当一位病理医生在显微镜前观察组织切片时,他就像一位试图破解复杂案件的侦探——每一个细胞形态、每一处组织结构的异常,都是指向疾病真相的“线索”。
但如果这位“侦探”想借助人工智能(AI)提升破案效率,却会遇到一个棘手问题:能用来训练AI的“线索库”(病理图文数据)实在太少了。
传统病理领域的图文数据集要么规模微小(如ARCH仅7614对图文),要么覆盖范围有限(如OpenPath虽达20万对,仍难满足多亚专科需求),导致病理AI始终“吃不饱”,难以应对千变万化的疾病亚型。
而今天要介绍的QUILT-1M,正是为解决这一困境而生的“超级线索库”——它是一个病理领域的视觉-语言数据集,包含100万组病理图像与文字描述对,不仅填补了数据缺口,更通过创新的数据收集与处理逻辑,让病理AI第一次能“读懂”病理图像背后的复杂医学语义。

病理AI的核心痛点,本质是“优质数据稀缺”。
一方面,病理图像(尤其是全切片图像WSI)体积庞大、标注成本极高,单张WSI标注可能需要数小时;
另一方面,医疗数据隐私限制严格,公开可用的标注数据少之又少。
此前最大的公开病理图文数据集OpenPath仅有20万组数据,远不及自然语言领域动辄千万级的数据集规模。
QUILT-1M的突破,首先在于找到了一个“被忽略的宝库”——YouTube病理教育视频。
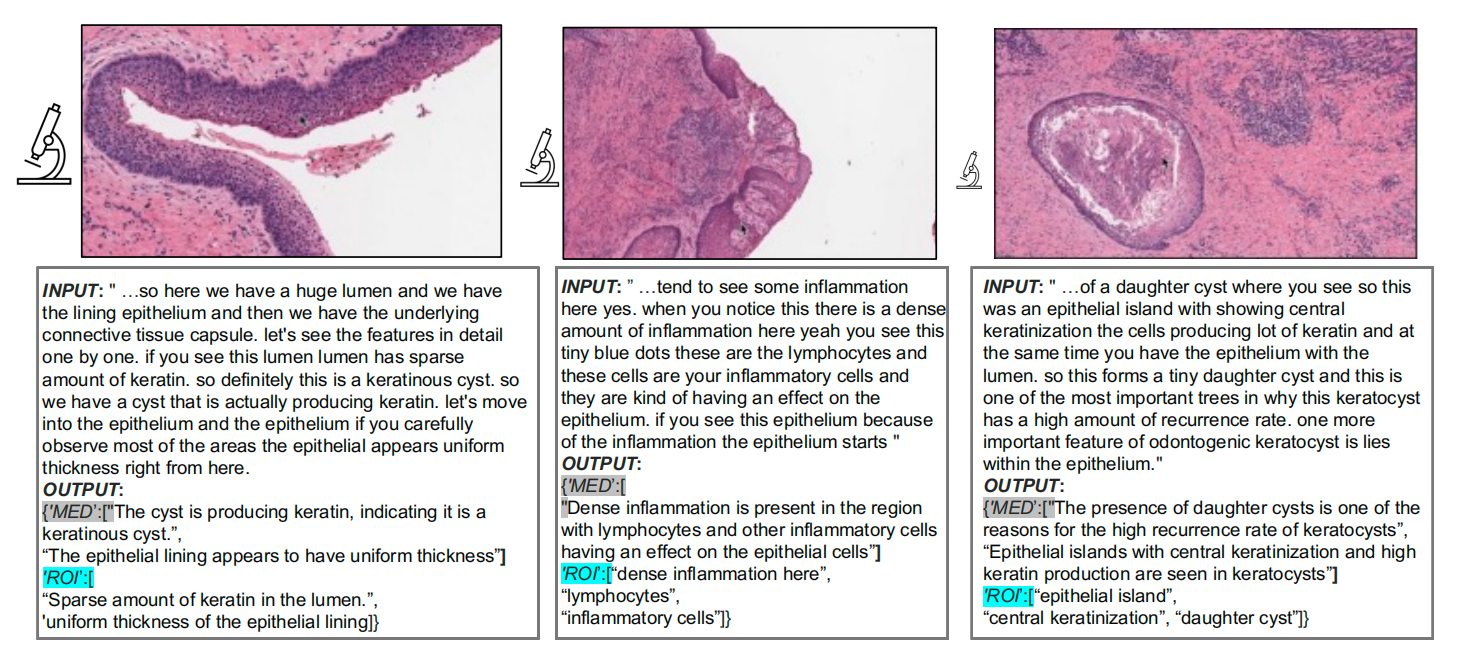
这些由资深病理医生录制的视频,往往包含“边操作显微镜边讲解”的场景:医生会放大到10倍、20倍甚至40倍视野,指着特定区域说“这里是上皮岛,有中央角化,是角化囊肿的典型特征”。
这种“视觉+语言”的天然配对,正是训练病理AI最宝贵的素材。
研究团队从1087小时的YouTube视频中,先筛选出“叙事型视频”(即医生持续讲解病理图像的视频,而非静态幻灯片展示),再从中提取有效信息。
这一步就像从海量教学视频中挑出“最适合做笔记的课程”——不仅要看内容是否专业,还要确保画面与讲解高度匹配。
加入团队
罗小罗团队是一支以国内外硕博为主的科研团队,覆盖影像组学、病理组学以及基因组学等医学AI主流研究领域。
