我分析了 10,000 个 SQL 查询。这里
我分析了 10,000 个 SQL 查询。这里
摘要:本文分析了我分析了 10,000 个 SQL 查询。这里的核心概念与应用实践。作者详细分析了相关技术细节,并结合实际案例展示了最佳操作流程,帮助读者提升工程效率与解决复杂问题的能力。

我正在为一家医疗保健公司提供咨询。他们的报告系统“很慢”。这就是他们所知道的一切。用户抱怨道。 IT 将责任归咎于硬件。硬件供应商建议升级。
新服务器价值 150,000 美元。这就是建议的解决方案。
我的工作是验证他们确实需要它。
我要求一件事:“给我 90 天的查询日志。”
他们交付了 12 个月。 10,247 个唯一查询。包含时间戳、执行时间、行数、CPU 使用率、I/O 统计信息 — 一切。
我把它全部导入到数据库中(讽刺的是,使用SQL来分析SQL)。然后我开始寻找模式。
第一个洞察力像卡车一样击中了我:
前 50 个最慢的查询(占总数的 0.5%)消耗了总服务器资源的 41%。
并不是因为他们经常跑步。但因为它们效率低下。
一个查询扫描了 1.45 亿行并返回 12 个结果。另一个连接了 8 个表,没有使用单个 WHERE 子句。第三个在 WHERE 子句中进行了函数调用,该函数调用阻止了在 5000 万行表上使用索引。
这些并不是复杂的分析查询。它们是例行报告。开发人员每天都会写的那种。
他们都有共同的模式。
让我向您展示我最常发现的七种模式,更如何解决它们。

示例:
我发现这个查询每天运行 200 多次:
SELECT * FROM Orders
WHERE CustomerID = 12345
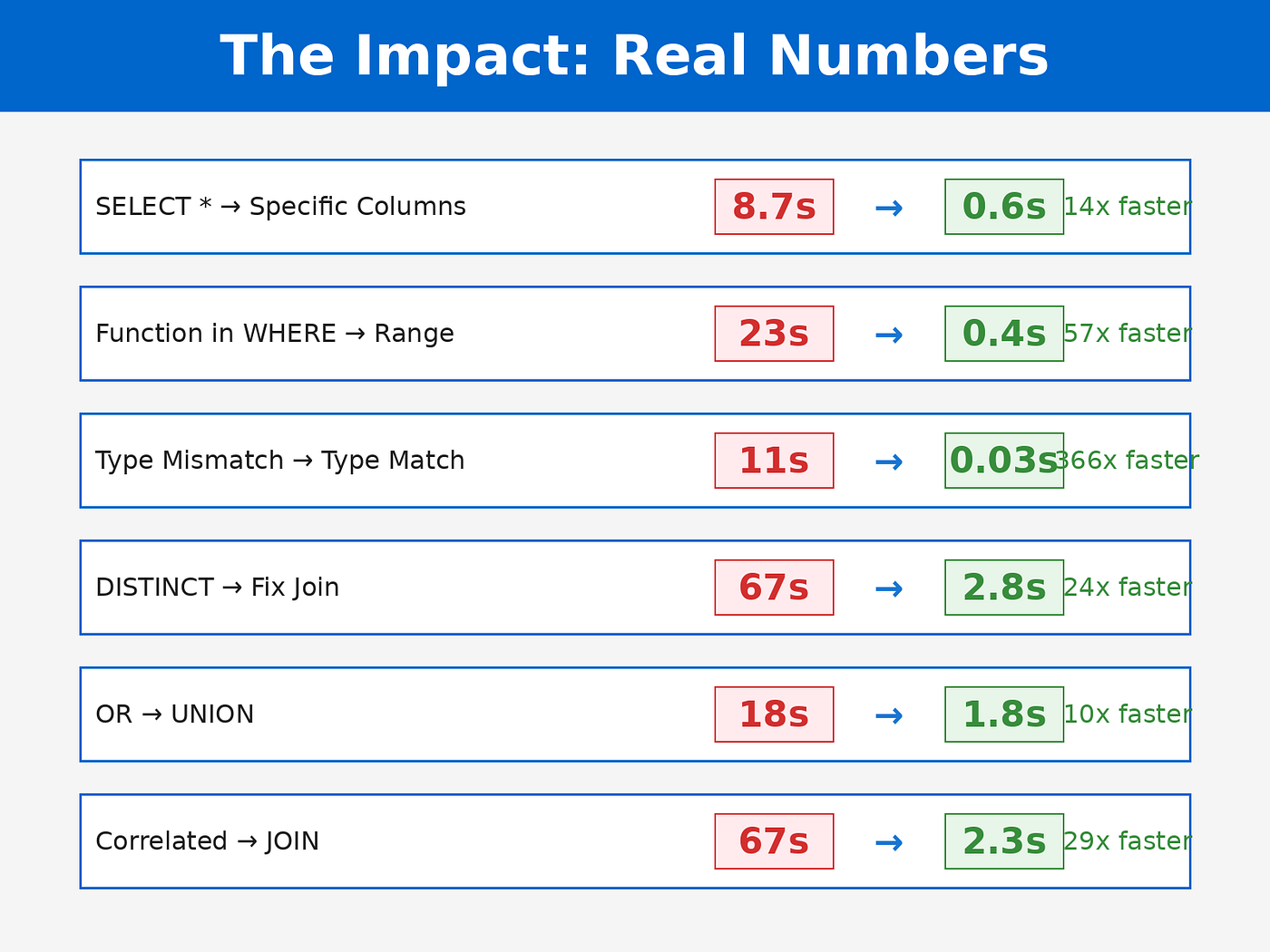
执行时间:8.7秒。
“这有什么问题吗?”你可能会问。 “它使用 WHERE 子句。它已被过滤。”
这是错误的:
Orders 表有 47 列。该应用程序仅显示其中 5 个:OrderID、OrderDate、TotalAmount、Status 和 ShipDate。
但 SQL 正在检索所有 47 列。包括:
- CustomerNotes(NVARCHAR(MAX) — 每行平均 2KB)
- ShippingInstructions(NVARCHAR(MAX) — 每行平均 1.5KB)
- 内部注释(NVARCHAR(MAX) — 每行平均 3KB)
对于拥有 500 个订单的客户,即:
- 需要 5 列 = ~500 字节 × 500 行 = 250KB
- 返回 47 列 = ~7KB × 500 行 = 3.5MB
传输的数据量比所需数据多 14 倍。
修复:
SELECT OrderID, OrderDate, TotalAmount, Status, ShipDate
FROM Orders
WHERE CustomerID = 12345
执行时间:0.6秒。
但这部分让我大吃一惊:
当我深入研究应用程序代码时,我发现有 89 个使用 SELECT * 的查询。
我重构它们以仅选择需要的列。
整个应用程序的总体影响:
- 平均查询时间:4.2s→0.8s
- 数据库CPU使用率:-37%
- 网络带宽:-52%
- 应用程序内存使用:-41%
一种模式。 89 个实例。影响巨大。
为什么开发人员这样做:
“SELECT * 写起来更快。”
是的。写入速度快 2 秒。执行速度慢 8 秒。每天200次。每天一个查询会浪费 26 分钟的服务器时间。
如何在数据库中检测它:
针对您的查询日志运行此命令:
SELECT
query_text,
execution_count,
avg_elapsed_time_ms,
total_elapsed_time_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
WHERE query_text LIKE '%SELECT *%'
AND query_text NOT LIKE '%sys.%'
ORDER BY total_elapsed_time_ms DESC
你会对你的发现感到震惊。
规则:
切勿在生产代码中 SELECT *。曾经。唯一的例外是 SSMS 中的临时分析。
故事:
开发人员需要查找当年的所有订单。很简单,对吧?
这是他们写的:
