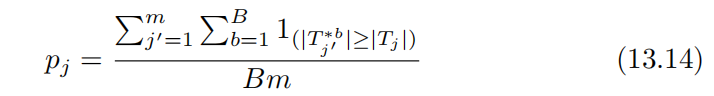
综合所有检验的置换信息,再对这些重抽样p值应用本杰明尼-霍奇伯格法。这种方法与上述直接估计FDR的置换法等价。
3.重抽样方法控制FDR
使用重抽样方法估计双样本 t 检验错误发现率(False Discovery Rate,FDR) 的步骤如下:

下图展示了在Khan数据集(包含2308个基因)中,对比两种方法控制错误发现率(FDR)的效果。
横轴(Number of Rejections)是被拒绝的原假设数量(从 1 到 2308,对应 “p值最小的k个基因” 的原假设被拒绝)。纵轴(False Discovery Rate)是估计的错误发现率,即 “被拒绝的原假设中,错误拒绝的真原假设(假阳性)所占的比例”。
橙色虚线表示本杰明尼-霍奇伯格方法(基于理论p值控制FDR)。蓝色实线表示重抽样方法(具体步骤如上,B= 10000次置换)。
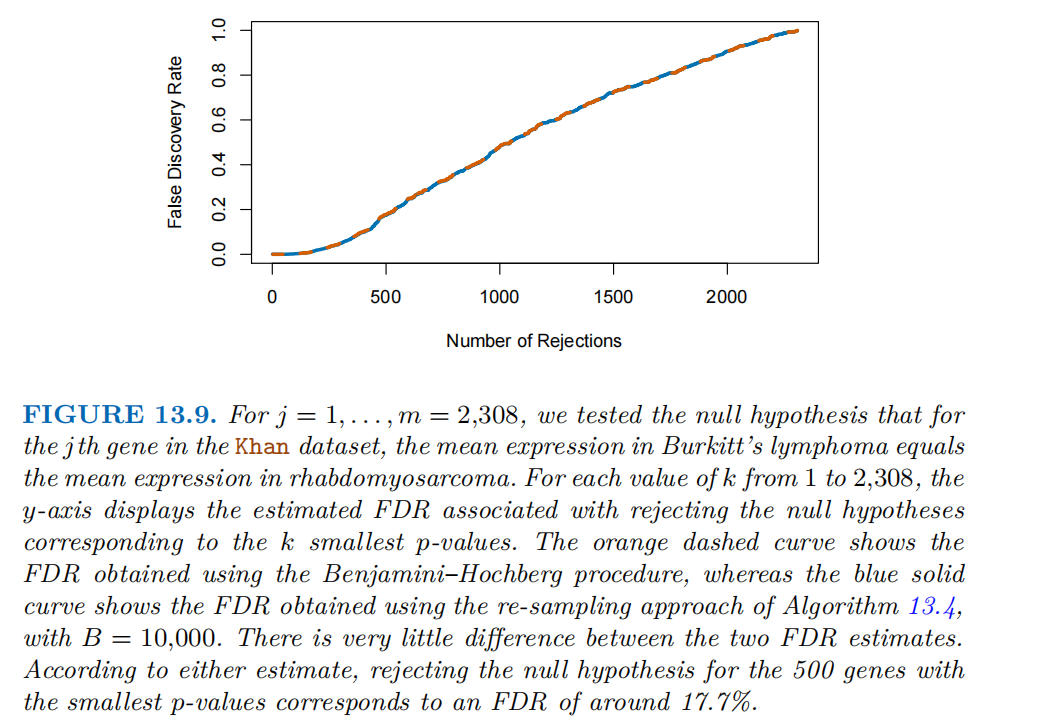

本杰明尼-霍奇伯格方法依赖理论p值和 “原假设的理论零分布”(如正态分布、t分布等)来控制 FDR。重抽样方法不依赖理论分布,通过 “置换观测值模拟零分布” 来估计FDR,更适用于 “理论分布假设不成立(如小样本、偏态数据)” 的场景。
图中两者结果一致,说明在Khan数据集的基因表达分析中,理论分布假设近似成立,因此两种方法的FDR控制效果等价;同时也验证了重抽样方法在理论分布可用时,能与经典方法达到相同的 FDR 控制精度。
总结:
重抽样方法是 “理论分布不可用/不可靠” 时的有力工具,既能计算可靠的p值,也能有效控制 FDR;在实际应用中,其FDR控制效果与经典方法(如本杰明尼-霍奇伯格法:基于理论p值控制FDR)相近,且更灵活(不依赖理论分布假设)。