团队目前拥有7名副教授,60+硕博,多名成员以第一作者身份在Nature(2篇)、Nature Communications、Advanced Science以及Radiology等顶级期刊发表过论文。
如果想要加入我们团队,欢迎投递个人简历到团队邮箱:lxltx2025@163.com
医学AI交流群
目前小罗全平台关注量120,000+,交流群总成员3000+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
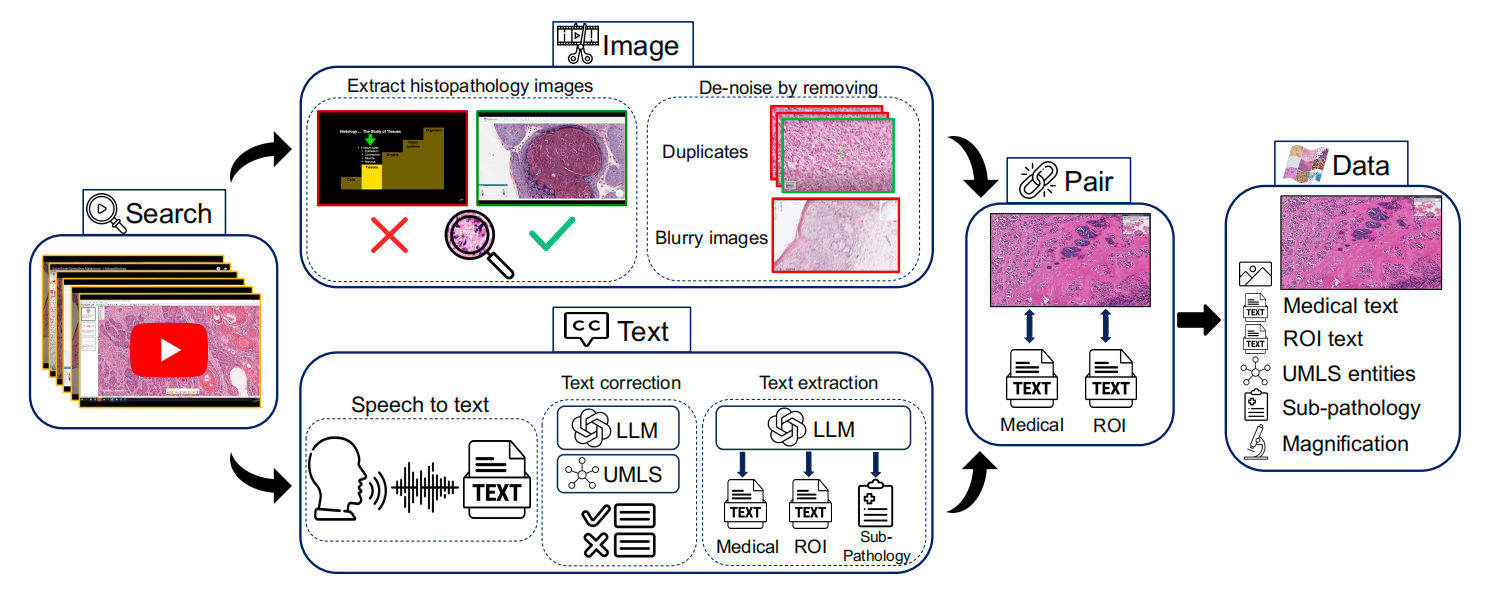
要将杂乱的视频转化为标准的“图像-文字”配对数据,QUILT-1M的制作过程就像一条精密的“食品加工线”,每一步都要兼顾“去杂质”与“保营养”。
筛选“优质原料”——挑对视频
不是所有YouTube病理视频都能用。
团队首先用关键词(覆盖18个病理亚专科,如皮肤病理、胃肠病理)搜索视频,排除订阅量超30万的“泛科普频道”(避免非专业内容),只保留“小而专”的教育频道。
接着,通过两个关键筛选:
- 内容有效性:用AI模型提取视频关键帧(画面变化明显的帧),再用3个病理图像分类器判断是否包含真实病理切片(排除动画、示意图);
- 叙事风格:随机选关键帧,计算与后续帧的相似度——如果医生在讲解时频繁放大、移动视野,但核心区域画面稳定(相似度≥0.9),就属于“叙事型视频”(类似老师在黑板上指着某个公式讲解,不会频繁切换黑板)。
最终,团队从6.5万条候选视频中,筛选出4504条符合要求的叙事型视频,这是保证数据质量的基础。
提取“核心成分”——抠出有用图像
视频里的画面杂乱,可能有医生的手、窗外的光,甚至镜头晃动。
团队的目标是提取“纯净的病理图像”:
- 先将视频按关键帧分割成“时间块”(比如某30秒内画面稳定,算一个块);
- 对每个块,找“稳定帧”——如果块内有连续静止的画面,就取这些帧的“像素中位数”(避免模糊,类似给晃动的照片去重);如果没有稳定帧,就用图像相似度算法挑出最不重复的帧(防止同一画面多次保存);