SELECT OrderID, CustomerID, OrderDate, TotalAmount
FROM Orders
WHERE YEAR(OrderDate) = 2024
看起来很合理。执行时间:850 万行执行时间为 23 秒。
问题?
Orders 表在 OrderDate 上有一个完美的索引。一个漂亮的、优化的、覆盖的索引。
但 SQL Server 无法使用它。
为什么?因为 WHERE 子句将函数 (YEAR) 应用于 OrderDate 列。
当您将列包装在函数中时,SQL Server 必须:
- 读取每一行
- 将函数应用于每个 OrderDate 值
3。检查是否等于2024
4。返回匹配行
850 万次函数调用。一行一行。无索引。
这称为“不可控制”查询。 (SARG = 搜索 ARGument — 索引无法搜索参数,因为它包含在函数中。)
修复:
SELECT OrderID, CustomerID, OrderDate, TotalAmount
FROM Orders
WHERE OrderDate >= '2024-01-01'
AND OrderDate < '2025-01-01'
现在SQL Server可以使用索引了。它确切地知道哪些索引页包含该范围内的日期。
执行时间:0.4秒。
相同的结果。速度提高 57 倍。
其他常见功能错误:
我反复发现这些模式:
WHERE LOWER(LastName) = 'smith'
WHERE LastName = 'Smith'
WHERE SUBSTRING(ProductCode, 1, 3) = 'ABC'
WHERE ProductCode LIKE 'ABC%'
WHERE DATEPART(MONTH, OrderDate) = 6
WHERE OrderDate >= '2024-06-01' AND OrderDate < '2024-07-01'
现实世界的影响:
我工作过的一家公司有“客户搜索”功能。输入名称,获取结果。
查询:
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE LOWER(LastName) = LOWER(@SearchTerm)
350,000 名客户。全表扫描。每次搜索需要 4 至 6 秒。
用户抱怨该系统“无法使用”。
修复?删除 LOWER 功能。设置不区分大小写的排序规则。
搜索时间:0.08秒。用户立即停止抱怨。
如何在代码中找到这些:
在您的代码库中搜索:
年份在哪里(月份(哪里日期部分(在哪里转换(在哪里演员(哪里较低(上面的地方(哪里子串(
每一个都是潜在的索引杀手。
规则:
切勿将函数应用于 WHERE 子句中的索引列。将函数移至比较的另一侧。

模式 2:函数终止索引
这个是偷偷摸摸的。
我发现一个看起来很完美的查询:
SELECT ProductID, ProductName, Price
FROM Products
WHERE ProductCode = '12345'
产品代码索引?查看。简单的 WHERE 子句?查看。没有功能吗?查看。
执行时间:200 万行执行时间为 11 秒。
出了什么问题?
ProductCode 列定义为 INT。查询将其与字符串进行比较:“12345”
SQL Server 必须将每个 INT 值隐式转换为 VARCHAR 才能执行比较。
200 万次转化。每次运行查询时。
执行计划显示: CONVERT_IMPLICIT(VARCHAR, ProductCode)
修复:
SELECT ProductID, ProductName, Price
FROM Products
WHERE ProductCode = 12345
执行时间:0.03秒。
快 366 倍。通过删除两个字符。
最常见的隐式转换错误:
此模式在查询日志中出现了 47 次:
WHERE OrderID IN ('100', '101', '102', '103', '104')
每个值都会被转换。对于具有 50 多个值的 IN 子句,性能影响是毁灭性的。
另一个偷偷摸摸的:
SELECT *
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
看起来不错,对吧?
但 Orders.CustomerID 是 INT。 Customers.CustomerID 为 BIGINT。
SQL Server 在加入之前将每个 Orders.CustomerID 转换为 BIGINT。 800 万行。
查询时间:34秒。
将 Orders.CustomerID 更改为 BIGINT(匹配客户表)。
查询时间:1.2秒。
如何检测隐式转换:
1。查看执行计划
2. 搜索“CONVERT_IMPLICIT”警告
3。检查SSMS中是否有黄色感叹号
或者运行这个查询:
SELECT
query_text,
execution_count,
avg_elapsed_time_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
WHERE qp.query_plan LIKE '%CONVERT_IMPLICIT%'
ORDER BY avg_elapsed_time_ms DESC
开发者故事:
一位初级开发人员曾经告诉我:“但是它有效!为什么我是否使用引号很重要?”
我向他展示了执行计划。 200 万次转化。
“哦,”他说。
然后我向他展示了服务器 CPU 图表。查询期间 CPU 使用率为 87%。
“哦,”他说。
类型匹配不是可选的。这是必要的。
规则:
始终完全匹配数据类型。 INT 到 INT。 VARCHAR 到 VARCHAR。 BIGINT 到 BIGINT。没有例外。
危险信号查询:
SELECT DISTINCT
c.CustomerName,
o.OrderDate,
o.TotalAmount
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID
JOIN OrderDetails od ON o.OrderID = od.OrderID
WHERE o.OrderDate >=
执行时间:42秒。
我经常看到这种模式。 DISTINCT 用于“修复”重复行,但不首先了解为什么会出现重复。
使用 DISTINCT 时会发生以下情况:
- SQL Server执行整个查询
- 检索所有行(包括重复行)
- 对它们进行排序以识别重复项
- 删除重复项
- 返回结果
对于此查询:
- 初始结果集:240 万行
- DISTINCT 之后:180,000 行
- 检索并丢弃 222 万行
真正的问题:
JOIN 到 OrderDetails 正在创建重复项。每个订单都有多个订单项,因此每个订单每个订单项都会出现一次。
问题:
为什么要加入 OrderDetails? SELECT 子句没有使用其中的任何列。
事实证明,开发人员从另一个报告中复制粘贴了查询,却忘记删除不必要的 JOIN。
修复:
SELECT
c.CustomerName,
o.OrderDate,
o.TotalAmount
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID
WHERE o.OrderDate >=
执行时间:0.9秒。
快 47 倍。通过删除不必要的表。
另一个独特的恐怖故事:
我发现了这个宝石:
SELECT DISTINCT ProductID
FROM Products
主键上的 DISTINCT。根据定义,主键已经是唯一的。
但开发人员并不确定,因此他们添加了“DISTINCT”,“只是为了安全起见”。
性能成本? SQL Server 必须对 500,000 行进行不必要的排序。
当实际需要 DISTINCT 时:
有时你确实需要 DISTINCT。但这应该是一个有意识的选择,而不是创可贴。
SELECT DISTINCT Category
FROM Products
-- Legitimate use: Deduplication after UNION
SELECT ProductID FROM ActiveProducts
UNION ALL
SELECT ProductID FROM ArchivedProducts