- 最后,用AI模型判断图像的放大倍数(10x、20x、40x),为后续AI理解“细胞大小对应的病理意义”提供元数据。
这一步就像从一段烹饪视频里,只截取“食材特写”,去掉主持人的手部动作和厨房背景——只留下最关键的“观察对象”。
处理“配套说明”——修复并提取文字
视频里的讲解是“文字原料”,但直接用语音转文字(ASR)会出错:比如把“serous carcinoma(浆液性癌)”转成“serious carcinoma(严重的癌)”,这对医学数据是致命的。
团队用“三层纠错法”解决这个问题:
- 关键词提取:用RAKE算法从ASR文本里抓关键短语(如“epithelial island”),去掉“啊”“嗯”等废话;
- 医学验证:查UMLS(统一医学语言系统,相当于医学术语字典),如果关键词不在字典里,就用病理专属拼写检查纠错;
- 大模型终审:让GPT-3.5(大语言模型)结合上下文改错——比如给模型看“医生讲解角化囊肿”的上下文,它能判断“hypersensium nitose”其实是“hypersensitivity pneumonitis(过敏性肺炎)”,还能提取出“医学描述(MED)”和“关注区域(ROI)”(比如“这里的上皮岛”对应ROI文本“epithelial island”)。
这一步好比让学生先自己整理课堂笔记,再找医学老师核对术语,最后请教授补充完整逻辑——确保文字描述既准确又贴合图像。
“图文配对”——让图像和文字精准对应
最后一步是让“图像”和“文字”一一对应:根据图像提取的时间点,找到同一时间段内的文字,再通过关键词匹配(比如图像关键词“psammoma bodies(砂粒体)”与文字里的“脑膜瘤常见砂粒体”匹配),确保每幅图像都有对应的医学描述和ROI描述。
至此,从YouTube视频中提取的QUILT数据集(80.2万组图文),再结合PubMed论文、LAION互联网数据、Twitter的OpenPath数据,最终组成了100万组图文的QUILT-1M——病理领域的“百万级”视觉-语言数据集。
有了优质数据,训练出的AI模型表现如何?