-- Then use DISTINCT if duplicates are expected
如何审核您的独特使用情况:
- 查找代码中的每个 DISTINCT
- 对于每一项,问:“为什么会有重复项?”
- 修复根本原因,而不是用 DISTINCT 隐藏它
现实世界的例子:
报告运行时间为 3 分钟。使用过的不同。
我删除了 DISTINCT。查询中断(出现重复)。
追踪重复项是由于错误地连接了多对多关系。
修复了 JOIN 逻辑。删除了 DISTINCT。查询时间:8秒。
规则:
DISTINCT 是一种症状,而不是解决方案。查询中的每个 DISTINCT 都应该有记录的原因。如果您无法解释为什么需要它,那么您就不了解您的数据模型。
查询:
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE LastName = 'Smith'
OR FirstName = 'John'
OR Email LIKE '%smith%'
执行时间:800,000 行 18 秒。
“但是我在所有三列上都有索引!”开发商提出抗议。
是的。但 SQL Server 无法有效地使用其中任何一个。
为什么 OR 会影响性能:
当您使用 OR 时,SQL Server 必须:
- 扫描 LastName = ‘Smith’(可以使用索引)
- 扫描 FirstName = ‘John’(可以使用不同的索引)
- 扫描电子邮件 LIKE ‘%smith%’(不能使用索引 – 前导通配符)
- 合并所有结果
- 删除重复项
三个独立的操作。然后合并。然后去重。
执行计划真相:
查询计划显示了三个索引查找(很好!),然后是一个串联操作(组合结果)和一个排序 + 不同操作(删除重复项)。
总读取次数:124,000 页总 CPU 时间:15,700 毫秒
修复选项 1:拆分为多个查询
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE LastName = 'Smith'
UNION
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE FirstName = 'John'
UNION
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE Email LIKE '%smith%'
UNION 自动处理重复数据删除。
执行时间:4.2秒。
修复选项 2:重新思考逻辑
通常,OR 子句表明存在业务逻辑问题。
在本例中,要求是:“查找名为 John Smith 的客户或电子邮件中包含 smith 的任何人。”
真正的解决方案:
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE FirstName = 'John' AND LastName = 'Smith'
UNION
SELECT CustomerID, FirstName, LastName, Email
FROM Customers
WHERE Email LIKE '%smith%'
AND NOT (FirstName = 'John' AND LastName = 'Smith')
执行时间:1.8秒。
我见过的最糟糕的:
WHERE CustomerID = 1
OR CustomerID = 2
OR CustomerID = 3
OR CustomerID = 4
... (continuing for 200 values)
OR CustomerID = 200
200 个 OR 子句。开发商不知道IN。
应该是:
WHERE CustomerID IN (1, 2, 3, 4, ..., 200)
具有不同列模式的 OR:
这是特别糟糕的:
WHERE Status = 'Active'
OR LastOrderDate > '2024-01-01'
OR TotalSpent > 10000
三个不同的列。三种不同的条件。 SQL Server 必须扫描整个表。
更好的方法:
规则:
OR 子句迫使 SQL Server 执行更多工作。谨慎使用它们。考虑 UNION、IN,或者重新思考您的业务逻辑。
看似无辜的查询:
SELECT
c.CustomerID,
c.CustomerName,
(SELECT COUNT(*)
FROM Orders o
WHERE o.CustomerID = c.CustomerID) AS OrderCount,
(SELECT MAX(OrderDate)
FROM Orders o
WHERE o.CustomerID = c.CustomerID) AS LastOrderDate,
(SELECT SUM(TotalAmount)
FROM Orders o
WHERE o.CustomerID = c.CustomerID) AS TotalSpent
FROM Customers c
WHERE c.Status = 'Active'
执行时间:150,000 个活跃客户需要 67 秒。
看起来很干净,对吧?有组织的。易于阅读。
隐藏的问题:
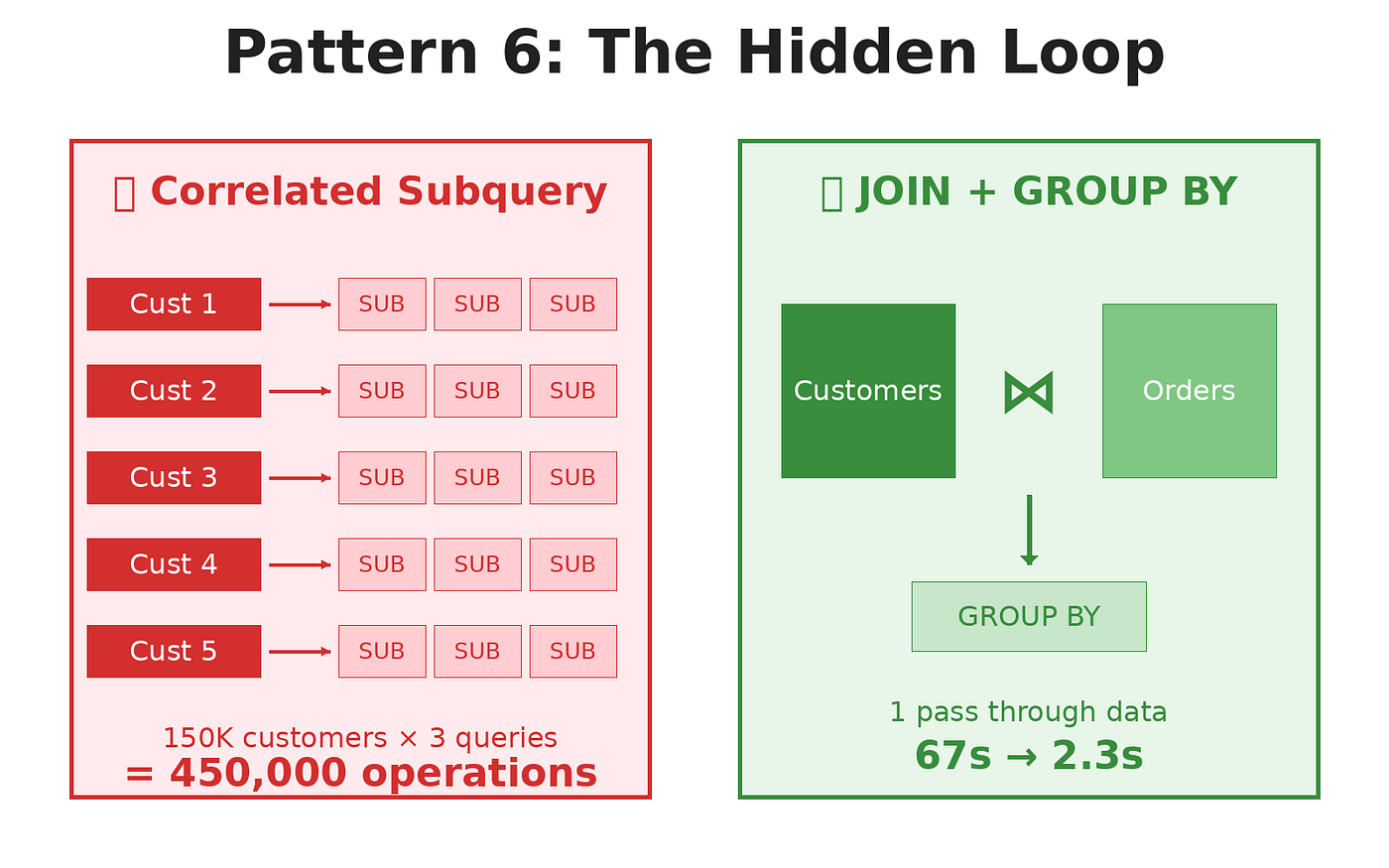
此查询为每个客户运行 3 个子查询。
150,000 个客户 × 3 个子查询 = 针对 Orders 表的 450,000 个查询。
每个子查询:
- 找到客户的订单
- 执行聚合
- 返回一个值
当您认为自己正在运行一个查询时,会执行 450,000 次单独的操作。
执行计划:
我把这个给开发商看了。执行计划有一个嵌套循环图标。
“什么是嵌套循环?”他问道。
“看到估计行数:150,000 吗?还有那个嵌套循环运算符?您的子查询运行了 150,000 次。”
他的脸色变得苍白。
修复:
SELECT
c.CustomerID,
c.CustomerName,
COUNT(o.OrderID) AS OrderCount,
MAX(o.OrderDate) AS LastOrderDate,
SUM(o.TotalAmount) AS TotalSpent
FROM Customers c
LEFT JOIN Orders o ON c.CustomerID = o.CustomerID
WHERE c.Status =
GROUP BY c.CustomerID, c.CustomerName
执行时间:2.3秒。
快 29 倍。
一次传递订单而不是 150,000 次传递。
为什么开发人员编写相关子查询:
“这样更容易思考。”
我得到它。相关子查询读起来像英语:
- “对于该客户,计算他们的订单”
- “对于该客户,找到他们的最后订单日期”
但 SQL 的执行方式与英语不同。它以集合的形式执行。
另一个例子:
SELECT
ProductID,
ProductName,
Price,
(SELECT AVG(Rating)
FROM Reviews r
WHERE r.ProductID = p.ProductID) AS AvgRating
FROM Products p
这将为每个产品运行一次 AVG 子查询。
更好的:
SELECT
p.ProductID,
p.ProductName,
p.Price,
AVG(r.Rating) AS AvgRating
FROM Products p
LEFT JOIN Reviews r ON p.ProductID = r.ProductID
GROUP BY p.ProductID, p.ProductName, p.Price
极端情况:
我曾经发现一个查询在 SELECT 子句中有 8 个相关子查询。
运行时间:6分43秒。
重构为 JOIN:4.8 秒。
快 84 倍。
如何发现这些:
寻找:
- SELECT 子句中的子查询
- 引用外部查询表的子查询(相关)
- 执行计划中的嵌套循环运算符具有高估计行数
规则:
SELECT 子句中的相关子查询是变相的循环。而是使用 JOIN 和 GROUP BY。
模式 6:隐藏循环
最终Boss模式:
SELECT
o.OrderID,
o.OrderDate,
c.CustomerName,