团队基于QUILT-1M微调CLIP模型(一种跨模态AI),得到QUILTNET,并在13个病理数据集(覆盖8个亚专科,如乳腺、皮肤、肾脏病理)上做了测试,结果超出预期。
零样本分类——AI“举一反三”能力更强
零样本分类指AI没见过某类病理图像,仅通过文字描述就能识别(类似医生第一次见罕见病,靠教科书描述诊断)。
在12个零样本任务中,QUILTNET几乎全面超越现有模型:
- 在PatchCamelyon(淋巴结转移检测)数据集上,QUILTNET准确率达67.9%,而传统CLIP仅58.6%、BiomedCLIP(生物医学专用模型)为64.6%;
- 在皮肤肿瘤亚型分类(SkinTumor)中,QUILTNET准确率51.5%,远超CLIP的13.9%和BiomedCLIP的37.0%。
这意味着,QUILTNET能凭文字描述识别更多罕见病理亚型——对临床中“样本少、种类多”的病理诊断极具价值。
线性探测——用少量数据就能“精通”
线性探测测试AI用少量标注数据提升性能的能力(类似医生只看10个病例,就能掌握某种疾病的诊断)。
结果显示:
- 在NCT-CRC(结直肠癌组织分类)数据集上,QUILTNET仅用1%的训练数据(约890张图),准确率就达87.3%,超过传统全监督模型的84.8%;
- 在SICAPv2(前列腺癌Gleason评分)数据集上,1%数据训练的QUILTNET准确率45.8%,远超CLIP的25.1%和BiomedCLIP的27.4%。
这一结果打破了“AI需要海量标注数据”的刻板印象——借助QUILT-1M的优质预训练,病理AI能更高效地利用临床稀缺的标注资源。
跨模态检索——图文“双向奔赴”更精准
跨模态检索测试“用文字找图像”或“用图像找文字”的能力(类似医生输入“有砂粒体的脑膜瘤”,AI能找出对应的切片图)。
在QUILT-1M的预留数据集和ARCH数据集上:
- “文字找图像”的Top1准确率(最匹配的第一个结果正确),QUILTNET达6.2%(ViT-B/16+PubmedBert配置),是CLIP(0.83%)的7倍多;
- “图像找文字”的Top200准确率,QUILTNET在ARCH数据集上达73.4%,远超BiomedCLIP的68.5%。
这对病理教学和科研意义重大——未来医生或学生想找特定病理特征的案例,只需输入文字,就能快速定位到对应的图像,大幅提升学习效率。
QUILT-1M的价值,远不止“多了一个数据集”——它为病理AI打开了三个全新的可能性。
让病理AI覆盖更多“小众亚专科”
此前病理AI多集中在肺癌、乳腺癌等常见领域,而像骨肿瘤、神经病理等小众亚专科,因数据少几乎无人问津。
QUILT-1M覆盖18个病理亚专科,其中包含大量罕见亚型数据(如Rosai-Dorfman病、角化囊肿),让AI首次能“触达”这些小众领域。
比如在骨肿瘤(Osteo)数据集上,QUILTNET准确率达54.0%,比CLIP(19.5%)提升近3倍——这意味着未来AI能为小众亚专科的医生提供更多辅助。
解锁“存量病理数据”的价值
医院里储存着大量“沉睡”的全切片图像(WSI),但因缺乏文字描述,无法用于AI训练。
QUILTNET的跨模态能力,能为这些WSI自动生成文字描述(如“此区域可见淋巴细胞浸润”),让存量数据变成“可用资源”——相当于为病理科激活了一座“数据金矿”。
推动“精准病理”更近一步
传统病理诊断依赖医生经验,同一病例可能有不同判断。
QUILT-1M的文字描述来自资深医生的讲解,包含“细胞形态、结构特征、诊断依据”等细节,训练出的AI能学习这些“专家逻辑”,辅助医生做出更一致的诊断。
比如在乳腺导管癌(Databiox)分级中,QUILTNET准确率达59.8%,接近资深病理医生的水平——这为基层医院或资源匮乏地区提供了“专家级”的辅助工具。
QUILT-1M并非完美——它的视频多来自西方英语频道,可能存在地域偏差;ASR对口音较重的讲解仍有纠错盲区。
但它的意义在于,证明了“非传统医疗数据(如教育视频)”的价值,为病理数据收集提供了新范式。
未来,随着更多多语言、多中心数据的加入,病理AI或许能真正实现“无论在哪家医院,都能获得一致的专家级诊断建议”——而这一切的起点,正是QUILT-1M所打破的“数据荒”困局。
参考资料
本文核心技术来自华盛顿大学与艾伦人工智能研究所团队2023年发表于arXiv的论文《Quilt-1M: One Million Image-Text Pairs for Histopathology》(论文编号:arXiv:2306.11207v4)
数据集与代码请移步Quilt-1M官网:https://quilt-llava.github.io/