p.ProductName
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
JOIN OrderDetails od ON o.OrderID = od.OrderID
JOIN Products p ON od.ProductID = p.ProductID
没有 WHERE 子句。完全没有。
执行时间:4分18秒。
“但我需要所有数据!”开发商说。
你觉得吗?
我检查了申请。此查询提供了一个每页显示 50 行的报告。带分页。
该报告正在检索 850 万行以显示 50 行。
浪费了 8,499,950 行。
修复:
SELECT
o.OrderID,
o.OrderDate,
c.CustomerName,
p.ProductName
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
JOIN OrderDetails od ON o.OrderID = od.OrderID
JOIN Products p ON od.ProductID = p.ProductID
WHERE o.OrderDate >= DATEADD(MONTH, -3, GETDATE())
ORDER BY o.OrderDate DESC
OFFSET 0 ROWS FETCH NEXT 50 ROWS ONLY
执行时间:0.8秒。
开发者的回应:“哦。我不知道你能做到这一点。”
模式 7A:弱 WHERE 子句
比没有 WHERE 子句更糟糕的是 WHERE 子句实际上并不过滤:
WHERE 1=1
我在 23 个查询中找到了这一点。这是动态构建查询的一个技巧,但开发人员忘记在 1=1 之后添加实际条件。
模式 7B:日期范围过于宽泛
WHERE OrderDate >= '1900-01-01'
从技术上讲,这是一个 WHERE 子句。实际上没用。
数据库中最旧的订单? 2018。这没有过滤任何东西。
模式 7C:状态字段始终为 True
WHERE IsDeleted = 0
听起来不错,对吧?过滤掉已删除的记录。
除了这个数据库之外,记录从未被真正删除。对于所有 1200 万行,IsDeleted 始终为 0。
IsDeleted 上的索引?无用。 SQL Server 无论如何都会扫描整个表,因为选择性很差。
现实世界的影响:
仪表板显示“所有客户”。其中 230 万。每次有人打开页面时都会加载。
我添加了:WHERE LastOrderDate >= DATEADD(YEAR, -2, GETDATE())
事实证明,过去 2 年只有 180,000 名顾客下单。其余的人都不活跃。
仪表板加载时间:23 秒 → 1.2 秒。
企业了解到了一些事情:他们有 210 万不活跃的客户一直被他们忽视。
特异性层次结构:
从最好到最差:
- 主键精确匹配:
WHERE OrderID = 12345⚡ - 索引日期范围:
WHERE OrderDate >= '2024-01-01'✅ - 等于索引列:
WHERE Status = 'Active'✅ - 具有很少值的 IN 子句:
WHERE CategoryID IN (1,2,3)⚠️ - 喜欢主角:
WHERE LastName LIKE 'Smi%'⚠️ - 广泛范围:
WHERE OrderDate >= '1900-01-01'❌ - LIKE 带前导通配符:
WHERE Email LIKE '%gmail%'❌ - 根本没有 WHERE 子句 ❌❌
规则:
总是问:“我实际需要的最少数据是多少?”然后编写一个返回该值的 WHERE 子句。不再。
影响:真实数字
让我向您展示这些模式如何组合到一个系统中。
情况:
医疗保健公司。患者记录数据库。主仪表板加载需要 2-3 分钟。有时完全超时。
用户讨厌它。 IT 将责任归咎于硬件。管理层准备花费 20 万美元购买新服务器。
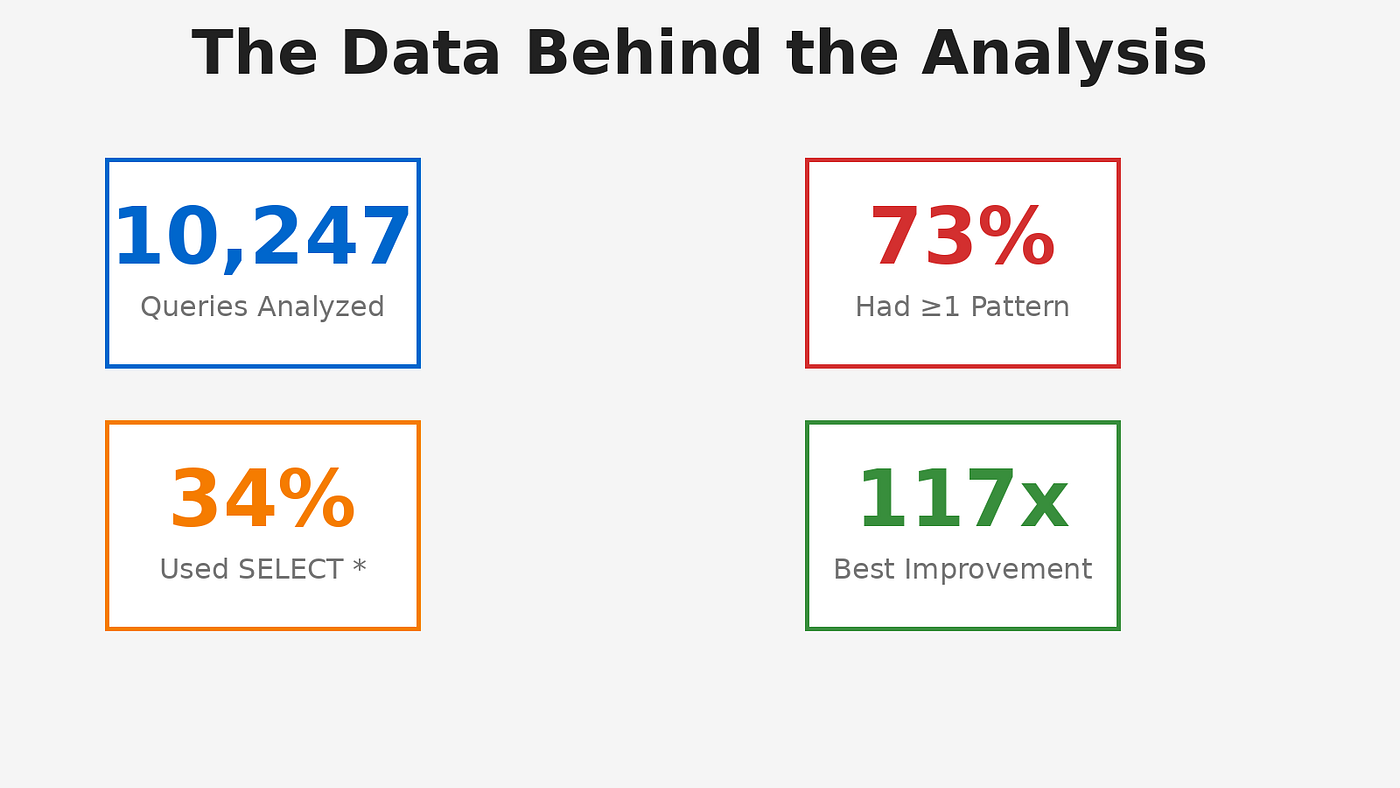
我得到了查询日志。分析了 847 个查询。这是我发现的:
查询 1:患者搜索
SELECT * FROM Patients
WHERE YEAR(DateOfBirth) = 1980
OR LOWER(LastName) LIKE '%smith%'
- 模式 1:选择 * ✓
- 模式 2:YEAR() 函数 ✓
- 模式 5:OR 子句 ✓
修复:特定列、日期范围、拆分 OR 到 UNION 结果:34 秒 → 1.2 秒
查询 2:预约仪表板
SELECT
p.PatientID,
p.PatientName,
(SELECT COUNT(*) FROM Appointments WHERE PatientID = p.PatientID) AS ApptCount
FROM Patients p
- 模式 6:相关子查询 ✓
修复:使用 GROUP BY JOIN 结果:89s → 3.1s
查询3:账单报告
SELECT DISTINCT
i.InvoiceID,
i.InvoiceDate,
i.Amount
FROM Invoices i
JOIN InvoiceItems ii ON i.InvoiceID = ii.InvoiceID
JOIN Services s ON ii.ServiceID = s.ServiceID
- 模式 4:独特如创可贴 ✓
修复:意识到服务连接是不必要的,将其删除结果:67s → 2.8s
总影响:
之前:仪表板总加载时间为 28 分钟 之后:47 秒
快 60 倍。零硬件升级。
购买 20 万美元的服务器?取消。
我的咨询费? 15,000 美元。
他们通过修复查询而不是购买硬件节省了 18.5 万美元。
您不需要访问 10,000 个查询来提高性能。这是我现在对每个数据库运行的实际审计:
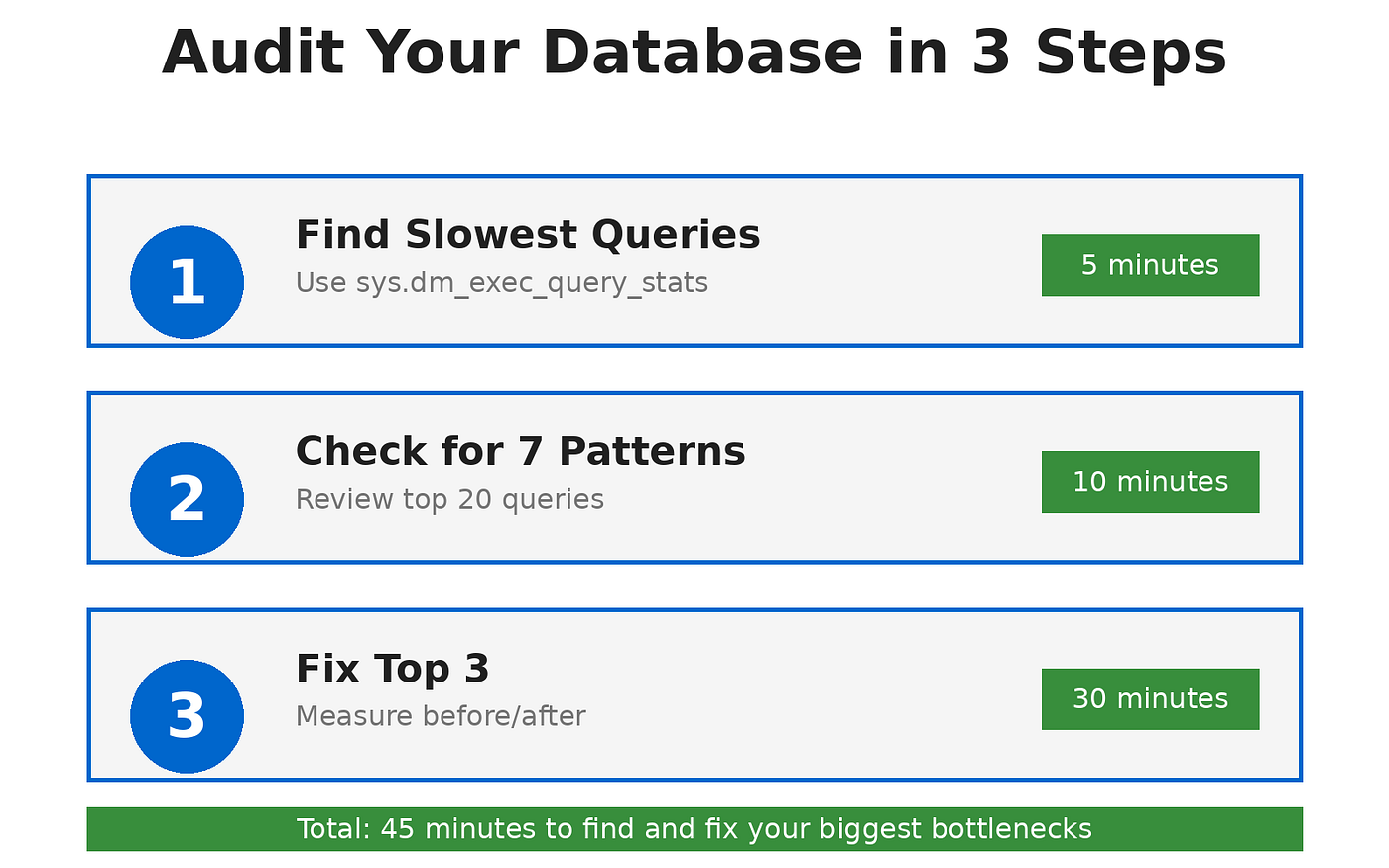
第 1 步:找到最慢的查询(5 分钟)
SELECT TOP 20
qt.text AS QueryText,
qs.execution_count AS ExecutionCount,
qs.total_elapsed_time / 1000000.0 AS TotalElapsedSeconds,
qs.total_elapsed_time / qs.execution_count / 1000.0 AS AvgElapsedMS,
qs.total_logical_reads / qs.execution_count AS AvgLogicalReads,
qs.creation_time AS CachedAt,
qs.last_execution_time AS LastRun
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY qs.total_elapsed_time DESC
第 2 步:检查每个查询是否有 7 种模式(10 分钟)
对于前 20 个最慢的查询,请查找:
- [ ] 选择 *
- [ ] 索引列上的函数
- [ ] 隐式转换(检查执行计划)
- [ ] 没有明确原因的独特
- [ ] OR 子句
- [ ] SELECT 中的相关子查询
- [ ] 缺少或弱 WHERE 子句
第 3 步:修复前 3 项(30 分钟)
不要试图解决所有问题。修复前 3 个资源消耗者。
使用此优先顺序:
1。每天运行100次以上的查询(高频)
2. 查询时间超过 10 秒(高影响)
3。使用100,000+逻辑读取的查询(高I/O)
第 4 步:衡量影响
修复前,记录:
- 执行时间
- 逻辑读取
- CPU时间
修复后,记录相同的指标。
计算改进百分比。
记录下来。将其展示给您的团队/经理。
80/20 规则:
在对 10,000 个查询的分析中,我发现:
- 20% 的查询消耗了 82% 的资源
- 前 50 个查询 (0.5%) 消耗了 41% 的资源
修复最严重的违规者。您将看到整个系统范围内的巨大改进。
只需 3 个步骤即可审核您的数据库
在会议上并向客户团队展示此分析后,总是会出现以下问题:
问:“过早优化不是不好吗?”
答:是的。但避免已知的反模式并不是不成熟的优化。这是基本的手艺。
不要花 3 天时间将查询时间缩短 0.01 秒。但也不要使用 SELECT * 因为“它有效”。
问:“我们的 ORM 生成 SQL。我们无法控制它。”
答:ORM 是工具,而不是借口。
实体框架、NHibernate 和其他 ORM 都有方法在需要时编写特定查询。使用 .Select() 指定列。策略性地使用 .include()。为复杂查询编写原始 SQL。
你的 ORM 生成了 SELECT *?覆盖它。
问:“DBA 应该处理性能问题,而不是开发人员。”
答:DBA 可以添加索引并调整服务器。但他们无法修复应用程序代码中的错误查询模式。
绩效是一项共同的责任。写出好的查询。让 DBA 优化基础架构。
问:“这些优化是微观优化。它们在规模上并不重要。”
答:我有数据证明事实并非如此。
每天运行 1000 次、耗时 0.5 秒的查询每天会浪费 8.3 分钟的服务器时间。
每天运行 100 次的 5 秒查询也会浪费 8.3 分钟。
但解决这两个问题后,您每天可以节省 16.6 分钟。一个多月了? 8.3 小时的服务器时间。
将其扩展到 50 个查询,您可以节省数天的计算时间。
问:“查询优化器不会自动修复这些问题吗?”
答:查询优化器很聪明,但它并不神奇。
它可以选择索引和连接顺序。它不能:
- 删除不需要的 SELECT * 列
- 从 WHERE 子句中重写函数
- 将 OR 更改为 UNION
- 修复隐式类型转换
你必须写出好的 SQL。优化器让优秀的 SQL 变得更加出色。
还记得那位开发人员 47 秒的查询花费了 240 万美元的交易吗?
他并没有因为一次缓慢的查询而被解雇。他因为不关心学习而被解雇。
当问题被发现后,管理层要求他解决这个问题。他说:“数据库很慢。不是我的问题。”
六个月后,我在一次会议上遇到了一位名叫莎拉的开发人员。她给我讲了一个故事。
她编写了一个导致生产服务器瘫痪的查询。全面停电。减少了 3,000 个用户。 CTO 尖叫。
但她没有找借口,而是问道:“为什么我的查询如此糟糕?我需要学习什么?”
她的经理送她参加 SQL 性能课程。她花了一个月的时间学习查询优化。阅读执行计划。了解索引。
现在?她是团队中负责数据库性能的关键人物。她在将每个查询投入生产之前对其进行审查。她指导初级开发人员。
这两个开发人员之间的区别不在于技能。这是态度。
第一个开发人员将缓慢的查询视为其他人的问题。
莎拉认为这是她需要填补的知识空白。
这就是我希望你做的事情:
第 1 周:审核
- 运行慢查询查找器脚本
- 确定最慢的 10 个查询
- 根据 7 种模式检查每一种
- 记录你发现的内容
第 2 周:修复前 3 名
- 选择 3 个最严重的违规者
- 使用本文中的模式修复它们
- 测量性能之前/之后
- 记录改进
第 3 周:分享知识
- 向您的团队展示结果
- 创建代码审查的“查询清单”
- 将执行计划审查添加到您的流程中
第 4 周:监控
- 为超过 5 秒的查询设置警报
- 每周查看新查询
- 庆祝胜利
不要试图立即解决所有问题。
从最糟糕的查询开始。修复它。测量一下。分享一下。
然后转到下一个。
分析了 10,000 个查询后,我发现了以下元模式:
优秀的开发人员编写有效的 SQL。优秀的开发人员编写的 SQL 可以高效运行。
区别不是天赋。这是意识。
意识到 SELECT * 浪费资源。意识到 WHERE 子句中的功能会杀死索引。意识到 DISTINCT 可能隐藏着更深层次的问题。
本文中的每种模式都是可以预防的。不是通过复杂的优化技术,而是通过对 SQL 实际执行方式的基本了解。
查询在 47 秒内运行?
它有模式 1(SELECT *)、模式 2(YEAR 函数)和模式 7(弱 WHERE 子句)。
修复了所有三个:47 秒 → 0.4 秒。
快 117 倍。相同的数据。相同的结果。
唯一的区别是什么?了解 SQL Server 实际上在做什么。
两周前,我收到了一封来自一位名叫 Marcus 的开发人员的电子邮件。
“我读了您对 10,000 个查询的分析。我在我们的数据库上运行了审核脚本。发现了 23 个符合您的模式的查询。修复了前 5 个查询。”
他附上了一张截图。
前:
- 查询 1:34 秒
- 查询 2:67 秒
- 查询 3:23 秒
- 查询 4:89 秒
- 查询 5:41 秒
- 总计:254 秒
后:
- 查询 1:1.2 秒
- 查询 2:2.8 秒
- 查询 3:0.9 秒
- 查询 4:3.1 秒
- 查询 5:1.4 秒
- 总计:9.4 秒
全面提速 27 倍。
他的经理注意到了。用户注意到了。原本“无法解决的硬件问题”的性能问题突然消失了。
马库斯晋升为高级开发人员。
并不是因为他是 SQL 天才。但因为他花时间去了解到底是什么让事情变慢了,并系统地修复了它。
这就是模式的力量。
您不需要分析 10,000 个查询。您只需要认识到影响绩效的七种模式并避免它们即可。
分析背后的数据
目前数据库中最慢的查询是什么?运行审核脚本并让我知道您在评论中发现的内容。
如果此分析帮助您识别了您不知道存在的性能问题,请与其他正在与缓慢 SQL 作斗争的开发人员分享。我们都去过那里。
- 我分析了 10,000 个 SQL 查询。这里
